搜索引擎技术之概要预览
搜索引擎技术之概要预览
前言
近些天在学校静心复习功课与梳理思路(找工作的事情暂缓),趁闲暇之际,常看有关搜索引擎相关技术类的文章,接触到不少此前未曾触碰到的诸多概念与技术,如爬虫,网页抓取,分词,索引,查询,排序等等,更惊叹于每一幅精彩的架构图,特此,便有记录下来的冲动,以作备忘。
本文从最基本的搜索引擎的概念谈起,到全文检索的概念,由网络蜘蛛,分词技术,系统架构,排序的讲解(结合google搜索引擎的技术原理),而后到图片搜索的原理,最终以几个开源搜索引擎软件的介绍结束全文。
由于本文初次接触此类有关搜索引擎的技术,参考和借鉴了互联网上诸多牛人的文章与作品,有不妥之处,还望诸君海涵。再者因本人见识浅薄,才疏学浅,有任何问题或错误,欢迎不吝指正。同时,正式进军搜索引擎领域的学习与研究。谢谢。
1、什么是搜索引擎
搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。因特网上的信息浩瀚万千,而且毫无秩序,所有的信息像汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为用户绘制一幅一目了然的信息地图,供用户随时查阅。

搜索引擎的工作原理以最简单的语言描述,即是:
- 搜集信息:首先通过一个称为网络蜘蛛的机器人程序来追踪互联网上每一个网页的超链接,由于互联网上每一个网页都不是单独存在的(必存在到其它网页的链接),然后这个机器人程序便由原始网页链接到其它网页,一链十,十链百,至此,网络蜘蛛便爬满了绝大多数网页。
- 整理信息:搜索引擎整理信息的过程称为“创建索引”。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
- 接受查询:用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
2、网络蜘蛛
网络蜘蛛即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度优先和深度优先(如下图所示)。广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。至于两种策略的区别,下图的说明会更加明确。
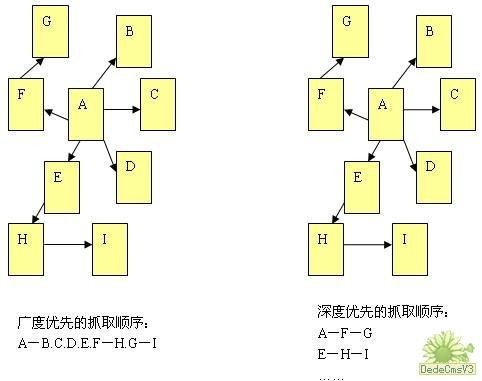
由于不可能抓取所有的网页,有些网络蜘蛛对一些不太重要的网站,设置了访问的层数。例如,在上图中,A为起始网页,属于0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。如果网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。这也让有些网站上一部分网页能够在搜索引擎上搜索到,另外一部分不能被搜索到。 对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。
3、中文分词
下图是我无聊之际,在百度,谷歌,有道,搜狗,搜搜,雅虎中搜索:结构之法的搜索结果比较(读者可以永久在百度或谷歌中搜索:结构之法4个字,即可进入本博客):
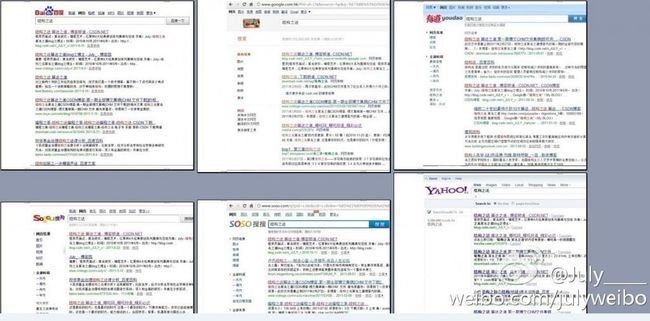
从上图可以看出,百度,谷歌,搜狗,搜搜,雅虎都在第一个选项链接到了本博客--结构之法算法之道,从上面的搜索结果来看,百度给的结果是最令我满意的(几个月前,谷歌的搜索结果是最好的),其次是雅虎英文搜索,谷歌,而有道的搜索结果则差强人意。是什么影响了这些搜索引擎搜索的质量与相关性的程度呢?答曰:中文分词。下面,咱们来具体了解什么是中文分词技术。
中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法。
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
1、基于字符串匹配的分词方法
这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小)。
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。
一种方法是改进扫描方式,称为特征扫描或标志切分,优先在待分析字符串中识别和切分出一些带有明显特征的词,以这些词作为断点,可将原字符串分为较小的串再来进机械分词,从而减少匹配的错误率。另一种方法是将分词和词类标注结合起来,利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
2、基于理解的分词方法
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3、基于统计的分词方法
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。
这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用字组,例如“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
到底哪种分词算法的准确度更高,目前并无定论。对于任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需要综合不同的算法。个人了解,海量科技的分词算法就采用“复方分词法”,所谓复方,相当于用中药中的复方概念,即用不同的药才综合起来去医治疾病,同样,对于中文词的识别,需要多种算法来处理不同的问题。
4、系统架构
- 全文检索
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。图1.1展示了上述全文检索系统的结构与功能。

在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。
- 搜索引擎与全文检索的区别
搜索引擎的门槛到底有多高?搜索引擎的门槛主要是技术门槛,包括网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各方面的技术固然重要,但整个系统的架构设计也同样不可忽视,搜索引擎也不例外。
搜索引擎的技术基础是全文检索技术,从20世纪60年代,国外对全文检索技术就开始有研究。全文检索通常指文本全文检索,包括信息的存储、组织、表现、查询、存取等各个方面,其核心为文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术上逐渐发展起来,并得到广泛的应用,但搜索引擎还是不同于全文检索。搜索引擎和常规意义上的全文检索主要区别有以下几点:
1、数据量
传统全文检索系统面向的是企业本身的数据或者和企业相关的数据,一般索引库规模多在GB级,数据量大的也只有几百万条;但互联网网页搜索需要处理几十亿的网页,搜索引擎的策略都是采用服务器群集和分布式计算技术。
2、内容相关性
信息太多,查准和排序就特别重要,Google等搜索引擎采用网页链接分析技术,根据互联网上网页被链接次数作为重要性评判的依据;但全文检索的数据源中相互链接的程度并不高,不能作为判别重要性的依据,只能基于内容的相关性排序。
3、安全性
互联网搜索引擎的数据来源都是互联网上公开的信息,而且除了文本正文以外,其它信息都不太重要;但企业全文检索的数据源都是企业内部的信息,有等级、权限等限制,对查询方式也有更严格的要求,因此其数据一般会安全和集中地存放在数据仓库中以保证数据安全和管理的要求。
4、个性化和智能化
搜索引擎面向的是互联网访问者,由于其数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集的智能计算技术很难应用,这也是目前搜索引擎技术努力的方向;而全文检索数据量小,检索需求明确,客户量少,在智能化和个性可走得更远。
- 搜索引擎的系统架构
这里主要针对全文检索搜索引擎的系统架构进行说明,下文中提到的搜索引擎如果没有特殊说明也是指全文检索搜索引擎。搜索引擎的实现原理,可以看作四步:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索→对搜索结果进行处理和排序。
1、从互联网上抓取网页
利用能够从互联网上自动收集网页的网络蜘蛛程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集到服务器中。
2、建立索引数据库
由索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。
3、在索引数据库中搜索
当用户输入关键词搜索后,分解搜索请求,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。
4、对搜索结果进行处理排序
所有相关网页针对该关键词的相关信息在索引库中都有记录,只需综合相关信息和网页级别形成相关度数值,然后进行排序,相关度越高,排名越靠前。最后由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。
下图是一个典型的搜索引擎系统架构图,搜索引擎的各部分都会相互交错相互依赖。其处理流程按照如下描述:

“网络蜘蛛”从互联网上抓取网页,把网页送入“网页数据库”,从网页中“提取URL”,把URL送入“URL数据库”,“蜘蛛控制”得到网页的URL,控制“网络蜘蛛”抓取其它网页,反复循环直到把所有的网页抓取完成。
系统从“网页数据库”中得到文本信息,送入“文本索引”模块建立索引,形成“索引数据库”。同时进行“链接信息提取”,把链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评级”提供依据。
“用户”通过提交查询请求给“查询服务器”,服务器在“索引数据库”中进行相关网页的查找,同时“网页评级”把查询请求和链接信息结合起来对搜索结果进行相关度的评价,通过“查询服务器”按照相关度进行排序,并提取关键词的内容摘要,组织最后的页面返回给“用户”。
- 搜索引擎的索引和搜索
下面咱们以Google搜索引擎为例主要介绍搜索引擎的数据索引和搜索过程。
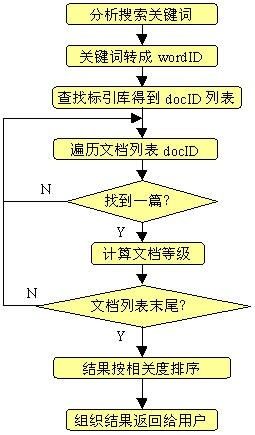
数据的索引分为三个步骤:网页内容的提取、词的识别、标引库的建立。
互联网上大部分信息都是以HTML格式存在,对于索引来说,只处理文本信息。因此需要把网页中文本内容提取出来,过滤掉一些脚本标示符和一些无用的广告信息,同时记录文本的版面格式信息。词的识别是搜索引擎中非常关键的一部分,通过字典文件对网页内的词进行识别。对于西文信息来说,需要识别词的不同形式,例如:单复数、过去式、组合词、词根等,对于一些亚洲语言(中文、日文、韩文等)需要进行分词处理。识别出网页中的每个词,并分配唯一的wordID号,用于为数据索引中的标引模块服务。
标引库的建立是数据索引中结构最复杂的一部分。一般需要建立两种标引:文档标引和关键词标引。文档标引分配每个网页一个唯一的docID号,根据docID标引出在这个网页中出现过多少过wordID,每个wordID出现的次数、位置、大小写格式等,形成docID对应wordID的数据列表;关键词标引其实是对文档标引的逆标引,根据wordID标引出这个词出现在那些网页(用wordID表示),出现在每个网页的次数、位置、大小写格式等,形成wordID对应docID的列表。
搜索的处理过程是对用户的搜索请求进行满足的过程,通过用户输入搜索关键字,搜索服务器对应关键词字典,把搜索关键词转化为wordID,然后在标引库中得到docID列表,对docID列表进行扫描和wordID的匹配,提取满足条件的网页,然后计算网页和关键词的相关度,根据相关度的数值返回前K篇结果(不同的搜索引擎每页的搜索结果数不同)返回给用户。如果用户查看的第二页或者第多少页,重新进行搜索,把排序结果中在第K+1到2*K的网页组织返回给用户。其处理流程如下图所示:
5、排序技术
- Google成功的秘密
Google的成功有许多因素,最重要的是Google对搜索结果的排序比其它搜索引擎都要好。Google保证让绝大部分用搜索的人,都能在搜索结果的第一页找到他想要的结果。客户得到了满足,下一次还过来,而且会向其他人介绍,这一来一往,使用的人就多了。所以Google在没有做任何广告的前提下,让自己成为了全球最大的品牌。Google究竟采用了哪种排序技术?PageRank,即网页级别。
Google有一个创始人叫Larry Page,据说PageRank的专利是他申请的,于是依据他的名字就有了Page Rank。国内也有一家很成功的搜索引擎公司,叫百度( http://www.baidu.com )。百度的创始人李彦宏说,早在1996年他就申请了名为超链分析的专利,PageRank的原理和超链分析的原理是一样的,而且PageRank目前还在Paten-pending(专利申请中)。言下之意是这里面存在专利所有权的问题。这里不讨论专利所有权,只是从中可看出,成功搜索引擎的排序技术,就其原理上来说都差不多,那就是链接分析。超链分析和PageRank都属于链接分析。
链接分析到底为何物?由于李彦宏的超链分析没有具体的介绍,笔者唯一看过的就是在美国专利局网站上关于李彦宏的专利介绍。PageRank的介绍倒是不少,而且目前Google毕竟是全球最大的搜索引擎,这里以PageRank为代表,详细介绍链接分析的原理。
- PageRank揭秘
如何计算PageRank值有一个简单的公式 :
其中:系数为一个大于0,小于1的数。一般设置为0.85。网页1、网页2至网页N表示所有链接指向A的网页。
由以上公式可以看出三点 :
- 链接指向A的网页越多,A的级别越高。即A的级别和指向A的网页个数成正比,在公式中表示,N越大, A的级别越高;
- 链接指向A的网页,其网页级别越高, A的级别也越高。即A的级别和指向A的网页自己的网页级别成正比,在公式中表示,网页N级别越高, A的级别也越高;
