Spark修炼之道(进阶篇)——Spark入门到精通:第一节 Spark 1.5.0集群搭建
作者:周志湖
网名:摇摆少年梦
微信号:zhouzhihubeyond
本节主要内容
- 操作系统环境准备
- Hadoop 2.4.1集群搭建
- Spark 1.5.0 集群部署
注:在利用CentOS 6.5操作系统安装spark 1.5集群过程中,本人发现Hadoop 2.4.1集群可以顺利搭建,但在Spark 1.5.0集群启动时出现了问题(可能原因是64位操作系统原因,源码需要重新编译,但本人没经过测试),经本人测试在ubuntu 10.04 操作系统上可以顺利成功搭建。大家可以利用CentOS 6.5进行尝试,如果有问题,再利用ubuntu 10.04搭建,所有步骤基本一致
1. 操作系统环境准备
(1)安装VMWare
下载地址:http://pan.baidu.com/s/1bniBipD
密码:pbdw
安装过程略
(2)下载操作系统并安装
Ubuntu 10.04操作系统下载地址:
链接:http://pan.baidu.com/s/1kTy9Umj 密码:2w5bCentOS 6.5下载地址:
下载地址:http://pan.baidu.com/s/1mgkuKdi
密码:xtm5本实验要求装三台:CentOS 6.5,可以分别安装,也可以安装完一台后克隆两台,具体过程略。初学者,建议三台分别安装。安装后如下图所示:
(3)CentOS 6.5网络配置
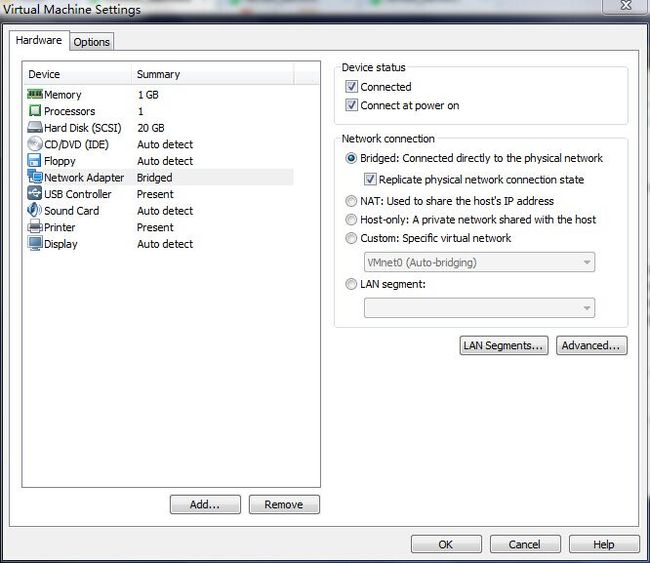
安装好的虚拟机一般默认使用的是NAT(关于NAT、桥接等虚拟机网络连接方式参见本人博客:http://blog.csdn.net/lovehuangjiaju/article/details/48183485),由于三台机器之间需要互通之外,还需要与本机连通,因此采用将网络连接方式设置为Bridged(三台机器相同的设置),如下图所法:
修改主机名
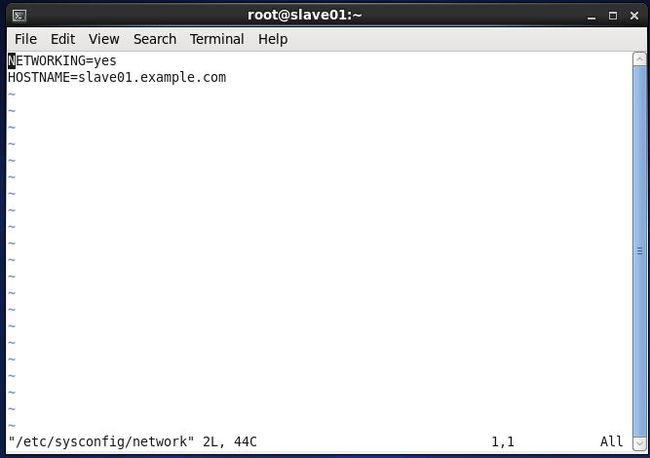
(1)修改centos_salve01虚拟机主机名:
vim /etc/sysconfig/network/etc/sysconfig/network修改后的内容如下:
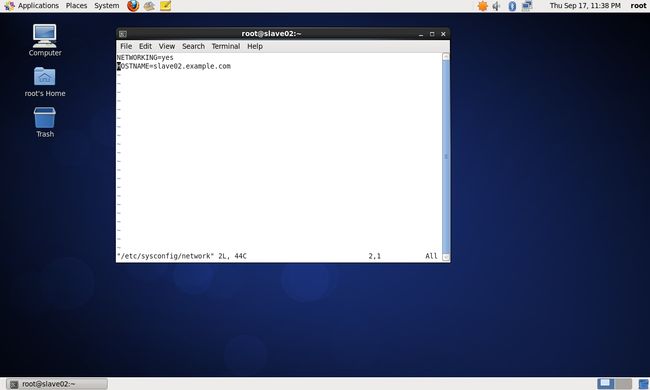
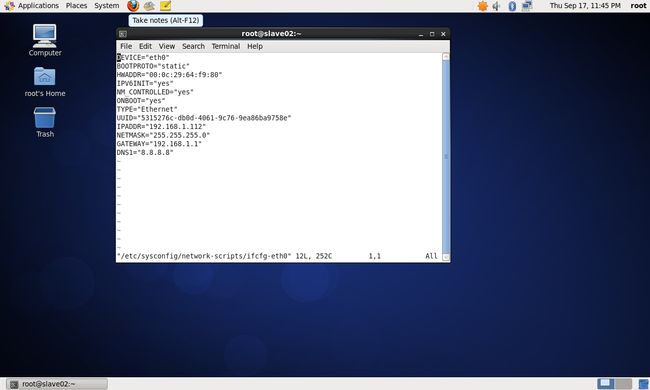
(2)vim /etc/sysconfig/network命令修改centos_slave02虚拟机主机名
/etc/sysconfig/network修改后的内容如下:
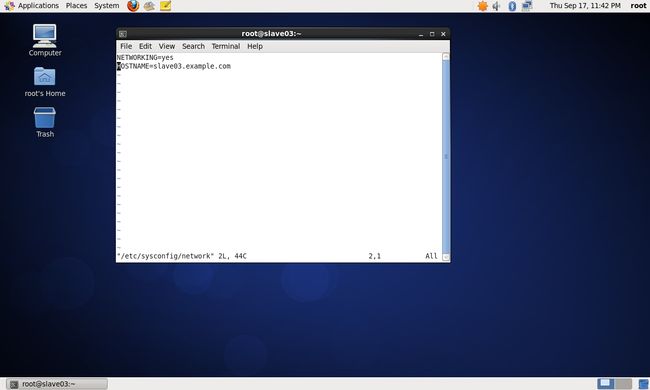
(3)vim /etc/sysconfig/network命令修改centos_slave03虚拟机主机名
/etc/sysconfig/network修改后的内容如下:
修改主机IP地址
在大家在配置时,修改/etc/sysconfig/network-scripts/ifcfg-eth0文件对应的BOOTPROT=static、IPADDR、NETMASK、GATEWAY及DNS1信息即可
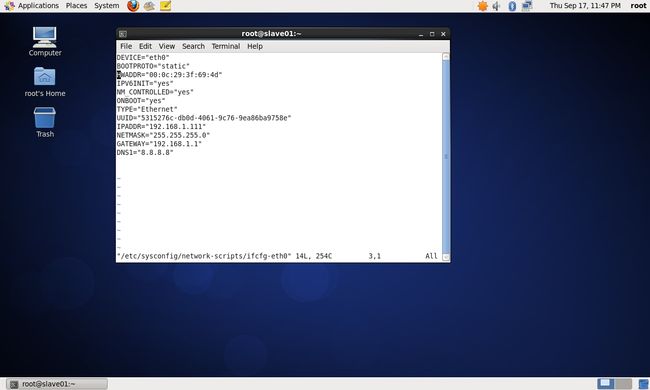
(1)修改centos_salve01虚拟机主机IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改后内容如下:
DEVICE="eth0"
BOOTPROTO="static"
HWADDR="00:0c:29:3f:69:4d"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="5315276c-db0d-4061-9c76-9ea86ba9758e"
IPADDR="192.168.1.111"
NETMASK="255.255.255.0"
GATEWAY="192.168.1.1"
DNS1="8.8.8.8"
(2)修改centos_salve02虚拟机主机IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改后内容如下:
DEVICE="eth0"
BOOTPROTO="static"
HWADDR="00:0c:29:64:f9:80"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="5315276c-db0d-4061-9c76-9ea86ba9758e"
IPADDR="192.168.1.112"
NETMASK="255.255.255.0"
GATEWAY="192.168.1.1"
DNS1="8.8.8.8"
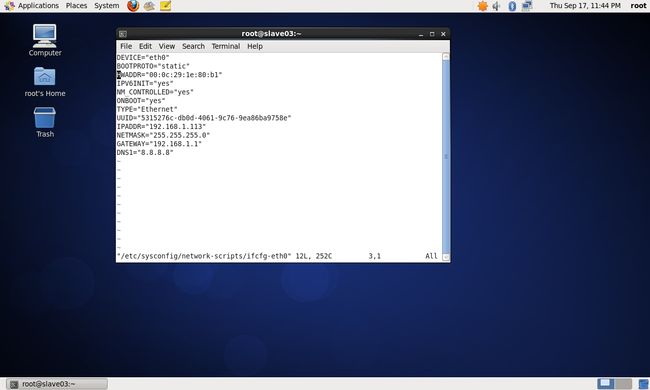
