http负载均衡/反向代理下常见的Session管理策略
引言
对于高性能Web系统而言,分布式的架构似乎是一种不可阻挡的趋势。在对于并发量巨大,而单个事务处理逻辑简单、计算量很小的系统而言,采用http负载均衡/反向代理是一种非常有效而且常用的手段。
首先,让我们看看,什么是http负载均衡,http://baike.baidu.com/view/51184.htm,什么是反向代理,http://baike.baidu.com/view/1165595.htm。
在本文中,我们不谈及具体的技术(例如Apache与Tomcat,还是Nginx),我们只从理论的角度,相对抽象地谈论 常见的几种Session策略。
一般而言,在高性能Web系统中,负载均衡与反向代理下Session策略主要有以下几种解决方案:
- Sticky Session;
- 集中式Session;
- 使用Cookie而非Session;
StickySession
Sticky Session,顾名思义,即粘性Session,具体而言,Session粘在了具体处理某个业务的应用服务器上。采用这种策略时,某一个用户所有的请求都会映射到某一台应用服务器。无论这台服务器是否是非常空闲,还是非常繁忙,这台机器上的用户请求仍然会再次映射到这台机器上。因此,我们可以看出,在这种策略下,用户数不是特别庞大或者用户比较集中(这与用户的IP或者用户名有关)的情况,各台应用服务器的负载并不是非常的均衡。这种策略的架构图如下:
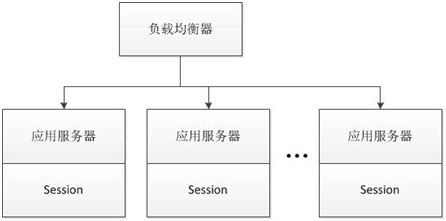
- 实现简单。这种方式的实现也非常简单,只需要对负载均衡器进行一定的配置便可,而不需要对业务系统做出任何的修改;
- 计算代价小。大家都知道,Hash算法都已经是非常成熟,而且选择很多,对于负载均衡器而言,其计算量是非常小的。较小的计算量,在一定程度上,也就意味着更大的负载量。
- 负载很难达到均衡。在这种策略下,如果某一个Hash值所对应的客户机特别多时,或者如果某一个Hash值所对应的客户机的请求数特别多(一般而言,总会有一些用户特别活跃,一些用户并不活跃,如果特别活跃的用户都被映射到同一台应用服务器时,那台应用服务器就会负载加重),这一台应用服务器的负载也会相应较重一些;
- 不稳定。首先,当某一台应用服务器宕机时,注定某一些Session会丢失,而且是不可避免地会丢失。这些用户可能需要重新登陆系统,而且之间保存在Session中的数据 全部丢失。如果对于一个非常强调稳定性的系统,这种情况是不可容忍的。设想一下,某一台电子商务应用服务器宕机,这上面的用户全部下线,上面的所有Session信息都会丢失。再次,如果一个用户所用的网络是双链路的。这种情况在公司里是非常常见的,因为在一家公司里,可能会由于带宽、稳定性等要求会架设双链路的网络。这样,也就意味着,一个用户可能会通过两种网络来连接到服务器,也即这个用户可能会有两个不同的IP,也会拥有两个不同的Hash值,可能会在不同的时间映射到不同的应用服务器。其后果,我想大家已经想象到了。
这种Hash策略的原理也非常容易想象,不再是用户的IP地址或者用户名,而根据用户登陆系统的时间来进行Hash。同样,首次登陆时间的提供主要有两种方式,一种是每一个请求URL都会带上自己的登陆时间,第二种是将登陆时间放在客户端的Cookie中。在第二种方法中,如果客户端不提供Cookie,那这种策略将会无法执行。
集中式Session
集中式Session,顾名思义,将集群中所有用户机的Session都保存在同一台机器上(Session服务器)。此时,在这种策略下,各台应用服务器所取Session的方式需要有所改变。比如,在Java/J2EE项目中,取Session通过HttpServletRequest类的getSession()方法来获得的。如果采用集中式Session策略,则不再采用这种获取Session方式。此时,系统需要实现一个interface,比如:public interface SessionHolder {
public HttpSession getSession(Object key);
}
通过getSession方法来获取session,参数key可以为用户的IP、用户名等,只要能标识这个用户便可。一般采用用户名作为参数key。但传入的key所指的session不存在时,new一个Session返回给调用者;如果存在时,则将存在的Session返回给调用者。在这种策略下,一般来说,这里的HttpSession是需要用户对javax.servlet.http.HttpSession实现,或者干脆为一个Map的实现都可以。因为调用者对Session的第一感受,便觉得Session是一个Map。对于这种策略下,用户请求可以以任何一种方式来进行映射。如果对于一般的负载均衡器而言,在这种策略下,更适合轮询的方法,即每一台应用服务都依次获取请求列表中的请求。或者,更进一步,考虑到各台应用服务的硬件配置或者业务处理能力,而增加weight值(权值),这种方式在Nginx中得到了很好的支持。 在这种策略下,系统的架构如下:
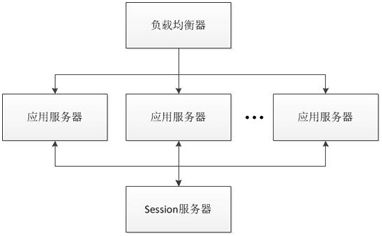
集中式Session策略也可以与Session Sticky相结合,以下流程图示例:

同样,此时,系统依然很难达到负载均衡。因为这种方式本质上依然是IP Hash的策略,只是将Session集中存储在同一台机器。但是,当应用服务器宕机时,这台应用 服务器上的用户Session可以通过用户再次登陆而恢复。在一定程度上,稳定性有所提高。
集中式Session策略也可以独自执行,流程大致如下:
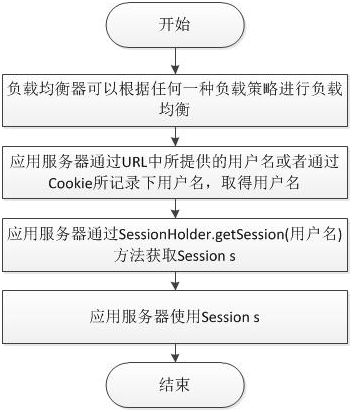
在以上流程中,笔者以用户名为SessionHolder.getSession(key)的参数,因而依然需要提供登陆用户的用户名,主要通过URL中所提供或者Cookie中记录的方式。我们在使用某一些Web服务时,会发现URL中都会带有UserName或者UserID,所以笔者猜测,这种Web服务采用的就是这种策略。
对于集中式Session,一般系统设计人员最关心的便是Session的存储方式。Session存储一般有以下几种方式:
1. Key/ValueStorage
一般,大型Web系统会采用Key/ValueStorage的方式存储Session。在这种存储方式的选择中,大多数的大型Web系统会选择memcached。原因非常简单,大多数的K/V存储中,key与value都可支持Object,也即可以直接存取对象。这意味着,Session可以不做任何处理,直接交给Key/Value Storage去存储。因而,大多数的Key/ValueStorage系统都提供非常友好的API,使用非常方便。笔者作为一个忠实的NoSQL Fan非常支持这种方式。
这种方式的优点在于:
- 多数的Key/Value Storage支持Object作为它的Key或者Value;
- 多数的Key/Value Storage提供非常友好的API;
- Key/Valuestorage速度一般都远高于关系型数据库,非常适合Session这种存取非常频繁的情况,例如memcached支持全内存的工作方式,速度非常快;
- 多数的Key/Value Storage支持良好的备份与恢复机制;
- 多数的Key/Value Storage支持集群工作的方式,此时Session的总量也就不再局限于单Session服务器的内存大小。
这种方式的缺点在于:
- Key/ValueStorage部署有一定的复杂;
- 多数Key/Value Storage对于CPU与内存的消耗较多;
在使用这种方式时,需要注意以下几点:
- Key/ValueStorage对Object(对象)大小的限制。很多Key/ValueStorage会对所存储的对象的大小有所限制,比如memcached中,默认配置下单个对象的最大大小为 1MB;
- 当与Session服务器的连接断开或者Session服务器宕机时的异常处理。
2. 关系型数据库
Session存储于传统的关系型数据库中。而对于关系型数据库中不能直接存储对象,因而对于同一个Session必须使用一组的record进行存储。SessionRecord可以采用以下的sql进行创建:
