使用String.intern() 优化内存
原文链接:Save Memory by Using String Intern in Java
Attila Szegedis 在 QCon London (这里指2012年那届会议——译者注)讲解 JVM 经验总结 时,强调说,知道变量所占的内存空间大小很重要。这种说法让我很意外。因为,在企业级的Java开发中,我们并不怎么关心对象的大小,但是他以Twitter为例,给了一个很好的案例。
变量所占内存大小
问题:String类型的“Hello World” 占用多少内存?
答案:62/86字节(32/64位jdk)!
具体来说,分为8/16字节(String类型的对象头)+11*2(字符)+[8/16(char型数组对象头)+4(数组长度)填充到16/24]+4(偏移量)+4(计数)+4(哈希值)+4/8(char型数组引用).[在64位jdk机器上String对象被填充为40字节]。
问题描述
假如,你存储的微博数据里有很多地理位置信息,对应的Java类表示如下:
class Location {
String city;
String region;
String countryCode;
double long;
double lat;
}
如果一次性把所有的地理数据都加载到内存,显然会有很多String对象,而且其中会有很多String对象都是重复的。Attila 说这些数据大于32GB。所以,问题来了:如何缩减String对象对内存的消耗,使得这些对象能装进32GB的堆里?
先来看2种可能的解决方案。
方案1:Attila 解法
不同的Location对象中的数据多多少少都存在隐含的依赖关系,利用这种依赖关系,我们可以以一种相当优雅的方式解决这个问题。我们可以使用归一化,然后将1个Location对象分割成2个:
class SharedLocation {
String city;
String region;
String countryCode;
}
class Location {
SharedLocation sharedLocation;
double long;
double lat;
}
这个解法相当直接,因为,相对于城市,城市所在的州和国家的数目很少。通过这种方式,来自“Solingen, NRW, DE”的微博可以共享1个SharedLoaction,但是“Ratingen, NRW, DE”仍然要额外存储3个String对象,而不仅仅是1个“Ratingen”。这样对数据模型进行重构之后,地理数据可以降低到20GB左右。
方案2:使用String#intern
对于方案1,如果你不愿意或者不能重构数据模型时,再或者,Twitter的研究机构没有20GB大小的堆可用时,你该怎么办呢?
答案是String#intern,1个能将所有字符串只在内存中保存1份的神奇的方法。但是人们对String#intern经常出现误解。很多人提出这样的疑问:使用String#intern是否会出现使用String#equals比较次数增加的现象?因为2个相同的String,其中1个使用String#intern,二者再进行比较就只能使用String#equals,而不能使用==了。答案是肯定的,所有的对象都应该使用equal判断是否相同。
// java.lang.String
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
//...
}但是,我们使用String#intern的理由,并不是equals可以提高性能。String#intern设计的初衷,就是重用String对象,以节省内存消耗。
“仅仅对你确定将会重复出现的字符串使用String#intern,而且仅仅通过此举来节省内存”。
intern的有效程度,取决于重复/唯一字符串的比例,也取决于将原始代码修改为intern的难易程度。
String#intern的工作原理
String#intern首先得到1个堆中的String实例,然后检查该实例是否有相同的副本存在于StringTable中。StringTable本质上是1个HashSet,在永久代中存储String。StringTable的唯一目的是,保持1个存活的String的单独实例。如果StringTable中存在副本,String#intern就返回该副本实例,否则将该String添加到StringTable中。
// OpenJDK 6 code
JVM_ENTRY(jstring, JVM_InternString(JNIEnv *env, jstring str))
JVMWrapper("JVM_InternString");
JvmtiVMObjectAllocEventCollector oam;
if (str == NULL) return NULL;
oop string = JNIHandles::resolve_non_null(str);
oop result = StringTable::intern(string, CHECK_NULL);
return (jstring) JNIHandles::make_local(env, result);
JVM_END
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
unsigned int hashValue = hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
if (string != NULL) return string;
// Otherwise, add to symbol to table
return the_table()->basic_add(index, string_or_null, name, len,
hashValue, CHECK_NULL);
}因此,1个String仅仅存在1个副本。
String#intern的使用方法
正确使用String#intern的地方是,读取String数据并将String数据赋给其他对象时。注意,所有硬编码的字符串(以字符串常量的形式出现在代码中),都会自动被编译器使用intern。
例如:
String city = resultSet.getString(1); String region = resultSet.getString(2); String countryCode = resultSet.getString(3); double city = resultSet.getDouble(4); double city = resultSet.getDouble(5); Location location = new Location(city.intern(), region.intern(), countryCode.intern(), long, lat); allLocations.add(location);这样所有新创建的Location对象都将使用intern后的字符串。从数据库中读的临时的字符串将会被回收。
使用String#intern的效果
试验前最好先清理一下堆。
在MAT中打开堆,从Histogram中选择java.lang.String,右击选择“Java Basics”和"Group By Value"。
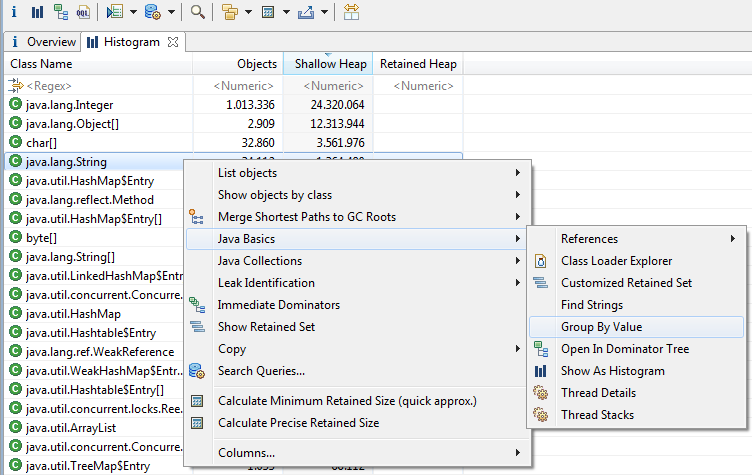
这个过程,耗时与堆大小有关。完成之后,结果如下图所示。按可用堆空间或对象数目排序,你将见证奇迹发生的时刻。
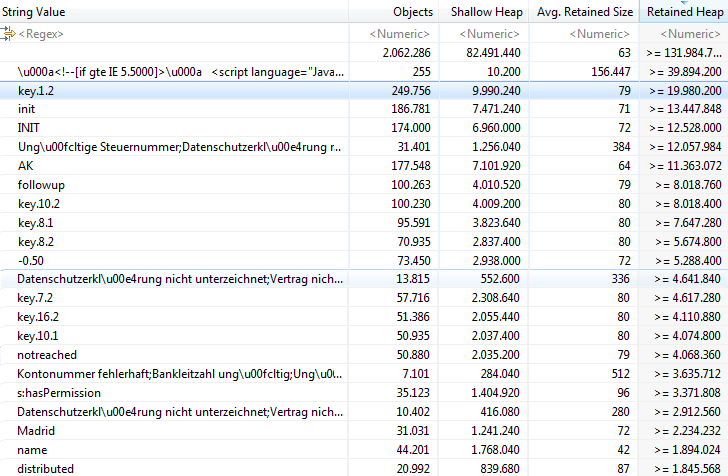
从图中可以看出,空字符串占据的很多一部分内存空间。2百万个空字符串占据了总共130MB内存。我们还可以看到一些加载的JavaScript字符串,一些用于定位的键值字符串,还有跟业务逻辑相关的字符串。
这些业务逻辑相关的字符串也许是最容易使用String#intern的了,因为我们知道它们在何处被载入内存。而对于其他字符串,我们需要使用“Merge shortest Path to GC Root”来确定它们的存储位置,即使如此,也有可能无法确定它们对应的代码位置。
String#intern是把双刃剑
为什么不总是使用String#intern呢?因为它会降低代码的执行速度!