(3)修改centos_salve03虚拟机主机IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改后内容如下:
DEVICE="eth0"
BOOTPROTO="static"
HWADDR="00:0c:29:1e:80:b1"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="5315276c-db0d-4061-9c76-9ea86ba9758e"
IPADDR="192.168.1.113"
NETMASK="255.255.255.0"
GATEWAY="192.168.1.1"
DNS1="8.8.8.8"
/etc/sysconfig/network-scripts/ifcfg-eth0文件内容解析:
DEVICE=eth0 //指出设备名称
BOOTPROT=static //启动类型 dhcp|static,使用桥接模式,必须是static
HWADDR=00:06:5B:FE:DF:7C //硬件Mac地址
IPADDR=192.168.0.2 //IP地址
NETMASK=255.255.255.0 //子网掩码
NETWORK=192.168.0.0 //网络地址
GATEWAY=192.168.0.1 //网关地址
ONBOOT=yes //是否启动应用
TYPE=Ethernet //网络类型设置完成后,使用
service network restart命令重新启动网络,配置即可生效。
设置主机名与IP地址映射
(1)修改centos_salve01主机名与IP地址映射
vim /etc/hosts设置内容如下:
127.0.0.1 slave01.example.com localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 slave01.example.com
192.168.1.111 slave01.example.com
192.168.1.112 slave02.example.com
192.168.1.113 slave03.example.com
具体如下图: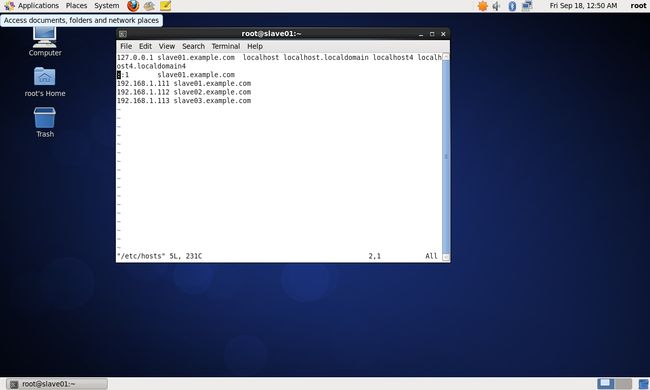
(2)修改centos_salve02主机名与IP地址映射
vim /etc/hosts设置内容如下:
127.0.0.1 slave02.example.com localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 slave02.example.com
192.168.1.111 slave01.example.com
192.168.1.112 slave02.example.com
192.168.1.113 slave03.example.com
具体如下图:
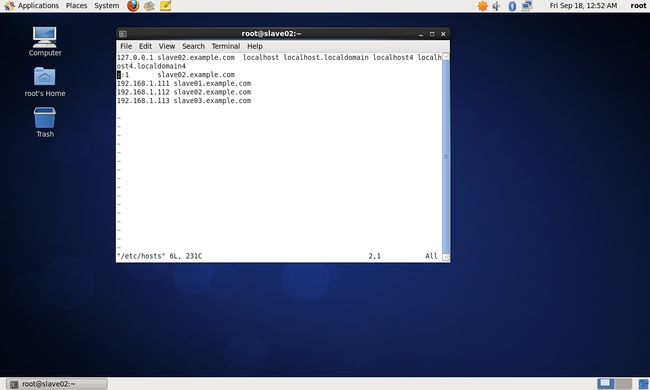
(3)修改centos_salve03主机名与IP地址映射
vim /etc/hosts设置内容如下:
127.0.0.1 slave03.example.com localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 slave03.example.com
192.168.1.111 slave01.example.com
192.168.1.112 slave02.example.com
192.168.1.113 slave03.example.com
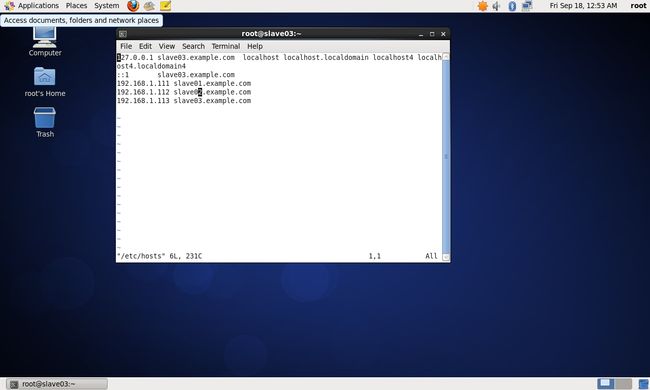
修改主机DNS
采用下列命令设置各主机DNS(三台机器进行相同的设置)
vim /etc/resolv.conf 设置后的内容:
# Generated by NetworkManager
search example.com
nameserver 8.8.8.8
8.8.8.8为Google提供的DNS服务器
网络连通测试
前面所有的配置完成后,重启centos_salve01、centos_salve02、centos_salve03使主机名设置生效,然后分别在三台机器上作如下测试命令:
下面只给出在centos_salve01虚拟机上的测试
[root@slave01 ~]# ping slave02.example.com
PING slave02.example.com (192.168.1.112) 56(84) bytes of data.
64 bytes from slave02.example.com (192.168.1.112): icmp_seq=1 ttl=64 time=0.417 ms
