Machine Learning - IX. Neural Networks Learning神经网络 (Week 5)
http://blog.csdn.net/pipisorry/article/details/44119187
机器学习Machine Learning - Andrew NG courses学习笔记
Neural Networks Learning 神经网络学习
Neural Networks are one of the most powerful learning algorithms that we have today.
Cost Function代价函数

Note:
1 对于multi-class classfication,要求K>=3. if we had two classes then, we will need to use only one output unit.{[01]+[10]和0+1效果一样}
2 对每个y的输出是一个向量而不是数值1,2,3,4

Note: h of x subscript i, to denote the ith output.That is h of x is a K dimensional vector.
Except that we don't sum over the terms corresponding to these bias values
Back propagation Algorithm BP反向传播算法
通过最小化cost fun来求参数

In order to use either gradient descent or one of the advance optimization algorithms.What we need to do therefore is to write code that takes this input the parameters theta and computes j of theta and these partial derivative terms.
主要难点就在于partial derivative terms.求导项
use an algorithm called back propagation to compute the derivatives.
Given only one training example只给出一个训练样本时:
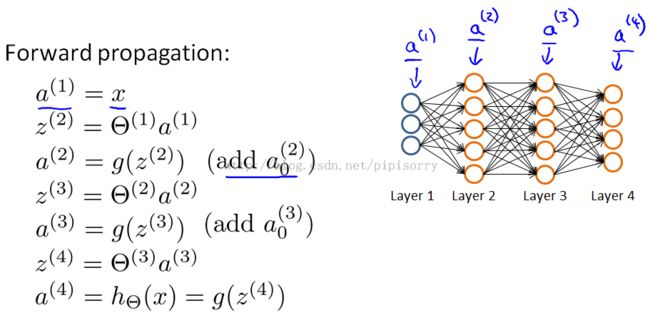

Note:
1. this delta term is in some sense going to capture our error in the activation of that neural duo.
2. 求导推导:
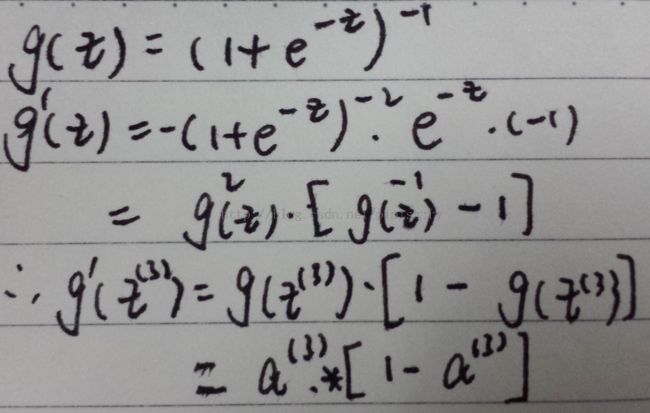
3. ignore authorization then the partial derivative terms you want are exactly given by the activations and these delta terms.
GivenTraining set给出一个训练集时:

Note:
1. these deltas are going to be used as accumulators that will slowly add things in order to compute these partial derivatives.
2. The case of j equals zero corresponds to the bias term so when j equals zero that's why we're missing is an extra regularization term.
3. the formal proof of D terms is pretty complicated what you can show is that once you've computed these D terms, that is exactly the partial derivative of the cost function with respect to each of your perimeters and so you can use those in either gradient descent or in one of the advanced authorization
Back propagation Intuition反向传播直觉知识
Back propagation may be unfortunately is a less mathematically clean or less mathematically simple algorithm.
closer look at what forward propagation is doing
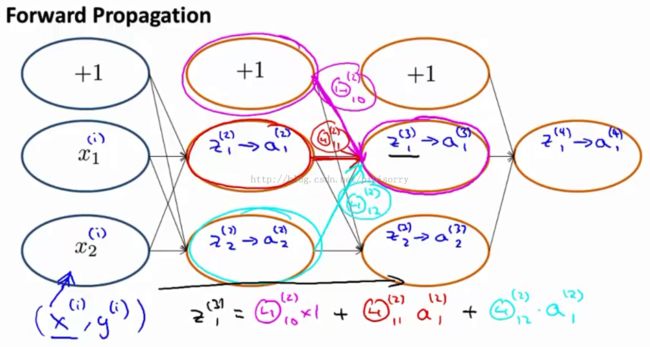
closer look at what back propagation is doing
简化: just focus on the single example x(i)y(i), and focus on the case of having one output unit so y(i) here is just a real number, and let's ignore regularization, so lambda equals zero

