并行计算在GIS矢量数据化简中的应用
在地理信息系统中,矢量数据化简有很广的用途,例如在webgis中减少数据传输量、在制图中对数据进行抽稀等。然而GIS中数据量一般都比较大,利用单核单线程计算可能会觉得速度比较慢,在本文中,将探索利用硬件来加速矢量数据化简的方法,主要包括多核计算和GPU计算。
1基于OpenMP的改进算法的多核实现
由于目前多核CPU的普及和降价,多核计算成为并行计算的一个重要研究方向。为了充分利用多核CPU的计算资源,本文研究在多核处理器上运用OpenMP多核编程技术实现化简算法。
1.1 OpenMP简介
OpenMP是由OpenMP Architecture Review Board领头提出的。目前已被广泛接受,它是基于共享内存以及分布式共享内存的多处理器多线程并行编程框架。它也是一种编译指导语句,能够显式指导多线程、共享内存并行的应用程序编程接口(API)。它诞生于1997年,目前已经推出OpenMP 3.0版本,支持Fortran/C/C++,且具有良好的可移植性,支持大多数的类UNIX系统以及Windows系统。
OpenMP以线程为基础,通过编译指导语句来显式地指导并行化,为编程人员提供对并行化的完整控制。采用Fork-Join并行计算模式,具体的执行模型如图1-1所示。
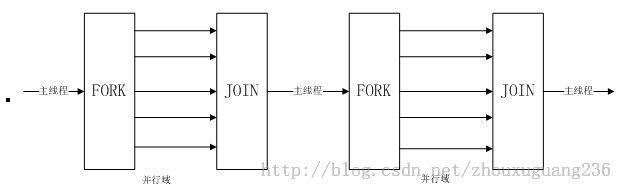
图1-1 Fork-Join并行计算模式
OpenMP主要包括编译指导语句和运行时库函数,通过这两部分协调控制程序的运行。常用的编译指导语句有以下几个:①#pragma omp parallel指定并行域,其中的代码被多个线程并行执行;②#pragma omp parallel for指定工作共享结构,指示for循环被分配到多个工作线程并行执行;③#pragma omp barrier为同步指示,表示线程在此等待,直到所有线程都执行到这个点,才能继续向下执行。
对于运算量非常大的科学与工程计算程序来说,循环通常占比较大的比重,因此可以对循环进行并行化,但并不是所有的循环结构都可以直接进行并行化。对于循环的并行执行有一定的限制,前后两个循环之间不能存在相关性,特别是循环中不能存在共享变量,当多个线程对同一个共享变量进行读写的时候,读写的值极有可能是不正确的,这会造成“数据竞争”的现象。
1.1 改进的多核策略分析与实现
为了消除数据之间的竞争,本文在多核计算中主要采取两种策略:任务分解与数据分解。下文将详细分析矢量化简算法的多核计算策略与具体实现。
在地理信息系统中,线状要素化简是一个比较常见的功能,在前文的讨论中,都是只考虑单个要素的化简问题。然而,地图综合往往操作的单元是一个图层,所以本文考虑一个图层内所有要素的化简问题。从任务分解的角度来考虑,上述算法的第一步比较简单,不需要并行。第二步是一个循环结构,循环前后的数据没有联系,并且该循环计算距离是CPU计算密集型的操作,所以非常适合并行。第三步到最后一步都是常规的判断或者顺序操作,所以,这三步不需要并行。在图层级别上,对每一个要素进行化简,化简的结果最后存储在C++的数据容器vector或者CArray中,但是多个线程并发访问同一个变量可能会造成访问得到的结果是一个不可预知的值。从数据分块的角度来看,最简单的方法是将数据按照矩形分块,但是这会造成大量曲线被打断,也可以先将折线分解为多个折线段,比如单调链,但是,这种分解与结果的合并也需要一定的时间,所以这种方式并不适合并行化简。
本文将结合这两种策略,在两个不同的层次上进行矢量数据的并行化简。其核心代码如下所示。首先在图层级别上将要素集分组,而不是按照矩形分块。然后创建合适数量的线程,一般取机器CPU的数量作为线程的个数,OpenMP中获取CPU的个数通过函数omp_get_num_procs()来实现。并且开辟合适数量的不同线程下对应的数组,然后将这些数据送入不同的线程中参与计算,参与计算的结果分别存储到各自的数组中,等待多核计算过程结束后,合并各个数组的元素即为最后矢量数据化简的结果。
int coreNum = omp_get_num_procs(); //CPU的个数
omp_set_num_threads(coreNum);
vector<vector<BLGData>>*pPriorBlg=new vector<vector<BLGData> >[coreNum];
for (int i = 0; i < coreNum; i ++)
{
pPriorBlg[i].clear();
}
#pragma omp parallel for schedule(static)
for (int i = 0; i < fCount; i ++)
{
int tid = omp_get_thread_num(); //获得每个线程的ID
LineVertex lineVec = lineArrs.GetAt(i);
//对lineVec进行化简处理
...