64 bytes from slave02.example.com (192.168.1.112): icmp_seq=2 ttl=64 time=0.355 ms
64 bytes from slave02.example.com (192.168.1.112): icmp_seq=3 ttl=64 time=0.363 ms
^C
--- slave02.example.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2719ms
rtt min/avg/max/mdev = 0.355/0.378/0.417/0.031 ms
[root@slave01 ~]# ping slave03.example.com
PING slave03.example.com (192.168.1.113) 56(84) bytes of data.
64 bytes from slave03.example.com (192.168.1.113): icmp_seq=1 ttl=64 time=0.386 ms
64 bytes from slave03.example.com (192.168.1.113): icmp_seq=2 ttl=64 time=0.281 ms
^C
--- slave03.example.com ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1799ms
rtt min/avg/max/mdev = 0.281/0.333/0.386/0.055 ms
测试外网的连通性(我在装的时候,8.8.8.8,已经被禁用….心中一万头cnm):
[root@slave01 ~]# ping www.baidu.com
ping: unknown host www.baidu.com
[root@slave01 ~]# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
From 192.168.1.111 icmp_seq=2 Destination Host Unreachable
From 192.168.1.111 icmp_seq=3 Destination Host Unreachable
From 192.168.1.111 icmp_seq=4 Destination Host Unreachable
From 192.168.1.111 icmp_seq=6 Destination Host Unreachable
From 192.168.1.111 icmp_seq=7 Destination Host Unreachable
From 192.168.1.111 icmp_seq=8 Destination Host Unreachable
(4)SSH完密码登录
#### (1) OpenSSH安装
如果大家在配置时,ping 8.8.8.8能够ping通,则主机能够正常上网;如果不能上网,则将网络连接方式重新设置为NAT,并修改网络配置文件为dhcp方式。在保证网络连通的情况下执行下列命令:
yum install openssh-server#### (2) 无密码登录实现
使用以下命令生成相应的密钥(三台机器进行相同的操作)
ssh-keygen -t rsa 执行过程一直回车即可
[root@slave01 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
4e:2f:39:ed:f4:32:2e:a3:55:62:f5:8a:0d:c5:2c:16 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| E |
| + |
| o = |
| . + . |
| S . . |
| + X . |
| B * |
| .o=o. |
| .. +oo. |
+-----------------+
生成的文件分别为/root/.ssh/id_rsa(私钥)、/root/.ssh/id_rsa.pub(公钥)
完成后将公钥拷贝到要免登陆的机器上(三台可进行相同操作):
ssh-copy-id -i slave01.example.com
ssh-copy-id -i slave02.example.com
ssh-copy-id -i slave03.example.com2. Hadoop 2.4.1集群搭建
集群搭建相关软件下载地址:
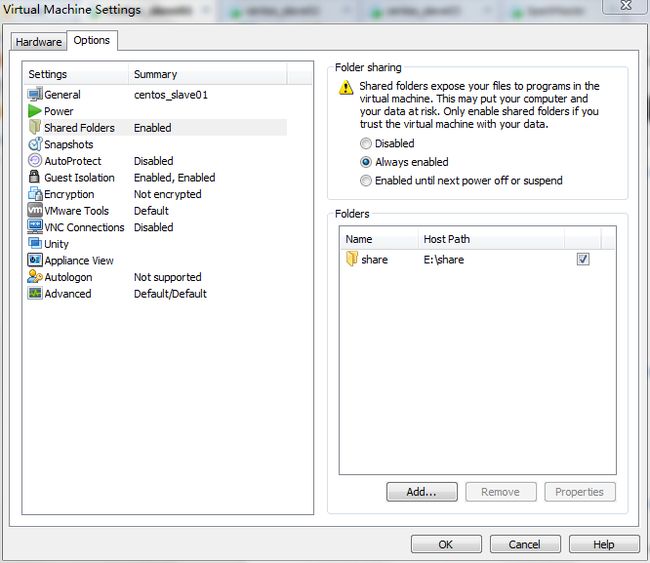
链接:http://pan.baidu.com/s/1sjIG3b3 密码:38gh下载后将所有软件都放置在E盘的share目录下:
设置share文件夹为虚拟机的共享目录,如下图所示:
