ATL技术内幕 第四部分
前言:这一系列博客翻译自 The Code Project 上的文章,作者是Zeeshan amjad。
题目:ATL Under the Hood - Part 4
原文链接:http://www.codeproject.com/Articles/2387/ATL-Under-the-Hood-Part-4
介绍
目前为止我们还没有讨论汇编语言。但如果想知道ATL的内幕,这是不可避免的。因为ATL用了一些底层的技术和一些内联的汇编语言来提速和减少代码量。我假设读者已经具备了基本的汇编语言基础以便将重点集中在我的主题上,而不是去讲解汇编语言本身。如果你不了解汇编,强烈建议你看看Matt Pietrek在1998年2月的微软系统日志的文章 ”Under The Hood”,其中讲解了大量的汇编语言。
首先看下面这个简单的程序:
程序 55
void fun(int, int) { } int main() { fun(5, 10); return 0; }
现在,我们用命令行编译器cl.exe编译该程序,编译时添加-FAs选项。比如,如果这个程序的名字是prog55,按照下面的方式编译:
Cl -FAs prog55.cpp
这条语句将产生于源文件同名的.asm文件,里面包含了如下的汇编代码。我们首先看看函数调用。调用这个fun函数的汇编代码如下:
push 10 ; 0000000aH push 5 call ?fun@@YAXHH@Z ; fun
首先将函数参数自右向左压入栈,然后再调用函数。但是函数名不一样了,这是因为c++编译器会修饰函数以便执行函数重载。下面是个函数重载的例子:
程序 56
void fun(int, int) { } void fun(int, int, int) { } int main() { fun(5, 10); fun(5, 10, 15); return 0; } 这种情况下,在调用两个函数时,其汇编代码分别如下: push 10 ; 0000000aH push 5 call ?fun@@YAXHH@Z ; fun push 15 ; 0000000fH push 10 ; 0000000aH push 5 call ?fun@@YAXHHH@Z ; fun
看看函数名,我们用了相同的名字,但编译器会自行修饰以便进行重载。
如果不想让编译器修饰你的函数名,在定义函数时,添加 extern“C”标识。看看下面的例子:
程序 57
extern "C" void fun(int, int) { } int main() { fun(5, 10); return 0; }
汇编代码如下:
push 10 ; 0000000aH push 5 call _fun
这意味着你将利用C链接,不可以重载你的函数了。看看下面的例子:
程序58
extern "C" void fun(int, int) { } extern "C" void fun(int, int, int) { } int main() { fun(5, 10); return 0; }
上述代码将报出编译错误,因为C语言不支持函数重载。你用了相同的函数名且不让编译器修饰,将导致使用C链接而非C++链接。
现在看看编译器对空函数产生了什么代码。下面是编译器产生的代码:
push ebp mov ebp, esp pop ebp ret 0
当你或者编译器向栈中推入值时,对寄存器有什么影响呢?看看下面简单的例子。
程序 59
#include <cstdio> int g_iTemp; int main() { fun(5, 10); _asm mov g_iTemp, esp printf("Before push %d\n", g_iTemp); _asm push eax _asm mov g_iTemp, esp printf("After push %d\n", g_iTemp); _asm pop eax return 0; }
程序输出结果为:
Before push 1244980 After push 1244976
这个程序显示了在推入栈前后,寄存器ESP的值的变化。结果显示,当你向栈中推入值时,ESP的值向下增长。
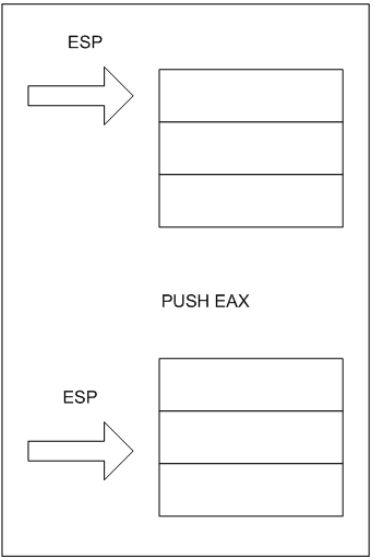
问题是,当我们传递给函数参数后,谁来恢复栈指针呢?是函数本身还是其调用者呢?实际上两者皆有可能。这也是标准调用和C调用的区别所在。看看如下语句,注意函数调用后面的那条:
push 10 ; 0000000aH push 5 call _fun add esp, 8
我们有两个参数传递给函数,所以在推入堆栈后,栈指针就会减8,在这个程序中,调用者负责设置栈指针。这就叫做C调用。在这种调用规则下,无可辩驳,你可以传递变量,因为调用者知道你传递了几个参数,所以在调用结束后知道如何设置栈指针。
然而,如果选择了标准调用,那被调用者将有责任清除栈(也就是恢复栈指针)。在这种情况下,你当然不可以传递任何参数,因为没办法知道有几个参数传给了函数,所以调用函数时,需要适当的设置栈指针。
通过如下例子看看标准调用的行为:
程序 60
extern "C" void _stdcall fun(int, int) { } int main() { fun(5, 10); return 0; }
看看函数调用:
push 10 ; 0000000aH push 5 call _fun@8
函数名后的@显示,这是标准调用,8显示了推入栈的字节数,我们可以通过这个数除4得到传给函数的参数个数。
空函数汇编代码如下:
push ebp mov ebp, esp pop ebp ret 8
这个函数同个“ret 8”这条语句,在退出之前,自己恢复了栈指针。
现在我们来研究一下编译器为我们产生的代码。在标准调用中,编译器插入这些代码来构建栈框架,以便我们能获取参数以及函数的局部变量。栈框架是专为函数保留的一片内存区域,用来存储函数参数,局部变量以及返回地址等。栈框架经常在调用新函数的时候创建,函数返回时销毁。在8086体系结构中,EBP寄存器用来存储栈结构的地址,有时又叫栈指针。
所以,编译器首先保存前一个函数栈构架的地址,再利用当前的ESP值创建一个新的栈构架。在函数调用返回之前,先前的栈构架将处于受保护状态。
现在看看什么事栈构架。栈构架在EBP的+ve一侧存储了所有的参数,在-ve的一侧存储了所有的局部变量。
所以,函数的返回地址保存在EBP中,前一个栈结构保存在EBP+4中。看看下面函数调用,其中有2个参数,3个局部变量:
程序 61
extern "C" void fun(int a, int b) { int x = a; int y = b; int z = x + y; return; } int main() { fun(5, 10); return 0; }
看看编译器产生的代码:
push ebp mov ebp, esp sub esp, 12 ; 0000000cH ; int x = a; mov eax, DWORD PTR _a$[ebp] mov DWORD PTR _x$[ebp], eax ; int y = b; mov ecx, DWORD PTR _b$[ebp] mov DWORD PTR _y$[ebp], ecx ; int z = x + y; mov edx, DWORD PTR _x$[ebp] add edx, DWORD PTR _y$[ebp] mov DWORD PTR _z$[ebp], edx mov esp, ebp pop ebp ret 0
_x,_y是在函数定义之上定义的:
_a$ = 8 _b$ = 12 _x$ = -4 _y$ = -8 _z$ = -12
意味着你可以这样读取这些值:
; int x = a; mov eax, DWORD PTR [ebp + 8] mov DWORD PTR [ebp - 4], eax ; int y = b; mov ecx, DWORD PTR [ebp + 12] mov DWORD PTR [ebp - 8], ecx ; int z = x + y; mov edx, DWORD PTR [ebp - 4] add edx, DWORD PTR [ebp - 8] mov DWORD PTR [ebp - 12], edx
这就意味着,函数参数a和b分别为EBP + 8 andEBP + 12 . 而x,y,z的值分别保存在EBP - 4,EBP - 8, EBP – 12。
有了这些知识,我们看看如下例子:
程序 62
#include <cstdio> extern "C" int fun(int a, int b) { return a + b; } int main() { printf("%d\n", fun(4, 5)); return 0; }
这个程序结果可以预测为输出“9”,下面我们稍作修改:
程序 63
#include <cstdio> extern "C" int fun(int a, int b) { _asm mov dword ptr[ebp+12], 15 _asm mov dword ptr[ebp+8], 14 return a + b; } int main() { printf("%d\n", fun(4, 5)); return 0; }
这个程序输出结果为“29”。我们知道函数参数的地址,所以我们通过其地址修改了参数的值。所以,我们将a与b相加时,将会是15与14相加。
Vc对于函数调用设置了裸属性。如果设这了裸属性,它将不产生任何prolog和 epilog代码。那什么是prolog和 epilog代码呢?prolog代码意思是“opening”,这在AI中也是编程语言的名字。但这里的名字与那个没有任何关联,prolog代码由编译器产生。这些代码是编译器自动插入到函数调用最开始的用来设置栈构架的。看看陈程序61中产生的汇编代码。在函数最开始,编译器自动插入了如下代码来设置栈构架:
push ebp mov ebp, esp sub esp, 12 ; 0000000cH
这就叫做prolog代码。同样的方式,在函数调用结束前插入的代码,叫做Epilog代码。上述同样程序中的Epilog代码如下:
mov esp, ebp pop ebp ret 0
作为对比,我们看看裸属性的函数调用示例: attribute
程序 64
extern "C" void _declspec(naked) fun() { _asm ret } int main() { fun(); return 0; }
编译器产生的函数相关代码如下:
_asm ret
也就是在该函数中没有prolog和epilog代码产生。实际上对于裸属性函数,有一些规则,比如不可以在裸函数内部申明自动变量,因为局部变量要求编译器产生特定代码,而裸函数却又要求编译器不产生任何代码。实际上,你必须写返回值,以便函数不会崩溃。你甚至不能在裸函数中写返回语句,因为当你想返回某些值时,编译器将其放入寄存器eax中,所以意味着编译器必须为你的返回语句产生代码。我们看看下面的例子。
程序 65
#include <cstdio> extern "C" int sum(int a, int b) { return a + b; } int main() { int iRetVal; sum(3, 7); _asm mov iRetVal, eax printf("%d\n", iRetVal); return 0; }
输出结果是10,我们没有直接用函数的返回值,而是在调用函数后复制了eax寄存器内部的值。
现在,我们在裸函数内部自己添加prolog和epilog,用来返回两个参数的和:
Program 66
#include <cstdio> extern "C" int _declspec(naked) sum(int a, int b) { // prolog code _asm push ebp _asm mov ebp, esp // code for add two variables and return _asm mov eax, dword ptr [ebp + 8] _asm add eax, dword ptr [ebp + 12] // epilog code _asm pop ebp _asm ret } int main() { int iRetVal; sum(3, 7); _asm mov iRetVal, eax printf("%d\n", iRetVal); return 0; }
程序输出结果为“10”。
这个属性在ATLBASE.H文件中用来实现_QIThunk结构的成员。在_ATL_DEBUG_INTERFACES宏定义的前提下,这个结构用来调试ATL函数的引用计数。