在线操作SequoiaDB集群缩减
我公司之前上线了一个新应用,底层数据库使用国内一家名叫SequoiaDB的NoSQL数据库作为存储。在原来的规划中,由6台PC服务器共同组成SequoiaDB集群,每台机器均部署了协调节点与CM集群管理节点。
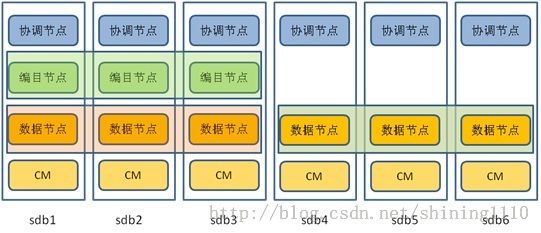
sdb1、sdb2和sdb3三台机器共同组成了编目节点组SYSCatalogGroup与数据节点组datagroup1。
sdb4、sdb5和sdb6三台机器组成了另外一个数据节点组datagroup2。
具体部署如下图示:
但是最近由于公司内部一些原因,要对6台服务器其中两台进行回收,所以数据库需要实施规模缩减操作。由于之前的项目已经上线,没有办法停止业务,给集群执行数据库缩减操作,考虑了很久,终于找到一个在线缩减的方法。
思路是这样的:
由于SequoiaDB的逻辑数据组有一个特性,可以最大指定7个数据节点组成一个逻辑数据组,考虑我们现在线上的数据组只有3个数据节点,完全可以利用这个特性给要迁移的数据组先将数据同步到其他机器上,再将需要移除的数据节点从原数据组中删除,这样我们就能保证业务不中断的情况下,实现了集群缩减的目的。
大致的方法如下图:
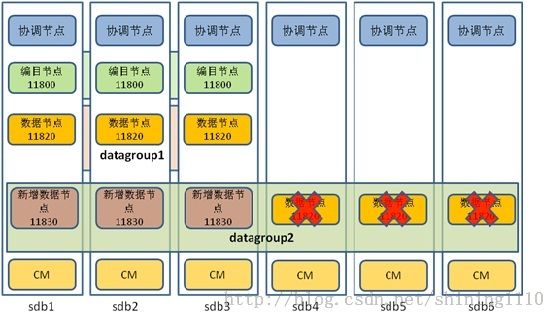
规模缩减后,sdb1、sdb2和sdb3三台机器上已经部署的编目节点组和数据节点组datagroup1保持不变,同时将sdb4、db5和sdb6三台机器部署的数据节点组datagroup2迁移到sdb1、sdb2和sdb3机器上来,达到保持原数据库架构不变,缩减机器规模的目的。
由于目前应用程序选择连接的协调节点为sdb4,所以暂时保留sdb4机器上的协调节点与CM集群管理节点。
集群缩减完成后,部署变成了下面这个样子:

操作命令
连接协调节点
sdb> db = new Sdb("sdb4",11810);
获取datagroup2组的对象
sdb> var rg =db.getRG("datagroup2") ;
在给datagroup2数据组扩展时,首先判断sdb1、sdb2和sdb3机器的11830端口是否被占用,sdbcm进程是否对/var/sequoiadb/data路径有写操作权限。
$> netstat -nap | grep 11830;
$> ls -l /var/sequoiadb/ |grep data ;
扩展datagroup2组的数据节点
sdb> var node =rg.createNode("sdb1",11830,"/var/sequoiadb/data/11830") ;
启动新增数据节点
sdb> node.start() ;
扩展datagroup2组的数据节点
sdb> node =rg.createNode("sdb2",11830,"/var/sequoiadb/data/11830") ;
启动新增数据节点
sdb> node.start() ;
扩展datagroup2组的数据节点
sdb> node =rg.createNode("sdb3",11830,"/var/sequoiadb/data/11830") ;
启动新增数据节点
sdb> node.start() ;
打印目前数据库拓扑, 检查datagroup2组是否正确新增了sdb1:11830、sdb2:11830、sdb3:11830三个数据节点,检查datagroup2组的主数据节点部署在哪台机器上(查看GroupName="datagroup2"的"PrimaryNode"字段)
sdb> db.listReplicaGroups();
连接datagroup2组的主数据节点,假设datagroup2组旧的主数据节点是sdb5机器的11820进程
sdb> datadbm = new Sdb("sdb5",11820);
查看并记录datagroup2组的主数据节点的LSN号
sdb> var masterlsn = {} ;
sdb> masterlsn.offset = datadbm.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"];
sdb> masterlsn.version =datadbm.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"];
分别连接datagroup2组新增的数据节点
sdb> datadb1 = newSdb("sdb1",11830) ;
sdb> datadb2 = newSdb("sdb2",11830) ;
sdb> datadb3 = newSdb("sdb3",11830) ;
分别查看datagroup2组新增的数据节点LSN号
sdb> var d1lsn = {} ;
sdb> d1lsn.offset =datadb1.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"];
sdb> d1lsn.version =datadb1.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"];
sdb> var d2lsn = {} ;
sdb> d2lsn.offset =datadb2.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"];
sdb> d2lsn.version =datadb2.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"];
sdb> var d3lsn = {} ;
sdb> d3lsn.offset =datadb3.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"];
sdb> d3lsn.version =datadb3.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"];
等待datagroup2组新增的数据节点LSN号停止增长并且与datagroup2组主数据节点的LSN号相同。
在新增数据节点的LSN号与主数据节点的LSN号保持一致后,再使用协调节点的连接连续多次查看整个数据库的数据读写情况,如果数据读、写操作指标静止不变,则判断新增数据节点已经完成日志同步。
sdb> db.snapshot(6) ;
sdb> db.snapshot(6) ;
sdb> db.snapshot(6) ;
移除datagroup2组的旧主数据节点,假设datagroup2组旧的主数据节点是sdb5机器的11820进程
sdb> rg.removeNode("sdb5",11820);
检查datagroup2组的选主情况,确定datagroup2组选主成功(查看GroupName="datagroup2"的"PrimaryNode"字段)
sdb> db.listReplicaGroups();
根据PrimaryNode的nodeid,我们可以知道PrimaryNode的HostName,假设为sdb3机器的11830进程,我们直连到sdb3机器的11830进程,检查它是否真实选为datagroup2组的主数据节点(查看"IsPrimary"字段是否为"True")。
sdb> var datadbm = newSdb("sdb3",11830) ;
sdb> datadbm.snapshot(7) ;
确定datagroup2组新选主后,移除另外两个数据节点
sdb> rg.removeNode("sdb4",11820);
sdb> rg.removeNode("sdb6",11820);
这样,我们就完成了数据库的缩减操作了。