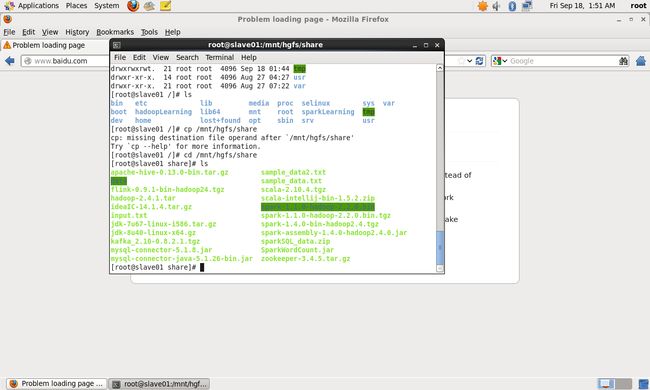
在linux系统中,采用
[root@slave01 /]# cd /mnt/hgfs/share
[root@slave01 share]# ls命令可以切换到该目录下,如下图
Spark官方要求的JDK、Scala版本
Spark runs on Java 7+, Python 2.6+ and R 3.1+. For the Scala API, Spark 1.5.0 uses Scala 2.10. You will need to use a compatible Scala version (2.10.x).(1)JDK 1.8 安装
在根目录下创建sparkLearning目前,后续所有相关软件都放置在该目录下,代码如下:
[root@slave01 /]# mkdir /sparkLearning
[root@slave01 /]# ls
bin etc lib media proc selinux sys var
boot hadoopLearning lib64 mnt root sparkLearning tmp
dev home lost+found opt sbin srv usr
将共享目录中的jdk安装包复制到/sparkLearning目录
[root@slave01 share]# cp /mnt/hgfs/share/jdk-8u40-linux-x64.gz /sparkLearning/
[root@slave01 share]# cd /sparkLearning/
//解压
[root@slave01 sparkLearning]# tar -zxvf jdk-8u40-linux-x64.gz
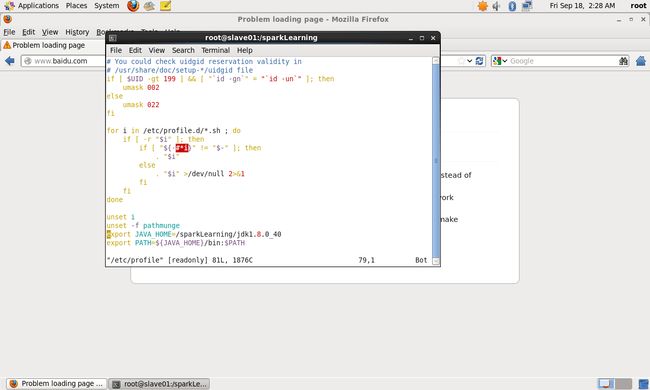
设置环境变量:
[root@slave01 sparkLearning]# vim /etc/profile在文件最后添加:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40
export PATH=${JAVA_HOME}/bin:$PATH如下图:
测试配置是否成功:
//使修改后的配置生效
[root@slave01 sparkLearning]# source /etc/profile
//环境变量是否已经设置
[root@slave01 sparkLearning]# $JAVA_HOME
bash: /sparkLearning/jdk1.8.0_40: is a directory
//测试java是否安装配置成功
[root@slave01 sparkLearning]# java -version
java version "1.8.0_40"
Java(TM) SE Runtime Environment (build 1.8.0_40-b25)
Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)
(2)Scala 2.10.4 安装
//复制文件到sparkLearning目录下
[root@slave01 sparkLearning]# cp /mnt/hgfs/share/scala-2.10.4.tgz .
//解压
[root@slave01 sparkLearning]# tar -zxvf scala-2.10.4.tgz > /dev/null
[root@slave01 sparkLearning]# vim /etc/profile将/etc/profile文件末尾内容修改如下:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40
export SCALA_HOME=/sparkLearning/scala-2.10.4
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH测试Scala是否安装成功
[root@slave01 sparkLearning]# source /etc/profile
[root@slave01 sparkLearning]# $SCALA_HOME
bash: /sparkLearning/scala-2.10.4: is a directory
[root@slave01 sparkLearning]# scala -version
Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
(3)Zookeeper-3.4.5 集群搭建
[root@slave01 sparkLearning]# cp /mnt/hgfs/share/zookeeper-3.4.5.tar.gz .
[root@slave01 sparkLearning]# tar -zxvf zookeeper-3.4.5.tar.gz > /dev/null
[root@slave01 sparkLearning]# cp zookeeper-3.4.5/conf/zoo_sample.cfg zoo.cfg
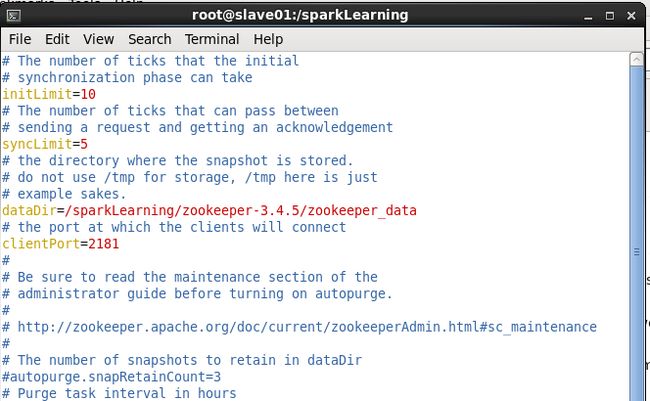
[root@slave01 sparkLearning]# vim zoo.cfg
修改dataDir为:
dataDir=/sparkLearning/zookeeper-3.4.5/zookeeper_data 在文件末尾添加如下内容:
server.1=slave01.example.com:2888:3888
server.2=slave02.example.com:2888:3888
server.3=slave03.example.com:2888:3888
如图所示:

创建ZooKeeper集群数据保存目录
[root@slave01 sparkLearning]# cd zookeeper-3.4.5/
[root@slave01 zookeeper-3.4.5]# mkdir zookeeper_data
[root@slave01 zookeeper-3.4.5]# cd zookeeper_data/
[root@slave01 zookeeper_data]# touch myid
[root@slave01 zookeeper_data]# echo 1 > myid
将slave01.example.com(centos_slave01)上的sparkLearning目录拷贝到另外两台服务器上:
[root@slave01 /]# scp -r /sparkLearning slave02.example.com:/
[root@slave01 /]# scp -r /sparkLearning slave03.example.com://etc/profile文件也进行覆盖
[root@slave01 /]# scp /etc/profile slave02.example.com:/etc/profile
[root@slave01 /]# scp /etc/profile slave03.example.com:/etc/profile修改zookeeper_data中的myid信息:
//配置slave02.example.com上的myid
[root@slave01 /]# ssh salve02.example.com
[root@slave02 ~]# echo 2 > /sparkLearning/zookeeper-3.4.5/zookeeper_data/myid
[root@slave02 ~]# more /sparkLearning/zookeeper-3.4.5/zookeeper_data/myid
2
//配置slave03.example.com上的myid
[root@slave02 ~]# ssh slave03.example.com
Last login: Fri Sep 18 01:33:29 2015 from slave01.example.com
[root@slave03 ~]# echo 3 > /sparkLearning/zookeeper-3.4.5/zookeeper_data/myid
[root@slave03 ~]# more /sparkLearning/zookeeper-3.4.5/zookeeper_data/myid
3
如此便完成配置,下面对集群进行测试:
//在slave03.example.com主机上
[root@slave03 ~]# cd /sparkLearning/zookeeper-3.4.5/bin
[root@slave03 bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
//启动slave03.example.com上的ZooKeeper
[root@slave03 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave03 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
//在slave02.example.com主机上
[root@slave02 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
//查看zookeeper集群状态,如果Mode显示为follower或leader则表明配置成功
[root@slave02 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
//在slave01.example.com主机上
[root@slave01 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave01 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
//在slave03.example.com主机上zookeeper状态
[root@slave03 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /sparkLearning/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
(4)Hadoop 2.4.1 集群搭建
(1)Hadoop 2.4.1基本目录浏览
root@slave01 bin]# cp /mnt/hgfs/share/hadoop-2.4.1.tar.gz /sparkLearning/
[root@slave01 bin]# cd /sparkLearning/
[root@slave01 sparkLearning]# tar -zxvf hadoop-2.4.1.tar.gz > /dev/null
[root@slave01 sparkLearning]# cd hadoop-2.4.1
[root@slave01 hadoop-2.4.1]# ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
cd
[root@slave01 hadoop-2.4.1]# cd etc/hadoop/
[root@slave01 hadoop]# ls
capacity-scheduler.xml hdfs-site.xml mapred-site.xml.template
configuration.xsl httpfs-env.sh slaves
container-executor.cfg httpfs-log4j.properties ssl-client.xml.example
core-site.xml httpfs-signature.secret ssl-server.xml.example
hadoop-env.cmd httpfs-site.xml yarn-env.cmd
hadoop-env.sh log4j.properties yarn-env.sh
hadoop-metrics2.properties mapred-env.cmd yarn-site.xml
hadoop-metrics.properties mapred-env.sh
hadoop-policy.xml mapred-queues.xml.template
(2)将Hadoop 2.4.1添加到环境变量
使用命令:vim /etc/profile 将环境变量信息修改如下:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40
export SCALA_HOME=/sparkLearning/scala-2.10.4
export HADOOP_HOME=/sparkLearning/hadoop-2.4.1
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
(3)将Hadoop 2.4.1添加到环境变量
使用命令:vim hadoop-env.sh 将环境变量信息修改如下,在export JAVA_HOME修改为:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40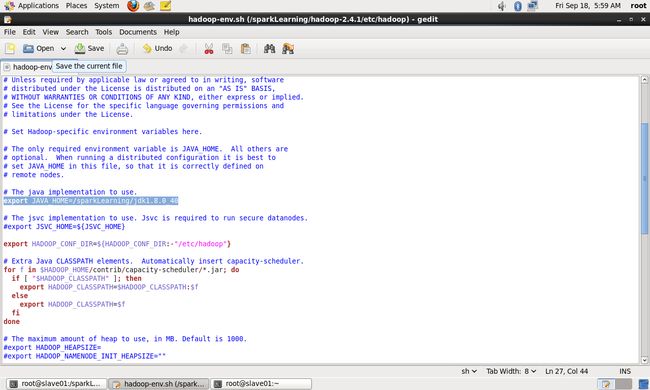
(4)修改core-site.xml文件
利用vim core-site.xml命令,文件内容如下:
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/sparkLearning/hadoop-2.4.1/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave01.example.com:2181,slave02.example.com:2181,slave03.example.com:2181</value>
</property>
</configuration>(5)修改hdfs-site.xml文件
vim hdfs-site.xml内容如下:
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>slave01.example.com:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>slave01.example.com:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave02.example.com:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave02.example.com:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave01.example.com:8485;slave02.example.com:8485;slave03.example.com:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/sparkLearning/hadoop-2.4.1/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>(4)修改mapred-site.xml文件
[root@slave01 hadoop]# cp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml修改文件内容如下:
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> (6)修改yarn-site.xml文件
<?xml version="1.0"?>
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>SparkCluster</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave01.example.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave02.example.com</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(7)修改slaves文件
slave01.example.com
slave02.example.com
slave03.example.com(8)配置文件拷贝到其它服务器
//slave01.example.com上的配置文件拷贝到slave02.example.com
[root@slave01 hadoop]# scp -r /etc/profile slave02.example.com:/etc/profile
profile 100% 2027 2.0KB/s 00:00
[root@slave01 hadoop]# scp -r /sparkLearning/hadoop-2.4.1 slave02.example.com:/sparkLearning/
//slave01.example.com上的配置文件拷贝到slave03.example.com
[root@slave01 hadoop]# scp -r /etc/profile slave03.example.com:/etc/profile
profile 100% 2027 2.0KB/s 00:00
[root@slave01 hadoop]# scp -r /sparkLearning/hadoop-2.4.1 slave03.example.com:/sparkLearning/
(9)启动journalnode
//使用下列命令启动journalnode
[root@slave01 hadoop]# hadoop-daemons.sh start journalnode
slave02.example.com: starting journalnode, logging to /sparkLearning/hadoop-2.4.1/logs/hadoop-root-journalnode-slave02.example.com.out
slave03.example.com: starting journalnode, logging to /sparkLearning/hadoop-2.4.1/logs/hadoop-root-journalnode-slave03.example.com.out
slave01.example.com: starting journalnode, logging to /sparkLearning/hadoop-2.4.1/logs/hadoop-root-journalnode-slave01.example.com.out
//JournalNode进程存在,启动成功
[root@slave01 hadoop]# jps
11261 JournalNode
11295 Jps
[root@slave01 hadoop]# ssh slave02.example.com
Last login: Fri Sep 18 05:33:05 2015 from slave01.example.com
[root@slave02 ~]# jps
6598 JournalNode
6795 Jps
[root@slave02 ~]# ssh slave03.example.com
Last login: Fri Sep 18 05:33:26 2015 from slave02.example.com
[root@slave03 ~]# jps
5876 JournalNode
6047 Jps
[root@slave03 ~]#
(10)格式化HDFS
登录slave02.example.com服务器,执行下列命令
[root@slave02 ~]# hdfs namenode -format
//下面是执行结果
15/09/18 06:05:26 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = slave02.example.com/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
STARTUP_MSG: classpath = /sparkLearning/hadoop-2.4.1/etc/hadoop:/sparkLearning/hadoop-........省略无关信息...............
STARTUP_MSG: build = http://svn.apache.org/repos/asf/hadoop/common -r 1604318; compiled by 'jenkins' on 2014-06-21T05:43Z
STARTUP_MSG: java = 1.8.0_40
.....................................................省略.....
/sparkLearning/hadoop-2.4.1/tmp/dfs/name has been successfully formatted.
15/09/18 06:05:30 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
15/09/18 06:05:30 INFO util.ExitUtil: Exiting with status 0
15/09/18 06:05:30 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at slave02.example.com/127.0.0.1
************************************************************/
(11)格式化HDFS信息复制到slave03.example.com服务器
[root@slave02 ~]# scp -r /sparkLearning/hadoop-2.4.1/tmp/ slave01.example.com:/sparkLearning/hadoop-2.4.1/
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
fsimage_0000000000000000000 100% 350 0.3KB/s 00:00
VERSION 100% 200 0.2KB/s 00:00 (12)格式化ZK(在slave02.example.com上执行即可)
[root@slave02 hadoop]# hdfs zkfc -formatZK
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /sparkLearning/hadoop-2.4.1/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
......省略无关信息...............
//执行成功
15/09/18 06:14:22 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns1 in ZK.
15/09/18 06:14:22 INFO zookeeper.ZooKeeper: Session: 0x34fe096c3ca0000 closed
15/09/18 06:14:22 INFO zookeeper.ClientCnxn: EventThread shut down
(13)启动HDFS(在slave02.example.com上执行)
[root@slave02 hadoop]# start-dfs.sh
[root@slave02 hadoop]# jps
7714 QuorumPeerMain
6598 JournalNode
8295 DataNode
8202 NameNode
8716 Jps
8574 DFSZKFailoverController
[root@slave02 hadoop]# ssh slave01.example.com
Last login: Thu Aug 27 06:24:16 2015 from slave01.example.com
[root@slave01 ~]# jps
13744 DataNode
13681 NameNode
11862 QuorumPeerMain
14007 Jps
13943 DFSZKFailoverController
13851 JournalNode
[root@slave03 ~]# jps
5876 JournalNode
7652 Jps
7068 DataNode
6764 QuorumPeerMain
(14)启动YARN(在slave01.example.com上执行)
//slave01.example.com
[root@slave01 ~]# start-yarn.sh
...输出省略.....
