HBase简单介绍
前言
本周学习了部分关于Hadoop生态圈周边的一些系统,简单的做个小结,本篇文章主要讲的是HBase的介绍。HBase是一个在HDFS上构建的面向列的分布式数据库,他与传统的RDBMS还是有许多的不同之处的。HBase的出现可以解决海量数据存储的问题,而且他可以比较容易的解决伸缩性的问题,这个在以往的传统关系型数据库中都是很大的难题。下面是简单的对于HBase的介绍。
HBase介绍
先说说我的个人感受,当我第一次看到HBase是一个面向列式的存储结构时,我立马想到了Google的BigTable,因为他也是面向列式存储的,然后里面同样有列簇的概念,也是属于稀疏存储。所以如果你了解了BigTable相信理解HBase也不会太难。
HBase系统结构
这个当然用图形的方式表现呢出来最直观。
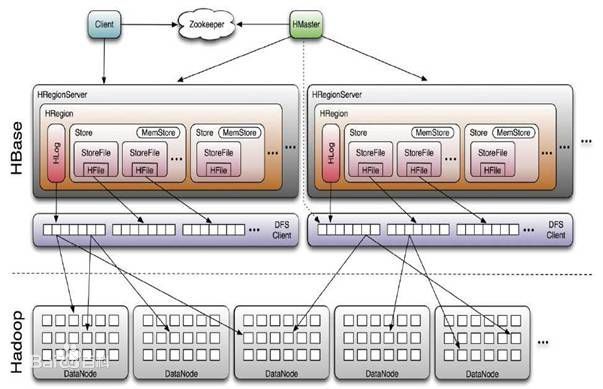
撇开图片下方的Hadoop的部分,上一部分才是HBase的结构,因为HBase所存储的数据是在Hadoop的HDFS中,所以会有所关联。简单的来说,HBase也遵循主从关系,即一个master,然后好多个slave。在这里是一个master节点控制着若干个HRegionServer节点,然后在每个HRegionServer下又会控制到好多个HRegion。HRegion才是真正存储数据的地方。然后这期间会由Zookeeper控制协调中间的服务。
HBase的面向列的存储
HBase的面向列的存储特性是他的一大特点,这样就可以真正做到宽度的效果,列可以做到很多,同样给出一个示例图,在此示例图中,有3个列簇。
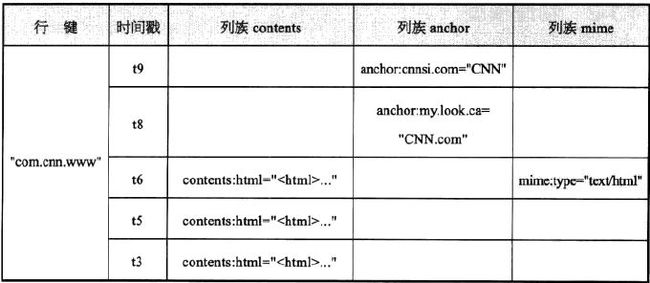
其实在真实的存储中,空余的部分其实是不占空间的,只是效果图这么画而已。
HBase和RDBMS的比较
传统的RDBMS历经了了几十年的发展,已经形成了许多成熟的特性,而且各方面已经成熟化了,比如MySQL这样的。但是如果在数据并发读写和数据规模这2方面,传统的关系型数据库可能就会比较吃紧了。而HBase要做的事情恰恰在于此。因为HBase本身是一个分布式的数据库系统,所以可以让使用者专注于业务上的处理逻辑,中间的数据传输全部都被HBase抽象处理了。而且HBase支持自动分区,当表增长到一定阈值 ,他可以将一个HRegion分裂为2个HRegion。而且HBase可以实现简单的扩展,通过增加节点数来进行线性的扩展。
在使用HBase时可能会碰到的问题
1、第一个问题是可能会碰到文件描述符用完的情况。因为在HBase中,数据文件在启动 时就被打开,并在处理过程中始终保持打开状态,以便节省每次访问操作打开文件所需的代价,所以适当的时候可以增加最大文件描述符数量的限制。
2、datanode的线程用完的情况。默认情况下Hadoop的datanode上最大只能容纳256个线程运行,而在datanode中打开每个文件连接都会使用一个线程,所以256个线程的限制很快就会达到。可以把dfs.datanode.max.xciervers的值调高,并重启集群。
参考资料:<<Hadoop权威指南>>.Tom.White