【C++ STL学习之五】容器set和multiset
一、set和multiset基础
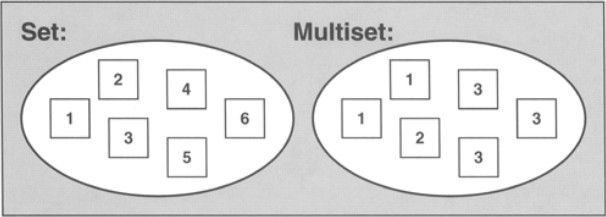
set和multiset会根据特定的排序准则,自动将元素进行排序。不同的是后者允许元素重复而前者不允许。
需要包含头文件:
#include <set>
set和multiset都是定义在std空间里的类模板:
template<class _Kty,
class _Pr = less<_Kty>,
class _Alloc = allocator<_Kty> >
class set
template<class _Kty, class _Pr = less<_Kty>, class _Alloc = allocator<_Kty> > class multiset
只要是可复赋值、可拷贝、可以根据某个排序准则进行比较的型别都可以成为它们的元素。第二个参数用来定义排序准则。缺省准则less是一个仿函数,以operator<对元素进行比较。
所谓排序准则,必须定义strict weak ordering,其意义如下:
1、必须使反对称的。
对operator<而言,如果x<y为真,则y<x为假。
2、必须使可传递的。
对operator<而言,如果x<y为真,且y<z为真,则x<z为真。
3、必须是非自反的。
对operator<而言,x<x永远为假。
因为上面的这些特性,排序准则可以用于相等性检验,就是说,如果两个元素都不小于对方,则它们相等。
二、set和multiset的功能
和所有关联式容器类似,通常使用平衡二叉树完成。事实上,set和multiset通常以红黑树实作而成。
自动排序的优点是使得搜寻元素时具有良好的性能,具有对数时间复杂度。但是造成的一个缺点就是:
不能直接改变元素值。因为这样会打乱原有的顺序。
改变元素值的方法是:先删除旧元素,再插入新元素。
存取元素只能通过迭代器,从迭代器的角度看,元素值是常数。
三、操作函数
构造函数和析构函数

set的形式可以是:

有两种方式可以定义排序准则:
1、以template参数定义:
set<int,greater<int>> col1;此时,排序准则就是型别的一部分。型别系统确保只有排序准则相同的容器才能被合并。
程序实例:
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s1;
set<int,greater<int> > s2;
for (int i = 1;i < 6;++i)
{
s1.insert(i);
s2.insert(i);
}
if(s1 == s2)
cout << "c1 equals c2 !" << endl;
else
cout << "c1 not equals c2 !" << endl;
}程序运行会报错。但是如果把s1的排序准则也指定为greater<int>便运行成功。
2、以构造函数参数定义。
这种情况下,同一个型别可以运用不同的排序准则,而排序准则的初始值或状态也可以不同。如果执行期才获得排序准则,而且需要用到不同的排序准则,这种方式可以派上用场。
程序实例:
#include <iostream>
#include "print.hpp"
#include <set>
using namespace std;
template <class T>
class RuntimeCmp{
public:
enum cmp_mode{normal,reverse};
private:
cmp_mode mode;
public:
RuntimeCmp(cmp_mode m = normal):mode(m){}
bool operator()(const T &t1,const T &t2)
{
return mode == normal ? t1 < t2 : t2 < t1;
}
bool operator==(const RuntimeCmp &rc)
{
return mode == rc.mode;
}
};
typedef set<int,RuntimeCmp<int> > IntSet;
void fill(IntSet& set);
int main()
{
IntSet set1;
fill(set1);
PRINT_ELEMENTS(set1,"set1:");
RuntimeCmp<int> reverse_order(RuntimeCmp<int>::reverse);
IntSet set2(reverse_order);
fill(set2);
PRINT_ELEMENTS(set2,"set2:");
set1 = set2;//assignment:OK
set1.insert(3);
PRINT_ELEMENTS(set1,"set1:");
if(set1.value_comp() == set2.value_comp())//value_comp Returns the comparison object associated with the container
cout << "set1 and set2 have the same sorting criterion" << endl;
else
cout << "set1 and set2 have the different sorting criterion" << endl;
}
void fill(IntSet &set)
{
set.insert(4);
set.insert(7);
set.insert(5);
set.insert(1);
set.insert(6);
set.insert(2);
set.insert(5);
}运行结果:
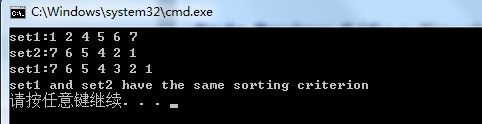
虽然set1和set2的而比较准则本身不同,但是型别相同,所以可以进行赋值操作。
非变动性操作