[root@slave01 ~]# jps
14528 Jps
13744 DataNode
13681 NameNode
14228 NodeManager
11862 QuorumPeerMain
13943 DFSZKFailoverController
14138 ResourceManager
13851 JournalNode
//slave02.example.com
[root@slave02 ~]# jps
11216 Jps
10656 JournalNode
7714 QuorumPeerMain
11010 NodeManager
10427 DataNode
10844 DFSZKFailoverController
10334 NameNode
//slave03.example.com
[root@slave03 ~]# jps
8610 JournalNode
8791 NodeManager
8503 DataNode
9001 Jps
6764 QuorumPeerMain
(15)查看hadoop运行管理界面
打开浏览器,输入http://slave01.example.com:8088/,可以得到hadoop集群管理界面:
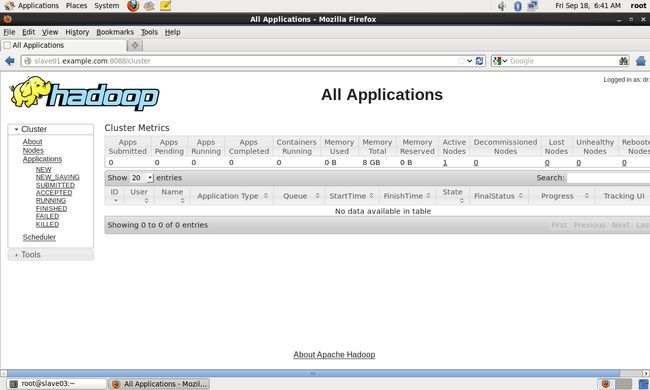
输入http://slave01.example.com:50070 可以得到HDFS管理界面
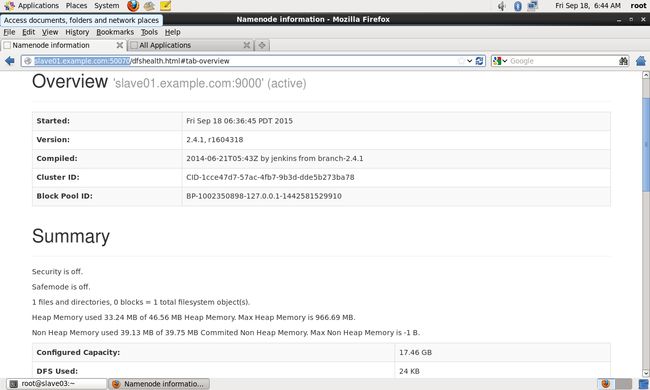
至此Hadoop集群配置成功
3. Spark 1.5.0 集群部署
(1)将Spark添加到环境变量
[root@slave01 hadoop]# cp /mnt/hgfs/share/spark-1.5.0-bin-hadoop2.4.tgz /sparkLearning/
[root@slave01 sparkLearning]# tar -zxvf spark-1.5.0-bin-hadoop2.4.tgz > /dev/null
[root@slave01 sparkLearning]# vim /etc/profile将/etc/profile内容修改如下:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40
export SCALA_HOME=/sparkLearning/scala-2.10.4
export HADOOP_HOME=/sparkLearning/hadoop-2.4.1
export SPARK_HOME=/sparkLearning/spark-1.5.0-bin-hadoop2.4
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
(2)将Spark添加到环境变量
[root@slave01 sparkLearning]# cd spark-1.5.0-bin-hadoop2.4/conf
[root@slave01 conf]# ls
docker.properties.template metrics.properties.template spark-env.sh.template
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template
//复制模板文件
[root@slave01 conf]# cp spark-env.sh.template spark-env.sh
[root@slave01 conf]# vim spark-env.sh在spark-env.sh文件中添加如下内容:
export JAVA_HOME=/sparkLearning/jdk1.8.0_40
export SCALA_HOME=/sparkLearning/scala-2.10.4
export HADOOP_CONF_DIR=/sparkLearning/hadoop-2.4.1/etc/hadoop[root@slave01 conf]# cp slaves.template slaves
[root@slave01 conf]# vim slaves
slaves文件内容如下:
# A Spark Worker will be started on each of the machines listed below.
slave01.example.com
slave02.example.com
slave03.example.com(3)将配置信息复制到其它服务器
[root@slave01 sparkLearning]# scp /etc/profile slave02.example.com:/etc/profile
profile 100% 2123 2.1KB/s 00:00
[root@slave01 sparkLearning]# scp /etc/profile slave03.example.com:/etc/profile
profile 100% 2123 2.1KB/s 00:00
[root@slave01 sparkLearning]# vim /etc/profile
[root@slave01 sparkLearning]# scp -r spark-1.5.0-bin-hadoop2.4 slave02.example.com:/sparkLearning/
...执行过程省略.....
[root@slave01 sparkLearning]# scp -r spark-1.5.0-bin-hadoop2.4 slave03.example.com:/sparkLearning/
...执行过程省略.....
(4)启动Spark集群
因为本人机器上装了Ambari Server,占用了8080端口,而Spark Master默认端是8080,因此将sbin/start-master.sh中的SPARK_MASTER_WEBUI_PORT修改为8888
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8888
fi[root@slave01 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /sparkLearning/spark-1.5.0-bin-hadoop2.4/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-slave01.example.com.out
slave03.example.com: starting org.apache.spark.deploy.worker.Worker, logging to /sparkLearning/spark-1.5.0-bin-hadoop2.4/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave03.example.com.out
slave02.example.com: starting org.apache.spark.deploy.worker.Worker, logging to /sparkLearning/spark-1.5.0-bin-hadoop2.4/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.example.com.out
slave01.example.com: starting org.apache.spark.deploy.worker.Worker, logging to /sparkLearning/spark-1.5.0-bin-hadoop2.4/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.example.com.out
[root@slave01 sbin]# jps
13744 DataNode
13681 NameNode
14228 NodeManager
16949 Master
11862 QuorumPeerMain
13943 DFSZKFailoverController
14138 ResourceManager
13851 JournalNode
17179 Jps
17087 Worker
浏览器中输入slave01.example.com:8888
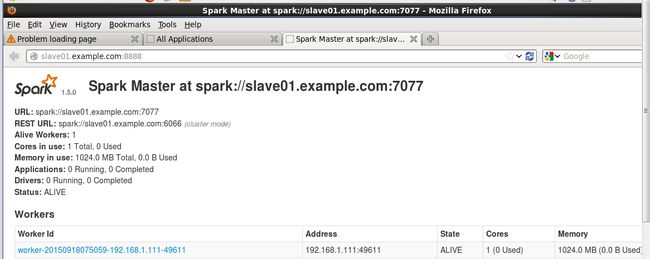
但是在启动过程中出现了错误,查看日志文件
[root@slave02 logs]# more spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.example.com.out
日志内容中包括下列错误:
akka.actor.ActorNotFound: Actor not found for: ActorSelection[Anchor(akka.tcp://
sparkMaster@slave01.example.com:7077/), Path(/user/Master)]
at akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.