- 链接指向A的网页,其链出的个数越多,A的级别越低。即A的级别和指向A的网页自己的网页链出个数成反比,在公式中现实,网页N链出个数越多,A的级别越低。
总之,PageRank有效地利用了互联网所拥有的庞大链接构造的特性。 从网页A导向网页B的链接,用Google创始人的话讲,是页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性,但Google除了看投票数(链接数)以外,对投票者(链接的页面)也进行分析。「重要性」高的页面所投的票的评价会更高,因为接受这个投票页面会被理解为「重要的物品」。
6、图片搜索原理
早有网友阮一峰介绍了一个简单的图片搜索原理,可分为下面几步:
- 缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
- 简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
- 计算平均值。计算所有64个像素的灰度平均值。
- 比较像素的灰度。将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
- 计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
其实早在2008年,Google公布了一篇图片搜索的论文(PDF版),和文本搜索的思路是一样的:
- 对于每张图片,抽取其特征。这和文本搜索对于网页进行分词类似。
- 对于两张图片,其相关性定义为其特征的相似度。这和文本搜索里的文本相关性也是差不多的。
- 图片一样有image rank。文本搜索中的page rank依靠文本之间的超链接。图片之间并不存在这样的超链接,image rank主要依靠图片之间的相似性(两张图片相似,便认为它们之间存在超链接)。具有更多相似图片的图片,其image rank更高一些。
7、开源搜索引擎
全文检索引擎 Sphinx
关注本博客的读者不知是否还记得曾经出现在这篇文章从几幅架构图中偷得半点海量数据处理经验中的两幅图,如下所示:
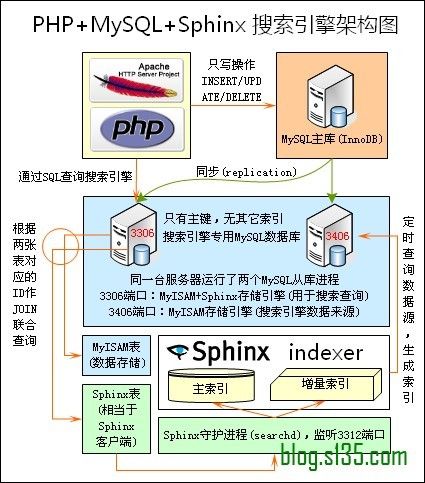
上图出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。

Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件。
C++检索引擎 Xapian
Xapian 的api和检索原理和lucene在很多方面都很相似,但是也有一些地方存在不同,具体请看 Xapian 自己的文档:http://www. xapian .org/docs/
Xapian 除了提供原生的C++编程接口之外,还提供了Perl,PHP,Python和Ruby编程接口和相应的类库,所以你可以直接从自己喜欢的脚本编程语言当中使用 Xapian 进行全文检索了。
Java搜索引擎 Lucene
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单确强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费java资讯检索程式库。人们经常提到资讯检索程式库,就像是搜寻引擎,但是不应该将资讯检索程式库与网搜索引擎相混淆。
Lucene最初是由Doug Cutting所撰写的,是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后来在Excite担任高级系统架构设计师,目前从事 于一些INTERNET底层架构的研究。他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。
C++搜索引擎 CLucene
CLucene是Lucene的一个C++端口,Lucene即是上面所讲到的一个基于java的高性能的全文搜索引擎。CLucene因为使用C++编写,所以理论上要比lucene快。
搜索引擎 Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然 不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的 费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有 动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
- 每个月取几十亿网页
- 为这些网页维护一个索引
- 对索引文件进行每秒上千次的搜索
- 提供高质量的搜索结果
- 以最小的成本运作