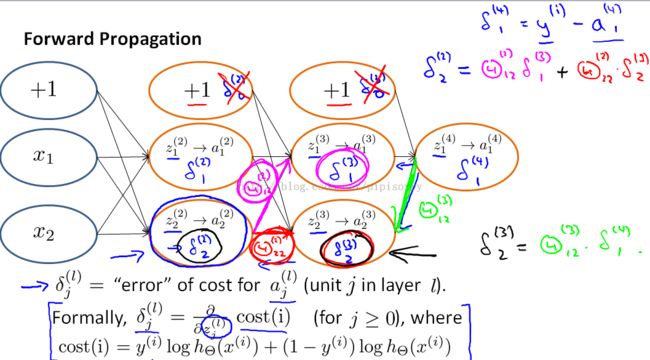
Note: 反向传播时也可以用到bias单元Depending on how you define the back propagation algorithm or depending on how you implement it,you may end up implementing something to compute delta values for these bias units as well.
The bias unit is always output the values plus one and they are just what they are and there's no way for us to change the value and so, we just discard them because they don't end up being part of the calculation needed to compute the derivatives.
Implementation Note:Unrolling Parameters展开参数来实现神经网络参数的求解
{unrolling your parameters from matrices into vectors, which we need in order to use the advanced optimization routines.}
Advanced optimization来求解参数时的用法时的限制
(输入的theta不能是矩阵,只能是长向量)

一个例子(矩阵和向量的相互转换)

Note:
1 thetaVec : take all the elements of your three theta matrices,and unroll them and put all the elements into a big long vector.并且thetaVec是一个列向量。
2 reshape: go back from the vector representations to the matrix representations.
3 两种形式各自的优势:
parameters are stored as matrices it's more convenient when you're doing forward propagation and back propagation and it's easier when your parameters are stored as matrices to take advantage of the, sort of, vectorized implementations.
Whereas in contrast the advantage of the vector representation, when you have like thetaVec or DVec is that when you are using the advanced optimization algorithms.
Advanced optimization来求解神经网络参数

http://blog.csdn.net/pipisorry/article/details/44119187
Gradient Checking梯度检查
使用梯度下降时可能出现的问题
Your cost function J of theta may end up decreasing on every iteration of gradient descent, but this could pull through even though there might be some bug in your implementation of back prop.
So it looks like J of theta is decreasing, but you might just wind up with a neural network that has a higher level of error than you would with a bug-free implementation and you might just not know that there was this subtle bug that's giving you this performance.
梯度的数值估计Numerical estimation of gradients
用梯度的估计值来检测BP算法计算得到的DVec是否正确
when theta was a real number
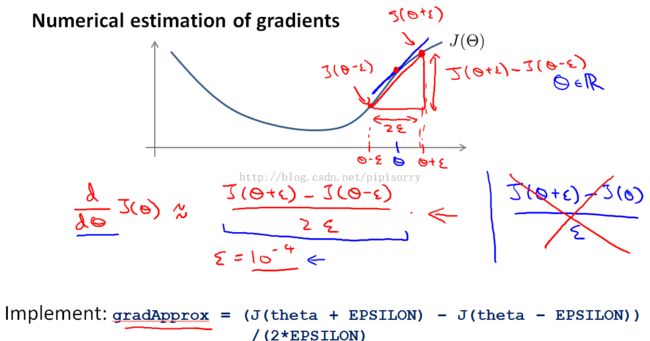
Note:
1 don't use epsilon that's too, too small because then you might run into numerical problems.
2 The two-sided difference gives us a slightly more accurate estimate,so use that rather than just this one-sided difference estimate.
where theta is a vector parameter


Note注意事项
numeric code gradient checking code is a very computationally expensive, that's a very slow way to try to approximate the derivative.
Back prop is a much more computationally efficient way of computing the derivatives.
So once you've verified that your implementation of back-propagation is correct, you should turn off gradient checking.
总结:

Whenever implement back-propagation or similar gradient descent algorithm for a complicated model,always use gradient checking to helps make sure that my code is correct.
Random Initialization随机初始化

神经网络中theta初始化0会带来the problem of symmetric weights的问题
initial value of theta to the vector of all zeroes works okay when we were using logistic regression, whereas does not work when you're trading a neural network.

Note:
1 都初始化0最后重新得到的值又会是一样的(相同颜色线条标注的),即使不再是0.然后计算得到的两个a也是相同的,然后delta相同,然后D相同,一直循环这种相同。
means that your neural network really can't compute very interesting functions.
all of your hidden units are computing the exact same feature, all of your hidden units are computing all of the exact same function of the input.And this is a highly redundant representation.
随机初始化

Putting It Together组合在一起
选择神经网络结构

Note:
1 having the number of hidden units is comparable:
Usually the number of hidden units in each layer will be maybe comparable to the dimension of x, comparable to the number of features, or it could be any where from same number of hidden units of input features to maybe so that three or four times of that.You know, several times, or some what bigger than the number of input features is often a useful thing to do.
six steps to trade in neural network - Training a neural network


Note:
1 usually initialize the weights to small values near zero.
2 BP中求解delta的更高级方法advanced factorization methods where you don't have a four-loop over the m-training examples.{因子图模型?}
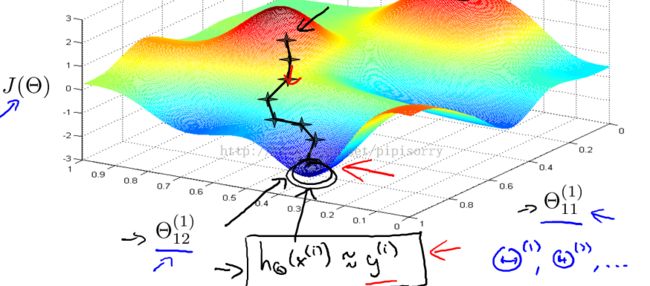
3 可能得到极小值:For neural networks, this cost function j of theta is non-convex,so it can theoretically be susceptible to local minima, but it turns out that in practice this is not usually a huge problem and even though we can't guarantee that these algorithms will find a global optimum, usually algorithms like gradient descent will do a very good job minimizing this cost function j of theta and get a very good local minimum.In practice local optima aren't a huge problem for neural networks.
One figure to get that intuition about what gradient descent for a neural network is doing
Autonomous Driving自动驾驶
Using a Neural Network for autonomous driving

车看到的视图the view seen by the car of what's in front of it:(左下角) up left on top:(左上角)

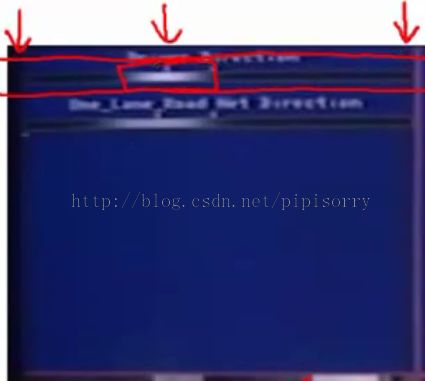
first horizontal bar shows the direction selected by the human driver
the location of this bright white band that shows the steering direction selected by the human driver, where,far to the left corresponds to steering hard left;here corresponds to steering hard to the right; and so this location, which is a little bit left of center, means that the human driver, at this point, was steering slightly to the left.
second part here corresponds to the steering direction selected by the learning algorithm;
But before the neural network starts learning initially, you see that the network outputs a grey band, like a grey uniform, grey band throughout this region, so the uniform grey fuzz corresponds to the neural network having been randomly initialized, and initially having no idea what direction to steer in:

Reviews复习

PS:
Python下(只)用numpy写神经网络
Neural network with numpy
from:http://blog.csdn.net/pipisorry/article/details/44119187