scala:65)
at akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.
scala:63)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExe
cutor.scala:55)
at akka.dispatch.BatchingExecutor$Batch.run(BatchingExecutor.scala:73)
at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.unbatched
Execute(Future.scala:74)
at akka.dispatch.BatchingExecutor$class.execute(BatchingExecutor.scala:1
20)
at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.execute(F
uture.scala:73)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala
:40)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scal
a:248)
at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:266)
at akka.actor.EmptyLocalActorRef.specialHandle(ActorRef.scala:533)
at akka.actor.DeadLetterActorRef.specialHandle(ActorRef.scala:569)
.....省略.....................没找到具体原因,在ubuntu 10.04服务器上进行相同的配置,集群搭建却成功了(心中一万头…..),运行界面如下:
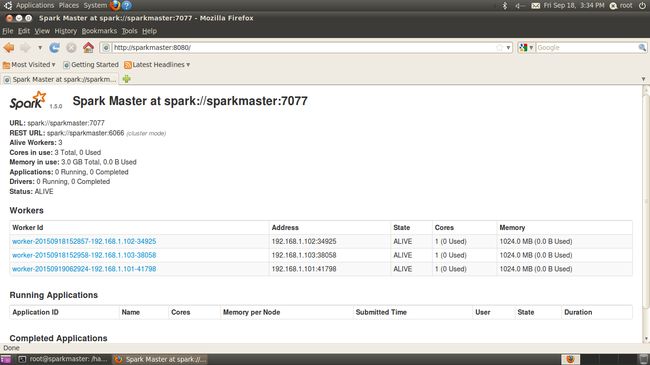
(5)测试Spark集群
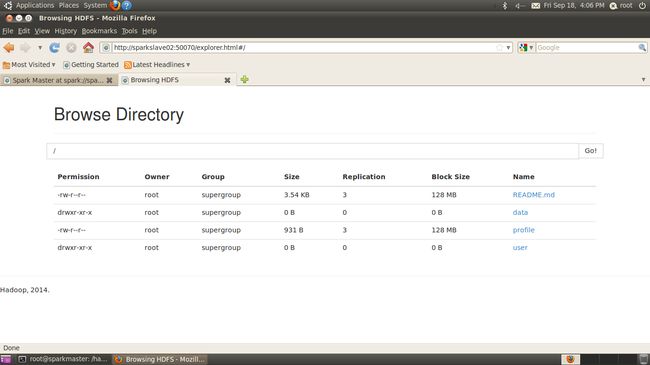
采用下列命上传spark-1.5.0-bin-hadoop2.4目录下的README.md文件到相应的根目录。
hadoop dfs -put README.md 如下图:
进入/spark-1.5.0-bin-hadoop2.4/bin目录,启动./spark-shell,如下图所示:
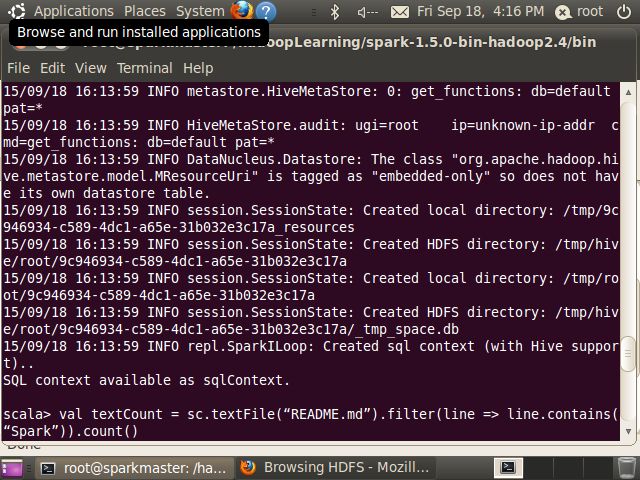
执行REDME.md文件的wordcount操作:
scala> val textCount = sc.textFile(“README.md”).filter(line => line.contains(“Spark”)).count()
如下图:
执行结果如下图:
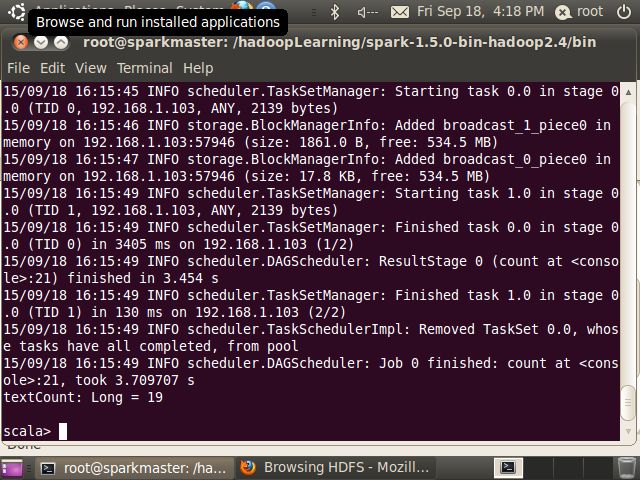
至此,Spark 1.5集群搭建成功。