pPriorBlg[tid].push_back(vec);
}
//将各个线程化简结果合并
for (int i = 0; i < coreNum; i ++)
{
m_lstBlg.insert(m_lstBlg.end(),pPriorBlg[i].begin(),pPriorBlg[i].end());
}
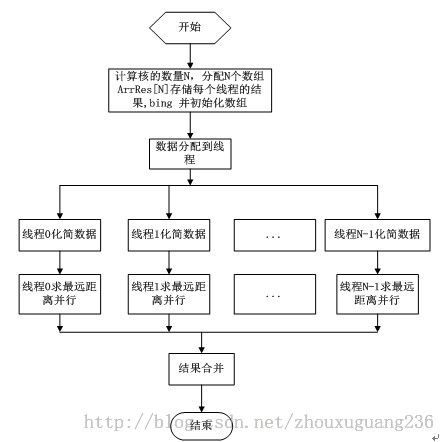
图1-2并行矢量数据化简流程图
为了消除数据之间的相关性,本文将根据实际机器的CPU核的数量N,分配N个独立的数组ArrRes[N],然后对其进行初始化,将数据分配到N个独立的线程中参与化简的计算,用到OpenMP中的编译制导语句#pragma omp parallel for schedule(static)进行线程的静态分配,由于每一个要素的化简过程中需要计算最大偏移距离,所以在这一步中用#pragma omp parallel for编译制导语句进行并行化处理,最后将每一个线程的计算结果,也就是数组ArrRes中的每一项的元素进行合并就是最终结果。图1-2的流程正好体现了串行和并行交替的执行模式,同时也突出了OpenMP的Fork-Join的并行执行模式。
2基于OpenCL的矢量化简算法并行实现
随着目前海量空间数据的不断增长,如何加快矢量数据的化简速度是一个值得研究的问题,而基于显卡硬件加速成为目前流行的加速技术。作为显卡上的图形渲染的专用处理器,GPU具有很高的并行性,随着应用范围不断的扩展,GPU已经从单一的图形渲染转为通用计算,而OpenCL就是在这个上面发展起来的一项标准和通用技术。
OpenCL全称是Open Computing Language,即开放计算语言,它为异构平台提供了一个编写程序尤其是并行程序的开放的框架标准。OpneCL可以支持的处理器比较多,包括CPU、GPU等设备,主要包括两部分:管理平台的API和编写内核程序(在OpneCL设备上运行的代码)的语法规范。OpenCL软件框架包括平台层、运行时和编译器三部分。在平台层上,编程人员可以查询本机可以运行的平台,并且选定参与计算的平台,生成设备上下文环境,查询设备相关信息等;运行时主要用来装载内核函数,并将其映射到主机的内存空间中;编译器将内核程序编译成可执行的程序在设备上运行。OpneCL提供了基于任务和数据的两种并行计算机制。本文依靠OpenCL在GPU上实现CPU上串行化简算法的并行化。
使用GPU加快矢量数据的化简主要步骤包括平台初始化、向GPU发送数据、在GPU中参与计算以及将计算结果拷贝到主机内存中。首先,一个GIS图层中的线状要素需要传输到GPU显存中,然而OpenCL不支持主机主机端自定义的数据结构,所以需要将线状要素坐标序列化存储在一个数组中;其次,还需要传输每个线状要素的坐标偏移量;然后,由于线状要素是分要素化简,那么需要将每个要素的点的个数传输到GPU设备端;最后要传输线状要素的个数。根据OpenCL编程的特点,作者定义了如下的设备端内核函数用于线状要素的化简。
__kernel void clSimplify (__global double * inBufX,
__global double * inBufY,
__global double * outBuf,
__global int * numPts,
__global int * offset,
const uint count)
上述函数中,__kernel表示这个函数是GPU设备上的函数,只能运行在GPU设备端,__global代表此缓冲区是全局缓冲区,其中,参数inBufX表示所有线状要素的横坐标数组;inBufY表示所有线状要素的纵坐标数组;outBuf表示每个点的垂距,为输出参数;numPts代表所有线状要素点的个数的数组;offset代表所有线状要素第一个点坐标再整个数组中的索引位置的数组;count为线状要素的个数。当GPU设备端计算结束后,将计算结果outBuf从设备端拷贝到主机端内存,缓冲区拷贝使用clEnqueueReadBuffer函数。这样,完成了整个图层的矢量数据化简。
