《使用Python进行自然语言处理》学习笔记七
第五章 分类和标注词汇
5.1 使用词性标注器
1 POS概述
将词汇按它们的词性(parts-of-speech , POS)分类以及相应的标注它们的过程被称为词性标注(part-of-speech tagging, POS tagging )或干脆简称标注。词性也称为词类或词汇范畴。 用于特定任务的标记的集合被称为一个标记集。一个词性标注器(part-of-speech tagger 或 POS tagger)处理一个词序列,为每个词附加一个词性标记。
text.similar() 方法为一个词 w 找出所有上下文 w1ww2,然后找出所有出现在相同上下文中的词 w',即 w1w'w2,就是找到上下文一致的词性和用法很大可能相同的词
代码参考NltkTest173. TaggerTest
不过不得不多查找相似词的函数还是需要相当的遍历的,需要的时间比较长,需要大量操作的需要注意这一点。
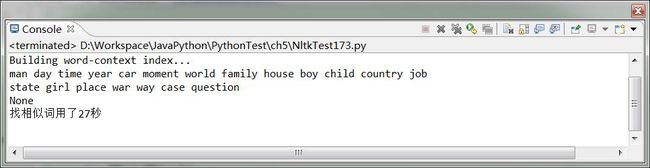
打印的即如果里面有个None,这是为什么呢?合理的解释是text.similar('woman')其实得到了两个[],一个是有内容的[man,day….question]还有一个是[None],那又为什么会得到None呢?水平有限,只得先按下不表。
5.2标注语料库
5.3 使用 Python 字典映射词及其属性
1 索引链表 VS 字典
链表的一个点可以有几个属性,字典的一个点指定的属性只能是一个。
2 定义字典
pos ={'colorless': 'ADJ', 'ideas': 'N', 'sleep': 'V', 'furiously': 'ADV'}
3 递增地更新字典
这是词袋模型的惯用方法,因为不需要关心语序,所以直接给各个词计数就行了。
5.4 自动标注
不是研究的重点,需要的话使用公开的方法即可。
5.5 N-gram 标注
1 一元标注(Unigram Tagging )
一元标注器基于一个简单的统计算法:对每个标识符分配这个独特的标识符最有可能的标记。
2 一般的 N-gram 的标注
一个 n-gram 标注器挑选在给定的上下文中最有可能的标记。
5.6 基于转换的标注
5.7 如何确定一个词的分类
#-*- coding: utf-8-*-
'''
Created on 2014-3-14
@author: liTC
'''
from __future__ import division
import nltk
import time
import datetime
from nltk.corpus import brown
from operator import itemgetter
class NltkTest173:
def __init__(self):
print 'Initing...'
def TaggerTest(self):
text1 = nltk.word_tokenize("And now for something completely different")
print nltk.pos_tag(text1)
starttime = datetime.datetime.now()
text2 = nltk.Text(word.lower() for word in nltk.corpus.brown.words())
print text2.similar('woman')
endtime = datetime.datetime.now()
print '找相似词用了%d秒' %(endtime - starttime).seconds
nt173=NltkTest173()
nt173.TaggerTest()