OpenRisc-39-ORPSoC,or1200的memory hierarchy整体分析
引言
前面我们简单分析了ORPSoC的整体结构,or1200_top的整体结构,or1200_cpu的整体结构。
并对ORPSoC的启动过程,ORPSoC的debug子系统,clock子系统进行了介绍。
本小节,我们一起来分析一下ORPSoC的存储器组织(memory hierarchy)。
1,背景知识
在分析ORPSoC的memory hierarchy之前,我们有必要先了解一下关于cache的background。
关于cache,大概可以从三个方面进行阐述:内存到cache的映射方式,cache的写策略,cache的替换策略。
1>内存到cache的映射方式
内存到cache的映射方式,大致可以分为三种,分别是:直接映射(direct mapped),全相连(fully associative),组相连(set associative)。
为了便于理解,现在假设一个例子,比如咱们的内存只有16bytes,而cache只有4bytes(cache line是1byte),那么对于分别采用三种不同的映射方式,会是什么情况呢?如下图所示:
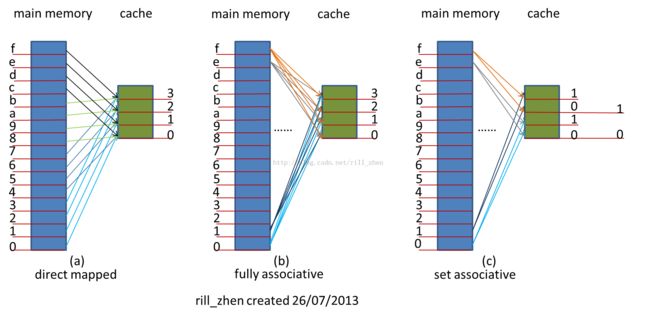
1》direct mapped
对于direct mapped,为了便于数据查找,一般规定内存数据只能置于缓存的特定区域。对于直接匹配缓存,每一个内存块地址都可通过模运算对应到一个唯一缓存块上。注意这是一个多对一匹配:多个内存块地址须共享一个缓存区域。
对于咱们这个例子来说,内存的0地址只能映射到cache的第0个(0%4=0)cache line,内存的1地址只能映射到cache的第1个(1%4=1)cache line,内存的2地址只能映射到cache的第2个(2%4=2)cache line,内存的3地址只能映射到cache的第3个(3%4=3)cache line,内存的4地址只能映射到cache的第0个(4%4=0)cache line,。。。。。。如此循环下去。
所以如果采用direct mapped的话,core在访问cache时,根据TLB处理之后的物理地址,进行取模(%)运算,就可以直接确定其cache的位置,由于一个cache line可能对应不同的内存地址(具有相同模运算结果的内存),然后将物理地址的tag部分与cache的tag部分进行一次比较,就可以确定是cache hit,还是cache miss。
direct mapped的特点是,逻辑简单,延迟短(只进行一次比较),但命中率低。
2》fully associative
对于fully associative,这种方式,内存中的数据块可以被放置到cache的任意区域。这种相联完全免去了索引的使用,而直接通过在整个缓存空间上匹配标签进行查找。
对于咱们的这个例子来说,内存的某个地址,可以映射到cache的任意个cache line。内存的0地址能映射到cache的第0个cache line,也可以映射到第1个cache line,也可以映射到第2个cache line,也可以映射到第3个cache line。
所以如果采用fully associative的话,core在访问cache时,根据TLB处理之后的物理地址,要依次和所有的cache line的tag进行比较。
fully associative的特点是:控制复杂,查找造成的电路延迟最长,因此仅在特殊场合,如缓存极小时,才会使用,命中率较高。
3》set associative
set associative是direct mapped 和fully associative两种方式的一个折中。
对于咱们这个例子来说,我们将4个cache line分成了两组,内存的0地址只能映射到cache的第0个组(0%2=0),但是在组内是任意的,既可以映射到组内的第0个cache line,也可以映射到第1个cache line。内存的1地址只能映射到cache的第1个组(1%2=1),但是在组内也是任意的,既可以映射到组内的第0个cache line,也可以映射到第1个cache line。内存的2地址只能映射到cache的第0个组(2%2=0),但是在组内也是任意的,既可以映射到组内的第0个cache line,也可以映射到第1个cache line,。。。。。。。依次类推。
所以,如果采用set associative的话,core在访问cache时,根据TLB处理之后的物理地址,先将物理地址取模,得到其可能的cache的组,然后再依次与组内的所有cache line的tag进行比较,确定是cache hit 还是cache miss。
set associative是折中方案,所以其特点就是集direct mapped 和fully associative之所长。是一个平衡方案。
咱们这个例子是2 way set associative,即两路组相连,所谓的两路,是指每个cache组内的cache line的数目,不是分组的数目。比如是4路组相连,指的是每个cache组内有4个cache line。
4》小结
对于直接映射,由于缓存字节数和缓存块数均为2的幂,上述运算可以由硬件通过移位极快地完成。直接匹配缓存尽管在电路逻辑上十分简单,但是存在显著的冲突问题。由于多个不同的内存块仅共享一个缓存块,一旦发生缓存失效就必须将缓存块的当前内容清除出去。这种做法不但因为频繁的更换缓存内容造成了大量延迟,而且未能有效利用程序运行期所具有的时间局部性。
组相联(Set Associativity)是解决这一问题的主要办法。使用组相联的缓存把存储空间组织成多个组,每个组有若干数据块。通过建立内存数据和组索引的对应关系,一个内存块可以被载入到对应组内的任一数据块上。
直接映射可以认为是单路组相联。经验规则表明,在缓存小于128KB时,欲达到相同失效率,一个双路组相联缓存仅需相当于直接匹配缓存一半的存储空间。
2>写策略
为了和下级存储(如内存)保持数据一致性,就必须把数据更新适时传播下去。这种传播通过回写来完成。
一般有两种回写策略:写回(Write back)和写通(Write through)。
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果缓存命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。
写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
写通较写回易于实现,并且能更简单地维持数据一致性。
当发生写失效时,缓存可有两种处理策略,分别称为分配写(Write allocate)和非分配写(No-write allocate)。
分配写是指,先如处理读失效一样,将所需数据读入缓存,然后再将数据写到被读入的单元。非分配写则总是直接将数据写回内存。
设计缓存时可以使用回写策略和分配策略的任意组合。对于不同组合,发生数据写操作时的行为也有所不同。
3>替换策略
对于组相联缓存,当一个组的全部缓存块都被占满后,如果再次发生缓存失效,就必须选择一个缓存块来替换掉。存在多种策略决定哪个块被替换。
显然,最理想的替换块应当是距下一次被访问最晚的那个。这种理想策略无法真正实现,但它为设计其他策略提供了方向。
先进先出算法(FIFO,first in first out)替换掉进入组内时间最长的缓存块。最久未使用算法(LRU,LeastRecentlyUsed)则跟踪各个缓存块的使用状况,并根据统计比较出哪个块已经最长时间未被访问。对于2路以上相联,这个算法的时间代价会非常高。
对最久未使用算法的一个近似是非最近使用(NMRU,next most recently used)。这个算法仅记录哪一个缓存块是最近被使用的。在替换时,会随机替换掉任何一个其他的块。故称非最近使用。相比于LRU,这种算法仅需硬件为每一个缓存块增加一个使用位(use bit)即可。
此外,也可使用纯粹的随机替换法。测试表明完全随机替换的性能近似于LRU。
4>地址翻译
上面我们所描述情况,在访问cache前,已经将虚拟地址转换成了物理地址,其实,不一定,也可是是虚拟地址直接访问cache,倒底是使用物理地址还是虚拟地址,这就是翻译方式的选择。
1》虚缓存
一个简单的方案就是缓存的标签和索引均使用虚拟地址。这种缓存称为虚缓存(virtual cache)。这种缓存的优点是仅在缓存失效时才需要进行页面翻译。由于缓存命中率很高,需要翻译的次数也相对较少。
但是这种技术也存在严重的问题。
第一,引入虚拟地址的一个重要原因是在软件(操作系统)级进行页面保护,以防止进程间相互侵犯地址空间。由于这种保护是通过页表和翻译旁视缓冲器(TLB)中的保护位(protection bit)实现的,直接使用虚拟地址来访问数据等于绕过了页面保护。一个解决办法是在缓存失效时查看TLB对应表项的保护位以确定是否可以加载缺失的数据。
第二,由于不同进程使用相同的虚拟地址空间,在切换进程后会出现整个缓存都不再对应新进程的有效数据。如果前后两个进程使用了相同的地址区间,就可能会造成缓存命中,确访问了错误的地址,导致程序错误。有两个解决办法:(1)进程切换后清空缓存。代价过高。(2)使用进程标识符(PID)作为缓存标签的一部分,以区分不同进程的地址空间。
第三,别名问题(Alias)。由于操作系统可能允许页面别名,即多个虚拟页面映射至同一物理页面,使用虚拟地址做标签将可能导致一份数据在缓存中出现多份拷贝的情形。这种情况下如果对其中一份拷贝作出修改,而其他拷贝没有同步更新,则数据丧失整合性,导致程序错误。有两个解决办法:(1)硬件级反别名。当缓存载入目标数据时,确认缓存内没有缓存块的标签是此地址的别名。如果有则不载入,而直接返回别名缓存块内的数据。(2)页面着色(Page Coloring)。这种技术是由操作系统对页面别名作出限制,使指向同一页面的别名页面具有相同的低端地址。这样,只要缓存的索引范围足够小,就能保证在缓存中决不会出现来自不同别名页面的数据。
第四,输入输出问题。由于输入输出系统通常只使用物理地址,虚缓存必须引入一种逆映射技术来实现虚拟地址到物理地址的转换。
2》实缓存
实缓存(physical cache)完全使用物理地址做缓存块的标签和索引,故地址翻译必须在访问缓存之前进行。这种传统方法所以可行的一个重要原因是TLB的访问周期非常短(因为本质上TLB也是一个缓存),因而可以被纳入流水线。
但是,由于地址翻译发生在缓存访问之前,会比虚缓存更加频繁地造成TLB。(相比之下,虚缓存仅在本身失效的前提下才会访问TLB,进而有可能引发TLB失效)实缓存在运行中存在这样一种可能:首先触发了一个TLB失效,然后从页表中更换TLB表项(假定页表中能找到)。然后再重新访问TLB,翻译地址,最后发现数据不在缓存中。
3》虚索引、实标签缓存
一个折中方案是同时使用虚索引和实标签(virtually indexed, physically tagged)。这种缓存利用了页面技术的一个特征,即虚拟地址和物理地址享有相同的页内偏移值(page offset)。这样,可以使用页内偏移作为缓存索引,同时使用物理页面号作为标签。这种混合方式的好处在于,其既能有效消除诸如别名引用等纯虚缓存的固有问题,又可以通过对TLB和缓存的并行访问来缩短流水线延迟。
这种技术的一个缺点是,在使用直接匹配缓存的前提下,缓存大小不能超过页面大小,否则页面偏移范围就不足以覆盖缓存索引范围。这个弊端可以通过提高组相联路数来改善。
5>多级cache
介于处理器和内存二者之间的缓存有两个天然冲突的性能指标:速度和容量。如果只向处理器看齐而追求速度,则必然要靠减少容量来换取访问时间;如果只向内存看齐而追求容量,则必然以增加处理器的访问时间为牺牲。这种矛盾促使人们考虑使用多级缓存。
在一个两级缓存体系中,一级缓存靠近处理器一侧,二级缓存靠近内存一侧。当一级缓存发生失效时,它向二级缓存发出请求。如果请求在二级缓存上命中,则数据交还给一级缓存;如失效,二级缓存进一步向内存发出请求。对于三级缓存可依此类推。
通常,更接近内存的缓存有着更大容量,但是速度也更慢。
值得注意的是,无论如何,低级缓存的局部命中率总是低于高级缓存。这是因为数据的时空局部性在一级缓存上基本上已经利用殆尽。
对于各级cache,虽然功能类似,但不同级别的缓存在设计和实现上也有不同之处。
一般而言,在存储体系结构中低级存储总是包含高级存储的全部数据,但对于多级缓存则未必。相反地,存在一种多级排他性(Multilevel exclusion)的设计。此种设计意指高级缓存中的内容和低级缓存的内容完全不相交。这样,如果一个高级缓存请求失效,并在次级缓存中命中的话,次级缓存会将命中数据和高级缓存中的一项进行交换,以保证排他性。
多级排他性的好处是在存储预算有限的前提下可以让低级缓存更多地存储数据。否则低级缓存的大量空间将不得不用于覆盖高级缓存中的数据,这无益于提高低级缓存的命中率。
当然,也可以如内存对缓存般,使用多级包容性(Multilevel inclusion)设计。这种设计的优点是比较容易方便查看缓存和内存间的数据一致性,因为仅检查最低一级缓存即可。对于多级排他性缓存这种检查必须在各级上分别进行。这种设计的一个主要缺点是,一旦低级缓存由于失效而被更新,就必须相应更新在高级缓存上所有对应的数据。因此,通常令各级缓存的缓存块大小一致,从而减少低级对高级的不必要更新。
此外,各级缓存的写策略也不相同。对于一个两级缓存系统,一级缓存可能会使用写通来简化实现,而二级缓存使用写回确保数据一致性。orpsoc正是这样设计的。
6>关于cache的优化
优化缓存可从三个方面入手:减少命中时间,降低失效率,减轻失效代价。此外,增加缓存访问带宽也能有效较低AMAT(平均内存访问时间,Average Memory Access Time)。
理论上,完全使用虚拟地址可以获得更快的缓存访问速度,因为这样仅在缓存失效时才会进行地址翻译。但是,如前所述,这种纯虚地址缓存由于绕开了操作系统对进程访问地址的软件控制,会存在不少问题。
为了能接近虚缓存的访问速度,又能避开虚缓存带来的种种问题,引入了所谓虚索引、实标签缓存(virtually indexed, physically tagged)。这种结构的缓存可以令地址翻译和缓存查询并发进行,大大加快了缓存的访问速度。
由于电路延迟很大程度上取决于存储芯片的大小,所以可考虑使用较小容量的缓存以保证最短的访问周期。这么做的另一个好处是,由于一级缓存足够小,可以把二级缓存的全部或部分也集成到CPU芯片上,从而减少了二级缓存的命中时间。
AMD从K6到Opteron连续三代CPU的一级缓存容量都没有任何增长(均为64KB)正是基于这个原因。
另一方面,考虑使用简单的缓存,如直接匹配缓存,也可较组相联缓存减少命中时间。
路预测:
所谓路预测(Way prediction),是指在组相联缓存中,跟踪同一组内不同缓存块的使用情况,然后在访问到来时,不经比较直接返回预测的缓存块。当然,标签比较仍然会进行,并且如果发现比较结果不同于预测结果,就会重新送出正确的缓存块。也就是说,错误预测会造成一个缓存块长度的延迟。
模拟表明路预测的准确率超过85%[6]。这种技术非常适合于投机执行(Speculative Execution)处理器,因为这种处理器有完善的机制来保证在投机失败之后取消已经派发的指令。
追踪缓存:
与一般的指令缓存存储静态连续地址不同,追踪缓存(Trace Cache)存储的是基于执行历史的动态地址序列。这实际上是把分支预测的结果用在了缓存上。由于只存储沿某一特定分支路径才会遇到的指令,这种缓存可比传统缓存更节省空间。
追踪缓存的缺点是实现复杂,因为必须设法连续存储的数据并不会按照2的幂次字长对齐。此外,对于不同执行路径要分开存储。如果这些执行路径中存在相同地址的指令,这些指令就只好被分别存到两个地方。这反而造成了低效的空间利用。
Intel的Pentium 4处理器使用了这一复杂技术。值得一提的是,Pentium 4追踪缓存存储的不是从内存抓取的原始指令,而是已经过解码的微操作,从而进一步节省掉了指令解码上要花的时间。
增加访问带宽。
缓存流水线化:
将一级缓存并入流水线是一般做法。这种做法可行性在于一级缓存的访问时间通常都极短,可能只有一到数个CPU周期。此外,由于TLB也是一种高速缓存硬件,故也可以纳入流水线。
非阻塞缓存:
一般而言,当缓存发生失效时,处理器必须停滞(stall),等待缓存将数据从次级存储中读取出来。
对于跨序执行(Out-of-order Execution)处理器,由于多条指令在不同处理单元中并发执行,某一条指令引发的缓存失效应该只造成其所在处理单元的停滞,而不影响其他处理单元和指令派发单元继续流水。因此,有必要设计这样一种缓存,使之能够在处理缓存失效的同时,继续接受来自处理器的访问请求。这称为非阻塞缓存(Non-blocking cache)。
降低失效率。
使用更大的数据块:
使用大数据块有助于利用空间局部性降低失效率,但其代价是更高的失效代价。这是因为,一旦失效,就必须把整个数据块都重新填满。
使用更大的缓存:
单纯增大缓存的容量也是降低失效率的一个办法。不过显然这也增大了命中时间。
高组相联缓存:
使用多路组相联可以减少冲突失效。但其后果是缓存电路逻辑复杂化,故增大了命中时间。
编译器优化:
存在多种编译器优化技术来间接影响缓存的使用模式。
2,ORPSoC的存储器组织
1>cache
有了上面的背景知识,再分析ORPSoC的memory hierarchy就会容易一些。
首先ORPSoC有三级cache:第一级是qmem,第二级是i/dcache,第三级是stor buffer(sb)。
其中qmem和i/dcache的写策略是write through,stor buffer的写策略是write back。对于write through不用多说,对于stor buffer,在or1200_define.v中有如下描述:
It will improve performance by "caching" CPU stores using store buffer. This is most important for function prologues because DC can only work in write though mode and all stores would have to complete external WB writes to memory.
Store buffer is between DC and data BIU.
All stores will be stored into store buffer and immediately completed by the CPU, even though actual external writes will be performed later. As a consequence store buffer masks all data bus errors related to stores (data bus errors related to loads are delivered normally).
All pending CPU loads will wait until store buffer is empty to ensure strict memory model. Right now this is necessary because we don't make destinction between cached and cache inhibited address space, so we simply empty store buffer until loads can begin.
It makes design a bit bigger, depending what is the number of entries in SB FIFO. Number of entries can be changed further down.
从中,可以看出,sb是在dc和biu之间的一个缓冲区,当core想写内存时,先将内容缓存下来,这样core就可以干其他的事了,具体对内容的写操作可以延后,这显然是write back策略。
如果core想读内存(load),要等到sb中的数据全部写完毕,也就是等到sb为空。
其实,我认为,真正的里core最近的cache是rf(register file),其次才是一般意义上的cache。这样算来,or1200有4级缓存。
另外,默认配置下,or1200具有一个一路直接映射的8KB数据cache和一个一路直接映射的8KB指令cache。
Cache line长度为16-byte。
两个cache都是物理索引(physically tagged)。
2>ORPSoC与SDRAM之间的缓存
其实,对于ml501平台,ORPSoC在于外部的SDRAM之间还有一级缓存。对于ml501上的ORPSoC的实现,由于片外SDRAM的频率和ORPSoC的工作频率不同,所以在dbus_arbiter和memory controller之间有一个cache。下面就简单介绍一下这个cache的设计。
1》整体模块接口
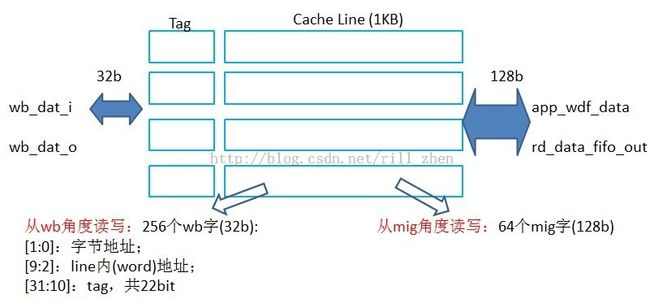
如下所示,是一个双口的block ram。

其中一个端口的信息如下:
A端口:wishbone
10位地址(高两位00)
数据宽度32位(1W/4B)
容量:1K*4B = 4KB
时钟:wb_clk_i
另外一个端口的信息如下:
B端口:mig
8位地址(高2位00)
数据宽度128位(16B)
容量:256 * 16B = 4KB
时钟:clk_tb
2》cache结构分析
首先,这个cache是4KB的双端口BRAM被组织成含有4个cache line的全相连的cache结构,替换策略为RR。
我们从cache的两侧来看,
3》cache逻辑分析
分析代码,我们可以知道:
wb_addr_i/wb_we_i:字节地址和读/写信号。
wb_addr_i[31:10]与4个cache line的tag同时进行比较(因为是全相连)。
如果发生miss,按照RR的策略选择一行。
假设选择了第0行,这一行没有被占用(not valid),则cache ctrl发出start fill信号,这个信号被转换为do_readfrom信号,再被转换为用户时钟域(200M)的do_readfrom_ddr信号,从MIG读取整个cache line(1KB)。 cache ctrl发出16个64位(内存数据宽度)地址,每个地址burst读入8个64位数,共计16*8*64b = 1KB。
假设选择了第1行,这一行已被占用(valid),则cache ctrl根据这一行是否clean,发出start writeback信号,···>do_writeback,···>do_writeback_ddr,将整个cache line回写burst到内存,此时这个cache line是not valid了,然后重复上面的步骤,start fill,do_readfrom···
4》cache的跨时钟域设计
由于cache两侧的时钟不同,这就涉及到跨时钟域的设计。这个cache是如何实现的呢?
首先我们先仿真一下,如下图:

结合仿真波形,分析代码,我们可知:
Cache控制器在wb时钟域产生do_readfrom、do_writeback等控制信号,需要转换成MIG时钟域的控制信号。
wb_clk_in_ddr2_clk:与ddr2_clk同沿,与wb_clk同宽
wb_clk_edge: wb_clk_in_ddr2_clk上升沿时,产生一个ddr2_clk周期宽度的脉冲(每隔一个wb_clk周期,在ddr2时钟边沿产生一个周期的脉冲)。
ddr2_read_done信号,来自mig时钟域,它必须跨域wb_clk_edge之后才能拉低,这样保证ddr2_read_done能跨越wb_clk的上升沿,被wb时钟域采样到。
其核心思想是,产生一个和快时钟同沿,和慢时钟同宽的一个过渡时钟。
3,小结
本小节简单介绍了关于cache的背景知识,然后简单分析了ORPSoC的cache组织,此外还对memory controller中的cache的结构,逻辑,以及跨时钟域设计进行的了分析。
需要说明的是,本小节的内容只是一个简单的整体分析,并没有涉及到具体的设计细节,所以要想弄明白ORPSoC/or1200的memory hierarchy,还要仔细阅读相应的RTL才行。
革命尚未成功,同志仍需努力!
4,参考文献
1>ORPSoC RTL code
2>OpenRisc-36-ORPSoC整体架构分析
http://blog.csdn.net/rill_zhen/article/details/9381557
3>OpenRisc-37-OpenRISC的CPU&core的整体架构分析
http://blog.csdn.net/rill_zhen/article/details/9384759
4>cache wiki
http://de.wikipedia.org/wiki/Cache