3实验分析
3.1 单核算法与多核算法的比较
本实验环境如下所示,操作系统:Windows 7,CPU:Intel(R) Core(TM) i5-2300 CPU @ 2.80GHz,四核;内存:4 GB;编程环境:Visual Studio 2008;编程语言:C++。为了保证实验的可靠性,分别选取不同大小的数据作为测试数据。
不同大小的Shapefile矢量数据进行化简处理,阈值设为0米,图3-3是在执行串行算法和多核(4核)并行算法时CPU的使用率情况,表3-1中列出了采用串行算法和基于OpenMP的不同CPU核数下并行算法的时间对比。
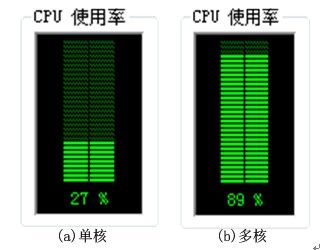
图3-1串行与并行时CPU的使用率
表3-1算法执行时间对比表
| 数据大小 |
耗时(ms) |
|||
| 串行 |
并行(OpenMP) |
|||
| 2核 |
3核 |
4核 |
||
| 9.91MB |
24243 |
12776 |
11139 |
10702 |
| 1.11MB |
2060 |
1138 |
1108 |
1123 |
| 668KB |
1358 |
749 |
733 |
732 |
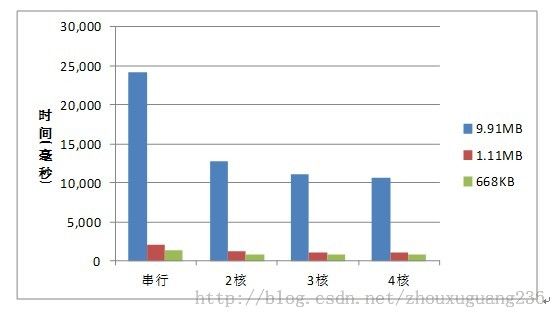
图3-2 算法执行时间对比图
从图3-1可以看出,当执行串行算法时,由于计算任务只分配到一个CPU上,所以CPU的使用率大约为四分之一,而当执行多核并行算法时,任务分配到各个CPU上,所以CPU的使用率接近100%。因此,多核并行计算充分利用了多核CPU的计算资源,发挥了多核CPU的优势。从表3-1和图3-2的测试结果可以看出,基于OpenMP的多核并行算法比传统的串行算法效率要高,当用两个CPU执行算法时,执行时间大约减少为原来的一半,其性能改善的效果比较明显,几乎为原来的一倍。当参与计算的CPU个数增加为3个或4个时,性能提升的效果不是很明显,原因是OpenMP采用的是Fork-Join的并行执行模式,当CPU增加时,线程数量也会增加,从而也会相应的增加线程创建和销毁的开销。另一方面,可以看出当数据量比较大时,性能提升的效果稍好一些,并且随着线程数量的增多,性能有提升的趋势。
3.2 串行与GPU并行算法的比较
为了验证基于OpenCL的GPU并行化简算法性能的提升,本实验的环境如下。操作系统:Windows 7,CPU:Intel(R) Core(TM) i5-2300 CPU @ 2.80GHz,四核;内存:4 GB;显卡:NVIDIA GeForce GT 420;编程环境:Visual Studio 2008,编程语言:C++。OpenCL底层的计算设备是NVIDIA公司的显卡设备,CUDA为所依赖的编程接口。试验分别选取了不同大小的数据作为测试数据。表3-2显示了串行化简执行的时间和GPU执行的时间对比。
表3-2串行与GPU并行执行时间对比
| 数据大小 |
串行耗时(ms) |
并行耗时(ms) |
加速比 |
| 9.91MB |
24243 |
3572 |
6.787 |
| 1.11MB |
2060 |
327 |
6.300 |
| 56KB |
156 |
77 |
2.026 |
从表3-2可以看出,通过利用GPU设备的高度并行性,可以极大地提高矢量数据化简的效率,提高服务器响应的速度。当数据量比较小时,GPU优势的发挥不是很明显,加速比只有2.0左右,但是随着数据的逐渐增大,加速比也逐渐增大,最高达到6.787。由此可以得出,GPU对于大数据量的并行效果比较好,并且在一定限度范围内,数据量越大,并行性越好,性能提升的空间也越大。
4 总结
在多核环境下和GPU环境下实现了矢量数据化简算法,性能得到了较大提升,结果表明并行计算应用于矢量数据化简取得了较好的效果,是矢量数据化简今后的一个发展方向。