Opencv2.4.9源码分析——BRIEF
在嵌入式系统内,对图像进行实时匹配,这项任务给特征点的检测与描述提出了更高的要求。这不仅要求运算速度快,而且还要求占用更少的内存。
SIFT和SURF方法性能优异,但它们在实时应用中就力不从心,一个主要的原因就是特征点的描述符结构较复杂,表现形式是第一描述符的维数较多,第二描述符采用浮点型的数据格式。维数多固然可以提高特征点的可区分性,但使描述符的生成和特征点的匹配的效率降低,另一方面采用浮点型的数据格式也必然增加了更大的内存开销。因此改进描述符的形式就成为提高特征点匹配的一个重要手段。
目前改进描述符的方法有降低维数和浮点型用整型替代,而另一种更彻底的方法就是直接把描述符缩短为二值化的位字符串形式。这样用汉明距离(Hamming)就可以更快的测量两个描述符的相似程度,方法是按位进行异或位操作,结果中“1”的数量越多,两个描述符的相似性越差。
Michael Calonder等人基于前人的方法于2010年提出了BRIEF(BinaryRobust Independent Elementary Features)方法。该方法也是二值位字符串的描述符形式,但描述符的创建更简单,更有效。
BRIEF的方法是:首先以特征点为中心定义一个大小为S×S的补丁(patch)区域,在opencn2.4.9中,该区域的大小为48×48。再在该区域内,以某种特定的方式选择nd个像素点对。然后比较像素点对的灰度值:
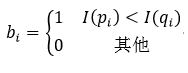 (1)
(1)
I(pi)和I(qi)分别表示第i个像素点对的两个像素pi和qi的灰度值。最后把补丁区域内所有点对的比较结果串成一个二值位字符串的形式,从而形成了该特征点的描述符。
B = b0b1…bi…bnd (2)
通过实验对比可知,nd = 128,256和512时,在运算速度,空间占用和准确性上可以达到最佳的效果。如果用字节型来表示描述符的话,那么
k =nd / 8 (3)
k就表示为描述符的字节数。
BRIEF描述符的创建过程比较简单,但这里还要注意两个问题。第一是为了降低灵敏度,增强描述符的抗干扰程度和可重复性,需要对补丁区域进行平滑处理,也就是在比较点对的两个像素灰度值之前,需要对这两个像素进行平滑处理。采用7×7的高斯模板平滑处理是一种常用的方法,但该方法在速度上与其他的平滑方法比较来看没有优势。因此,Calonder等人又于2011年提出采用盒状滤波器的处理方法来代替高斯平滑处理方法。由于可以采用积分图像的方法,所以盒状滤波器比高斯滤波器更快,而且两者的准确性几乎相同。在opencn2.4.9中,盒状滤波器的大小为9×9。
第二个需要注意的问题是在补丁区域内用什么方式选择像素点对。Calonder比较了5种方法,我们都分别给予介绍,其中我们以补丁区域的中心(即特征点)作为坐标原点,设X和Y是一个点对的两个像素的随机变量,xi和yi为其所对应的像素坐标:
1、X和Y都服从在[-S/2,S/2]范围内的均匀分布,且相互独立;
2、X和Y都服从均值为0,方差为S2/25的高斯分布,且相互独立,即X和Y都以原点为中心,进行同方差的高斯分布;
3、X服从均值为0,方差为S2/25的高斯分布,而Y服从均值为xi,方差为S2/100的高斯分布,即先确定X的高斯分布得到xi,同方法2,然后以xi为中心,进行高斯分布确定yi;
4、在引入了空间量化的不精确极坐标网格的离散位置内,随机采样,得到xi和yi;
5、xi固定在原点处,yi是所有可能的极坐标网格内的值。
通过实验对比可知,前4种方法要好于第5种方法,而在前4种方法中,第2种方法会表现出少许的优势。
在实际应用中,虽然点对都是按一定规则随机选择的,但在确定了补丁区域大小S的情况下,点对的坐标位置一旦随机选定,就不再更改,自始自终都用这些确定下来的点对坐标位置。也就是说这些点对的坐标位置其实是已知的,在编写程序的时候,这些坐标事先存储在系统中,在创建描述符时,只要调用这些坐标即可。另外,不但点对的坐标位置是确定好的,点对的两个像素之间的顺序和点对的顺序也必须是事先确定好的,这样才能保证描述符的一致性。点对的两个像素之间的顺序指的是在公式1中,两个像素哪个是pi,哪个是qi,因为在比较时是pi的灰度值小于qi的灰度值时,bi才等于1。点对的顺序指的是nd个点对之间要排序,这样二值位字符串中的各个位(公式2)就以该顺序排列。
最后需要强调的是,BRIEF仅仅是一种特征点的描述符方法,它不提供特征点的检测方法。Calonder推荐使用CenSurE方法进行特征点的检测,该方法与BRIEF配合使用,效果会略好一些。在Opencv2.4.9中也提供了CenSurE方法,但是使用Star这个别名。
BRIEF是一种更快的特征点描述符的创建和匹配方法,此外只要在平面内没有很大的旋转,则该方法还可以提供很高的识别率。
下面我们就给出BRIEF方法的源码分析。
BRIEF描述符创建的类是BriefDescriptorExtractor,它的构造函数为:
//bytes表示描述符的字节数,即公式3中的k,k只可能为16,32和64,默认为32
BriefDescriptorExtractor::BriefDescriptorExtractor(int bytes) :
bytes_(bytes), test_fn_(NULL)
{
//根据字节数选择不同的函数,字节数不同,则所需要的像素点对的数量就不同,所以要调用不同的函数
switch (bytes)
{
case 16: //128个点对
test_fn_ = pixelTests16;
break;
case 32: //256个点对
test_fn_ = pixelTests32;
break;
case 64: //512个点对
test_fn_ = pixelTests64;
break;
default: //只可能为以上三种情况
CV_Error(CV_StsBadArg, "bytes must be 16, 32, or 64");
}
}
创建BRIEF描述符的函数computeImpl:
void BriefDescriptorExtractor::computeImpl(const Mat& image, std::vector<KeyPoint>& keypoints, Mat& descriptors) const
{
// Construct integral image for fast smoothing (box filter)
Mat sum; //积分图像矩阵
Mat grayImage = image; //输入图像
//把输入图像转换为灰度图像
if( image.type() != CV_8U ) cvtColor( image, grayImage, CV_BGR2GRAY );
///TODO allow the user to pass in a precomputed integral image
//if(image.type() == CV_32S)
// sum = image;
//else
integral( grayImage, sum, CV_32S); //得到输入图像的积分图像
//Remove keypoints very close to the border
// PATCH_SIZE = 48;表示补丁区域的边长,KERNEL_SIZE = 9;表示盒状滤波器的边长
//根据补丁区域和盒状滤波器的尺寸大小,去掉那些过于靠近图像边界的特征点
KeyPointsFilter::runByImageBorder(keypoints, image.size(), PATCH_SIZE/2 + KERNEL_SIZE/2);
//描述符矩阵变量清零
descriptors = Mat::zeros((int)keypoints.size(), bytes_, CV_8U);
//调用test_fn_指向的函数,创建BRIEF描述符
test_fn_(sum, keypoints, descriptors);
}
由构造函数可知,根据描述符字节数的不同,test_fn_指向不同的函数,这些函数的意义相同,区别在于处理的点对数量不同,我们仅以pixelTests16函数为进行讲解。
static void pixelTests16(const Mat& sum, const std::vector<KeyPoint>& keypoints, Mat& descriptors)
{
//遍历所有的特征点
for (int i = 0; i < (int)keypoints.size(); ++i)
{
uchar* desc = descriptors.ptr(i); //描述符的首地址指针
const KeyPoint& pt = keypoints[i]; //特征点的首地址指针
#include "generated_16.i" //执行generated_16.i预处理文件
}
}
在generated_16.i文件中,用到了smoothedSum函数,它的作用是对点对进行盒状滤波器的平滑处理,我们先给出这个函数:
//sum为积分图像,pt为特征点变量,x和y表示点对中某一个像素相对于特征点的坐标,函数返回滤波的结果
inline int smoothedSum(const Mat& sum, const KeyPoint& pt, int y, int x)
{
//盒状滤波器边长的一半
static const int HALF_KERNEL = BriefDescriptorExtractor::KERNEL_SIZE / 2;
//计算点对中某一个像素的绝对坐标
int img_y = (int)(pt.pt.y + 0.5) + y;
int img_x = (int)(pt.pt.x + 0.5) + x;
//计算以该像素为中心,以KERNEL_SIZE为边长的正方形内所有像素灰度值之和,本质上是均值滤波
return sum.at<int>(img_y + HALF_KERNEL + 1, img_x + HALF_KERNEL + 1)