注意:元素比较操作只能用于型别相同的容器。
特殊的搜寻函数

![]()
赋值
赋值操作两端的容器必须具有相同的型别,但是比较准则本身可以不同,但是其型别必须相同。如果比较准则的不同,准则本身也会被赋值或交换。

迭代器相关函数

元素的插入和删除

注意:插入函数的返回值不完全相同。
set提供的插入函数:
pair<iterator,bool> insert(const value_type& elem); iterator insert(iterator pos_hint, const value_type& elem);multiset提供的插入函数:
iterator insert(const value_type& elem); iterator insert(iterator pos_hint, const value_type& elem);返回值型别不同的原因是set不允许元素重复,而multiset允许。当插入的元素在set中已经包含有同样值的元素时,插入就会失败。所以set的返回值型别是由pair组织起来的两个值:
第一个元素返回新元素的位置,或返回现存的同值元素的位置。第二个元素表示插入是否成功。
set的第二个insert函数,如果插入失败,就只返回重复元素的位置!
但是,所有拥有位置提示参数的插入函数的返回值型别是相同的。这样就确保了至少有了一个通用型的插入函数,在各种容器中有共通接口。
注意:还有一个返回值不同的情况是:作用于序列式容器和关联式容器的erase()函数:
序列式容器的erase()函数:
iterator erase(iterator pos); iterator erase(iterator beg, iterator end);关联式容器的erase()函数:
void erase(iterator pos); void erase(iterator beg, iterator end);这完全是为了性能的考虑。因为关联式容器都是由二叉树实现,搜寻某元素并返回后继元素可能很费时。
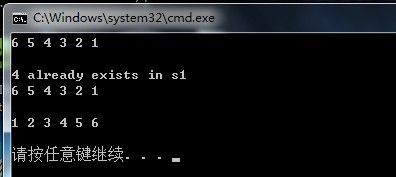
五、set应用示例:
#include <iostream>
#include <set>
using namespace std;
int main()
{
typedef set<int,greater<int> > IntSet;
IntSet s1;
s1.insert(4);
s1.insert(3);
s1.insert(5);
s1.insert(1);
s1.insert(6);
s1.insert(2);
s1.insert(5);
//the inserted element that has the same value with a element existed is emitted
copy(s1.begin(),s1.end(),ostream_iterator<int>(cout," "));
cout << endl << endl;
pair<IntSet::iterator,bool> status = s1.insert(4);
if(status.second)
cout << "4 is inserted as element "
<< distance(s1.begin(),status.first) + 1 << endl;
else
cout << "4 already exists in s1" << endl;
copy(s1.begin(),s1.end(),ostream_iterator<int>(cout," "));
cout << endl << endl;
set<int> s2(s1.begin(),s1.end());//default sort criterion is less<
copy(s2.begin(),s2.end(),ostream_iterator<int>(cout," "));
cout << endl << endl;
}
上述程序最后新产生一个set:s2,默认排序准则是less。以s1的元素作为初值。
注意:s1和s2有不同的排序准则,所以他们的型别不同,不能直接进行相互赋值或比较。
运行结果: