XML编程-DOM
XML编程-DOM
XML解析技术
xml解析技术常用的有两类:dom解析和sax解析。
dom:(Document Object Model, 即文档对象模型)是W3C组织推荐的处理XML的一种方式。
sax:(Simple API for XML)不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它。
Jaxp介绍
Jaxp(Java API for XML Processing)是Java对XML进行编程的开发包,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成。
在 javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
DOM基本概述
DOM(Document Object Model文档对象模型),是W3C组织推荐的处理可扩展标志语言的标准编程接口。XML DOM 定义了所有 XML 元素的对象和属性,以及访问它们的方法(接口)。
原理图
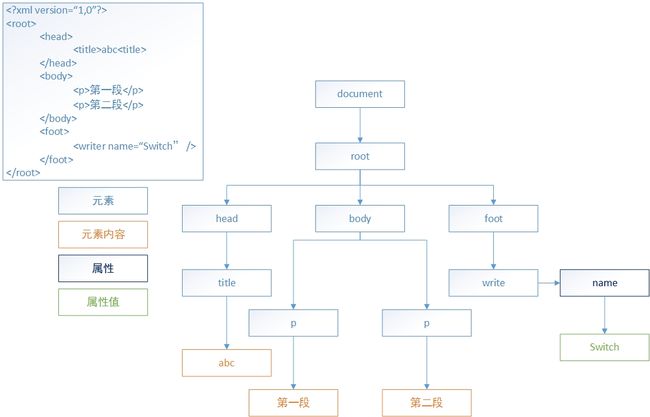
DOM模型(document object model)
DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。
在dom中,节点之间关系如下:
1、位于一个节点之上的节点是该节点的父节点(parent)
2、一个节点之下的节点是该节点的子节点(children)
3、同一层次,具有相同父节点的节点是兄弟节点(sibling)
4、一个节点的下一个层次的节点集合是节点后代(descendant)
5、父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)
Node对象
Node对象提供了一系列常量来代表结点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便于调用其特有的方法。(查看API文档)
Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容了。
PS:其子接口Element功能更多。
获取Jaxp中的DOM解析器
1、调用DocumentBuilderFactory.newInstance()方法创建DOM解析器的工厂。
2、调用DocumentBuilderFactory对象的newDocumentBuilder()方法得到DOM解析器对象,其是DocumentBuilder的对象。
3、调用DocumentBuilder对象的parse()方法解析XML文档,得到代表整个文档的Document对象。
4、通过Document对象和一些相关类和方法,对XML文档进行操作。
更新XML文档
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
用javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
案例:
XML5.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?><班级 班次="1班" 编号="C1"> <学生 地址="湖南" 学号="n1" 性别="男" 授课方式="面授" 朋友="n2" 班级编号="C1"> <名字>张三</名字> <年龄>20</年龄> <介绍>不错</介绍> </学生> <学生 学号="n2" 性别="女" 授课方式="面授" 朋友="n1 n3" 班级编号="C1"> <名字>李四</名字> <年龄>18</年龄> <介绍>很好</介绍> </学生> <学生 学号="n3" 性别="男" 授课方式="面授" 朋友="n2" 班级编号="C1"> <名字>王五</名字> <年龄>22</年龄> <介绍>非常好</介绍> </学生> <学生 性别="男"> <名字>小明</名字> <年龄>30</年龄> <介绍>好</介绍> </学生> </班级>
package com.pc;
import java.awt.List;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
*
* @author Switch
* @function Java解析XML
*
*/
public class XML5 {
// 使用dom技术对xml文件进行操作
public static void main(String[] args) throws Exception {
// 1.创建一个DocumentBuilderFactory对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory
.newInstance();
// 2.通过DocumentBuilderFactory,得到一个DocumentBuilder对象
DocumentBuilder documentBuilder = documentBuilderFactory
.newDocumentBuilder();
// 3.指定解析哪个xml文件
Document document = documentBuilder.parse("src/com/pc/XML5.xml");
// 4.对XML文档操作
// System.out.println(document);
// list(document);
// read(document);
// add(document);
// delete(document, "小明");
update(document, "小明", "30");
}
// 更新一个元素(通过名字更新一个学生的年龄)
public static void update(Document doc, String name, String age)
throws Exception {
NodeList nodes = doc.getElementsByTagName("名字");
for (int i = 0; i < nodes.getLength(); i++) {
Element nameE = (Element) nodes.item(i);
if (nameE.getTextContent().equals(name)) {
Node prNode = nameE.getParentNode();
NodeList stuAttributes = prNode.getChildNodes();
for (int j = 0; j < stuAttributes.getLength(); j++) {
Node stuAttribute = stuAttributes.item(j);
if (stuAttribute.getNodeName().equals("年龄")) {
stuAttribute.setTextContent(age);
}
}
}
}
updateToXML(doc);
}
// 删除一个元素(通过名字删除一个学生)
public static void delete(Document doc, String name) throws Exception {
// 找到第一个学生
NodeList nodes = doc.getElementsByTagName("名字");
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
if (node.getTextContent().equals(name)) {
Node prNode = node.getParentNode();
prNode.getParentNode().removeChild(prNode);
}
}
// 更新到XML
updateToXML(doc);
}
// 添加一个学生到XML文件
public static void add(Document doc) throws Exception {
// 创建一个新的学生节点
Element newStu = doc.createElement("学生");
newStu.setAttribute("性别", "男");
Element newStu_name = doc.createElement("名字");
newStu_name.setTextContent("小明");
Element newStu_age = doc.createElement("年龄");
newStu_age.setTextContent("21");
Element newStu_intro = doc.createElement("介绍");
newStu_intro.setTextContent("好");
newStu.appendChild(newStu_name);
newStu.appendChild(newStu_age);
newStu.appendChild(newStu_intro);
// 把新的学生节点添加到根元素
doc.getDocumentElement().appendChild(newStu);
// 更新到XML
updateToXML(doc);
}
// 更新到XML
private static void updateToXML(Document doc)
throws TransformerFactoryConfigurationError,
TransformerConfigurationException, TransformerException {
// 得到TransformerFactory对象
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 通过TransformerFactory对象得到一个转换器
Transformer transformer = transformerFactory.newTransformer();
transformer.transform(new DOMSource(doc), new StreamResult(
"src/com/pc/XML5.xml"));
}
// 具体查询某个学生的信息(小时第一个学生的所有)
public static void read(Document doc) {
NodeList nodes = doc.getElementsByTagName("学生");
// 取出第一个学生
Element stu1 = (Element) nodes.item(0);
Element name = (Element) stu1.getElementsByTagName("名字").item(0);
System.out.println("姓名:" + name.getTextContent() + " 性别:"
+ stu1.getAttribute("性别"));
}
// 遍历该XML文件
public static void list(Node node) {
if (node.getNodeType() == node.ELEMENT_NODE) {
System.out.println("名字:" + node.getNodeName());
}
// 取出node的子节点
NodeList nodes = node.getChildNodes();
for (int i = 0; i < nodes.getLength(); i++) {
// 显示所有子节点
Node n = nodes.item(i);
list(n);
}
}
}