- sum.at<int>(img_y + HALF_KERNEL + 1, img_x - HALF_KERNEL)
- sum.at<int>(img_y - HALF_KERNEL, img_x + HALF_KERNEL + 1)
+ sum.at<int>(img_y - HALF_KERNEL, img_x - HALF_KERNEL);
}
我们再回到generated_16.i文件:
//定义宏SMOOTHED,作用就是调用smoothedSum函数,SMOOTHED中的参数y和x表示相对于特征点的坐标
#define SMOOTHED(y,x) smoothedSum(sum, pt, y, x)
//该描述符需要16个字节型变量,所以从desc[0]到desc[15]
desc[0] = (uchar)(
//每个字节型变量由8位组成
//比较平滑处理以后的坐标为(-2, -1)和(7, -1)的两个像素的灰度值,如公式1,并把结果移位到第7位上
((SMOOTHED(-2, -1) < SMOOTHED(7, -1)) << 7) +
((SMOOTHED(-14, -1) < SMOOTHED(-3, 3)) << 6) + //第6位
((SMOOTHED(1, -2) < SMOOTHED(11, 2)) << 5) + //第5位
((SMOOTHED(1, 6) < SMOOTHED(-10, -7)) << 4) + //第4位
((SMOOTHED(13, 2) < SMOOTHED(-1, 0)) << 3) + //第3位
((SMOOTHED(-14, 5) < SMOOTHED(5, -3)) << 2) + //第2位
((SMOOTHED(-2, 8) < SMOOTHED(2, 4)) << 1) + //第1位
((SMOOTHED(-11, 8) < SMOOTHED(-15, 5)) << 0)); //第0位
//以下省略
desc[1] = ……
……
desc[15] = ……
#undef SMOOTHED
下面给出应用BRIEF方法进行图像匹配的实例,其中我们是STAR方法进行特征点的检测:
#include "opencv2/core/core.hpp"
#include "highgui.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/features2d/features2d.hpp"
#include "opencv2/nonfree/nonfree.hpp"
#include "opencv2/legacy/legacy.hpp"
using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
Mat img1 = imread("box_in_scene.png");
Mat img2 = imread("box.png");
vector<KeyPoint> key_points1, key_points2;
StarDetector detector; //特征点检测方法
detector.detect(img1, key_points1);
detector.detect(img2, key_points2);
Mat descriptors1, descriptors2;
BriefDescriptorExtractor brief; //BRIEF方法
brief.compute(img1, key_points1, descriptors1);
brief.compute(img2, key_points2, descriptors2);
BruteForceMatcher<Hamming> matcher;
vector<DMatch>matches;
matcher.match(descriptors1,descriptors2,matches);
std::nth_element(matches.begin(), // initial position
matches.begin()+29, // position of the sorted element
matches.end()); // end position
// remove all elements after the 30th
matches.erase(matches.begin()+30, matches.end());
namedWindow("BRIEF_matches");
Mat img_matches;
drawMatches(img1,key_points1,
img2,key_points2,
matches,
img_matches,
Scalar(255,255,255));
imshow("BRIEF_matches",img_matches);
waitKey(0);
return 0;
}