OpenStack开发基础-AMPQ
AMPQ和rabbitmq
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同开发语言等条件的限制。一个应用协议的标准,好比是http协议,其实现就有很多种,什么Apache,Nginx等其中rabbitmq就是实现了AMQP协议的一种,此外还有qpid,ZeroMQ等。本文主要谈谈如何基于python来操作rabbitmq。rabbitmq说白了就是一个消息代理,使用的AMQP这种消息队列协议的消息代理,其基本思想很很简单,就是接收消息然后转发。你可以认为rabbitmq就是一个邮局,当你需要发送一份信件到邮箱中,你确信邮递员可以把这封信件递送到收件人的手里。rabbitmq在这里就是一个邮箱,一个邮局,一个邮递员。只不过在rabbitmq中,邮件不在是纸质的书信,而是二进制的数据。
Hello World
第一个例子会演示一下,使用rabbitmq的最简单的方式,单producer单consumer,producer产生消息到一个命名的消息队列,消费者从队列中取出消息消费。producer和consumer需要知道消息队列的名字.先安装好rabbitmq,然后使用下面的命令安装rabbitmq的python客户端。
pip install pika安装完成后,运行下面这段代码查看是否可以连接成功
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()上面的localhost可以替换成你安装rabbitmq的机器.运行上面的代码,如果没有输出就表明连接成功了.接着看下面一个Hello World的完整实例

producer端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()前三行导入相关的package,然后进行连接,在rabbitmq中传输过程全部封装在channel对象中,所以通过连接得到一个channel对象.接着声明了一个队列如果队列不存在那么就创建,否则就使用已经创建的,然后通过basic_publish将消息发送到消息队列,exchange这里空出来了,占时不需要,后面会说到这个参数,routing_key则是指明消息要发送到哪个消息队列中.rabbitmq中的消息其实不是直接发送到消息队列中的,而是先发送到exchange(交换机),然后通过routing_key发送到指定的消息队列中.routing_key则需要填入消息队列的名字.
consumer端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch,method,properties,body):
print(" [x] Received %r" %body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(" [*] Waiting for messages, To exit press CTRL+C")
channel.start_consuming()接收端没有什么特别的地方,使用了basic_consume来消费消息,并设置回调函数.收到消息后调用回调函数,需要注意的就是这里需要将queue设置成发送端创建的消息队列名字.运行一下把,接收端运行后会一致使用epoll循环接收消息,没有消息就阻塞等待.所以当你运行接收端的时候程序会一直在运行.这种工作方式很简单了,替代了传统的socket通信的过程.
注:可以使用rabbitmqctl list_queues命令查看当前系统上有多少个消息队列.
Work queues
一个producer,一个consumer,模型简单,但是适用的场景有限,实际的场景往往是多个producer,多个consumer,所以这里就引入了rabbitmq的第二个工作方式Work queue工作方式,一个producer产生的消息可以被多个consumer进行消费.先看看代码,然后再一个个解释.

producer端:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue',durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World"
channel.basic_publish(exchange='',
routing_key = 'task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2,
))
print(" [x] Sent %r" %message)
connection.close()producer端,和Hello,Word版本差别不大,在queue_declare的时候加上了durable=True,这是用来进行持久化的,默认rabbitmq把消息放在内存中,断电后消队列会丢失,加入durable=True则会将队列持久化到磁盘中,在basic_publish中加上了 properties=pika.BasicProperties(delivery_mode = 2,),这个就是用来设置消息持久化的,
此外可以通过命令行来传递要发送的消息.除此之外这个版本的producer端没有其它变化了.
consumer端
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue',durable=True)
print(' [*]Waiting for messages. To exit press CTRL+C')
def callback(ch,method,properties,body):
print(" [X] Received %r" %body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count = 1)
channel.basic_consume(callback,
queue = 'task_queue')
channel.start_consuming()接收端在basic_consuming中少了一个no_ack=True,多了一个basic_qos,no_ack=True表明在consumer拿到一个消息消费后就立刻从消息队列中删除,如果此时consumer进程挂了,那么消息就丢了,如果不想在这种突发情况下丢失消息就不要设置no_ack=True,默认情况下consumer拿到一个消息后处理完成了会响应一个ack给producer,当producer接收到响应的ack后才从内存中删除消息.所以需要在consumer中的callback函数中加上basic_ack(delivery_tag = method.delivery_tag)这就是用来响应ack给producer的.那么basic_qos这句是干什么的呢?先想一下在一个只有一个producer多个consumer的时候,producer发送消息的时候会按照轮询的方式投递到每一个consumer,如果某些consumer处理消息需要较长时间,有的则很快处理完成,那么一段时间的轮询会导致某些consumer会积累很多的待处理消息,那么basic_qos(prefetch_count = 1),在这里表示的意思就是producer一次只能投递一个消息给一个consumer,也就是说consumer如果没有响应ack给producer,那么producer就不再投递消息给这个consumer.这里的prefetch_count = 1表示的意思就是consumer可持有的未响应ack的消息个数.你现在可以运行看看效果了,先开启多个consumer端,然后使用producer端不断的发送消息看看效果.
Publish/Subscribe
尽管work queue的工作方式看起来很不错,但是还是很难满足一些比较细粒度的需求,如果多个consumer在接收消息的时候无法让每一个consumer都接收到消息,work queue工作模式下,消息是轮询的发送给每一个consumer的,而不是把一个消息广播给每一个consumer,那么Publish/Subscribe工作模式则是会将一个消息广播给所有连接上的consumer.
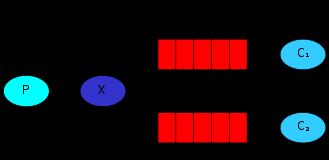
producer端:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" %message)
connection.close()发送端定义了一个exchange,名字为logs,类型是fanout,对于rabbitmq老说exchange的类型一共有四种如下:
- direct
- topic
- headers
- fanout
注:通过使用rabbitmqctl list_exchanges命令可以列出当前系统上定义的所有exchange,并表示了exchange的类型,上面的代码使用了一个最简单的exchange类型fanout.这种类型的exchange将会将消息广播给所有的队列.
consumer端:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()consumer端做了很多的改动, exchange_declare创建了一个exchange,如果存在就直接使用这个exchange,然后使用method.queue创建了一个随机命名的消息队列,最后通过queue_bind将exchange和消息队列绑定起来,在之前的文章中都是直接创建消息队列,然后就可以使用了,其实不然,有没有注意到前面的代码也出现了exchange,只是exchange=”是空的,在上面的文章中已经强调了,在rabbitmq中消息不是直接发送给消息队列的,而是先发送给exchange,然后通过exchange指定的routing_key来路由到指定的队列中的,因为excahnge=”所以使用的是默认的exchange,而在这个部分的代码中exchange是自己创建的,所以需要将exchange和队列绑定一下(其实不绑定也是可以的,只要在basic_publish中指定exchange和routing_key就可以了,但是这里使用的是fanout类型的exchange,这种类型的exchange,routing_key是无效的,这种exchange会将消息广播到所有绑定在上面的消息队列,而不是像默认exchange那样根据routing_key来发送消息到指定的消息队列中)
channel.queue_declare(exclusive=True)这句话其实就是将队列和默认的exchange解绑.
注:通过调用rabbitmqctl list_bindings命令可以查看到系统上所有的exchange和消息队列的绑定关系.
注:运行的时候,需要注意要先运行consumer端,然后再运行producer端,否则你会发现消息都丢失了,因为在这种工作模式下,当发送一个消息到exchange的时候,如果没有consumer监听,那么这个消息就会被丢弃掉.
Routing
Publish/Subscribe工作模式下,所有连接在exchange上的consumer都会接收到producer产生的消息,对于OpenStack这种大规模应用来说,消息的粒度还不是很细,所以rabbitmq中又有了Routing这种工作方式,在这种工作方式下,所有的consumer可以指定自己感兴趣的内容,当producer产生消息后,消息就会广播发送给那些对这个消息感兴趣的consumer.来看一看代码吧.

producer端:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
exchange类型是direct,本质上和fanout类型的exchange一样,也会广播消息,但是direct类型的消息会根据routing_key来广播,而不是全广播,这段代码会通过命令行传入的routing_key来进行广播消息.
consumer端:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
consumer部分的代码基本和Publish/Subscribe工作模式一样,知识exchange的类型换成了direct,绑定的时候加入了routing_key.现在你可以运行多个consumer,每个consumer可以指定不同的routing_key,然后运行producer端发送不同类型的消息.到此为此一个比较细粒度的工作方式就介绍完了.
注:需要注意的是,consumer端可以把一个队列和一个exchange绑定多次,每次绑定的routing_key不一样.这样就可以使得这个consumer可以关注多个感兴趣的消息.
Topics
Routing的工作方式可以说近乎完美了,但是生产环境总是千变万化,如果consumer对待消息的发送者也做出要求该怎么办呢,不仅仅只接收某些routing_key的消息,还限制只从哪些consumer接收消息.除此之外还可以根据某种模式来匹配可以接收到的消息.看一下代码吧.
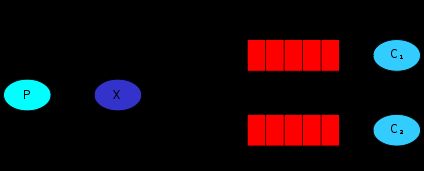
producer端:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
这个部分的代码基本没有变动只是exchange的type变成了topic类型,此外routing_key的格式应该是”some.some….”的格式,按照点号分割的多个字段.用于进行模式匹配
consumer端:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
consumer端的代码,也是基本一样的.总体来说这版本的代码和Routing版本的代码改动不大,最主要的区别在于routing_key的格式和模式匹配,看看下面的怎么运行的吧.
#可以接收到所有的消息
python consumer.py "#"
#可以接收到kern开头的消息
python consumer.py "kern.*"
#可以接收到critical结束的消息
python consumer.py "*.critical"
#可以接收到kern开头critical结束的消息
python consumer.py "kern.*" "*.critical"
#producer发送的消息,上面的consumer都可以接收到
python producer.py "kern.critical" "A critical kernel error"注: kern.critical.test 和kern.*是不匹配的,一个*号只能匹配一段,每段都是通过点号进行分割.
参考文献
Rabbitmq Tutorial