Create table sessionRecord{
userId bigint not null,
key varchar(255) not null,
value varchar(255) not null,
primary key(userId,key)
};
但是,对于value而言,在这种存储方式下,Session中的value必须为String,int,long等这种类型。如果需要支持对其它Object类型的value进行存储时,必须使其支持对象
与String类型之间的转换。这无疑增加了开发成本。
这种方式的优点在于:
- 部署简单。就一般而言,关系型数据库的部署还是要比Key/Value Storage要简单一点;
- 对程序员友好。没有一个程序员不懂SQL,只要懂SQL就可以使用这种方式来存储Session,而不需要再花费时间去学习其它的存储技术。
这种方式的缺点在于:
- 关系型数据库比较重,其事务机制与一致性约束等都会消耗一定的性能。而Session是存取比较频繁的。很有可能Session服务器会成为整个系统的性能瓶颈;
- 备份配置比较复杂;
- 关系型数据库一般不支持集群工作方式(当然不太可能,在一个Web系统中,所有的Session的总容量超过一台机器的硬盘存储);
- Value的类型与大小受到表结构的影响。如果需要支持对其它Object类型的value进行存储时,必须使其支持对象与String类型之间的转换。这无疑增加了开发成本。如果修改为text类型,以支持更大容量的value 时,text类型使用sql操作的速度更慢。
在使用这种方式时,需要注意以下几点:
- 对象与String类型的转换时,可以采用现有的一些技术,比如对象与xml的转换可以使用DOM4J,对象与JSON之间的转换等;
3. 直接存储于内存
在使用这种方式时,可以直接使用HashTable。至于为什么使用HashTable而非HashMap,原因非常简单HashTable是线程安全的,而且HashTable不支持null作为key或者value。HashTable中key可以用户名/用户ID,value为这个用户的Session。
这种方式的优点在于:
- 实现简单;
- 速度快。这种方式无疑是这三种方式中最为快速的;
这种方式的缺点在于:
- 备份困难;
- 所有的数据都在同一台机器上,这台机器容易成为单点故障;
- Session集合的总容量受到Session服务器的内存大小限制;
- 难以以集群的方式进行工作;
使用Cookie而非Session
使用Cookie而非Session,这种策略也被称为客户端Session,即不将Session信息存储于服务器端,而是存储于客户端。这同时,也会带来一定的安全问题,因为Cookie是存储于客户端中的,也就意味着客户端可以修改Cookie文件,来进行Session劫持操作。为了应对这种问题,一般的处理方式都是对Cookie信息进行加密。当然,道高一尺,魔高一丈,Cookie的密码可能被破解,一旦破解,Session依然可能会劫持。安全性问题是这种策略最大的问题。
这种方式的优点在于:
- 节省服务器端的内存消耗。
这种方式的缺点在于:
- 安全性问题,Session容易被伪造或者劫持;
- 不可靠。如果客户端不支持Cookie,这种策略将无法执行;
- 浏览器对Cookie有严格的限制。比如在Microsoft IE中,每一个域名下的Cookie文件数量被限制在50个以下,每个Cookie文件的大小被限制在4095个字节(包括key、value、等号)。而几乎所有的浏览器忽略超过限制的Cookie文件。在实现这一种策略的时候,必须非常注意这一点。
总结
至此,笔者已经根据自己的经验与所学,总结了在Http负载均衡/反向代理下的常见Session管理策略,并对它们所具有的特点进行了分类与分析。当然,在具体的工程项目中,Session管理策略还是需要根据具体的情况而定,通过是以上几种方式的混合。
本博客中所有的博文都为笔者(Jairus Chan)原创。
如需转载,请标明出处:http://blog.csdn.net/JairusChan。
如果您对本文有任何的意见与建议,请联系笔者(JairusChan)。