例如:
private static final int MAX = 40000000;
public static void main(String[] args) throws Exception {
long t = System.currentTimeMillis();
String[] arr = new String[MAX];
for (int i = 0; i < MAX; i++) {
arr[i] = new String(DB_DATA[i % 10]);
// and: arr[i] = new String(DB_DATA[i % 10]).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
System.out.println(arr[0]);
}
这段代码使用String数组来存储对String对象的强引用,最后我们打印第1个元素,以防止因为底层优化而删除数组。然后我们从数据库中加载10个不同的String。这里我们使用new String(),这是我们从读临时String数据时常用的方式。最后调用GC,来保证结果的正确性。
这段代码运行于64位Windows系统,jdk 1.6.0_27,i5-2525M,8G内存。使用 -XX:+PrintGCDetails -Xmx6G -Xmn3G 来打印所有的GC动作。输出如下:
未使用intern()
1519ms [GC [PSYoungGen: 2359296K->393210K(2752512K)] 2359296K->2348002K(4707456K), 5.4071058 secs] [Times: user=8.84 sys=1.00, real=5.40 secs] [Full GC (System) [PSYoungGen: 393210K->392902K(2752512K)] [PSOldGen: 1954792K->1954823K(1954944K)] 2348002K->2347726K(4707456K) [PSPermGen: 2707K->2707K(21248K)], 5.3242785 secs] [Times: user=3.71 sys=0.20, real=5.32 secs] DE Heap PSYoungGen total 2752512K, used 440088K [0x0000000740000000, 0x0000000800000000, 0x0000000800000000) eden space 2359296K, 18% used [0x0000000740000000,0x000000075adc6360,0x00000007d0000000) from space 393216K, 0% used [0x00000007d0000000,0x00000007d0000000,0x00000007e8000000) to space 393216K, 0% used [0x00000007e8000000,0x00000007e8000000,0x0000000800000000) PSOldGen total 1954944K, used 1954823K [0x0000000680000000, 0x00000006f7520000, 0x0000000740000000) object space 1954944K, 99% used [0x0000000680000000,0x00000006f7501fd8,0x00000006f7520000) PSPermGen total 21248K, used 2724K [0x000000067ae00000, 0x000000067c2c0000, 0x0000000680000000) object space 21248K, 12% used [0x000000067ae00000,0x000000067b0a93e0,0x000000067c2c0000)使用intern()
4838ms [GC [PSYoungGen: 2359296K->156506K(2752512K)] 2359296K->156506K(2757888K), 0.1962062 secs] [Times: user=0.69 sys=0.01, real=0.20 secs] [Full GC (System) [PSYoungGen: 156506K->156357K(2752512K)] [PSOldGen: 0K->18K(5376K)] 156506K->156376K(2757888K) [PSPermGen: 2708K->2708K(21248K)], 0.2576126 secs] [Times: user=0.25 sys=0.00, real=0.26 secs] DE Heap PSYoungGen total 2752512K, used 250729K [0x0000000740000000, 0x0000000800000000, 0x0000000800000000) eden space 2359296K, 10% used [0x0000000740000000,0x000000074f4da6f8,0x00000007d0000000) from space 393216K, 0% used [0x00000007d0000000,0x00000007d0000000,0x00000007e8000000) to space 393216K, 0% used [0x00000007e8000000,0x00000007e8000000,0x0000000800000000) PSOldGen total 5376K, used 18K [0x0000000680000000, 0x0000000680540000, 0x0000000740000000) object space 5376K, 0% used [0x0000000680000000,0x0000000680004b30,0x0000000680540000) PSPermGen total 21248K, used 2725K [0x000000067ae00000, 0x000000067c2c0000, 0x0000000680000000) object space 21248K, 12% used [0x000000067ae00000,0x000000067b0a95d0,0x000000067c2c0000)可以看出,对比很明显。使用intern()时多用了3.3秒,但是节省了大量内存。代码执行完毕,使用intern()程序占用250M内存,未使用intern()的程序占用了2.4G。这个例子很好的说明了String#intern()的利弊。
*****************************************************************************
参考文章:
http://www.importnew.com/12681.html
http://my.oschina.net/liuyuanyuangogo/blog/311722
http://docs.oracle.com/javase/6/docs/api/java/lang/String.html#intern()
http://stackoverflow.com/questions/1091045/is-it-good-practice-to-use-java-lang-string-intern
http://webcache.googleusercontent.com/search?q=cache:kBhMeHtg6NEJ:tech.meituan.com/in_depth_understanding_string_intern.html+&cd=1&hl=zh-CN&ct=clnk
https://blog.codecentric.de/en/2012/03/save-memory-by-using-string-intern-in-java/
http://xmlandmore.blogspot.hk/2013/05/understanding-string-table-size-in.html
http://hellojava.info/?p=61
原文截图: