python 基础知识点整理 和具体应用
Python教程
Python是一种简单易学,功能强大的编程语言。它包括了高效的高级数据结构和简单而有效的方法,面向对象编程。Python优雅的语法,动态类型,以及它天然的解释能力,使其成为理想的语言,脚本和应用程序快速开发在大多数平台上的许多领域。
Python解释器及其扩展标准库的源码和编译版本可以从Python的Web站点,http://www.python.org/所有主要平台可自由查看,并且可以自由发布。该站点上也包含了分配和指针到很多免费的第三方Python模块,程序,工具,以及附加的文档。
Python的解释器很容易扩展新的功能,并在C或C ++(或由C来调用其他语言)实现的数据类型。 Python也很适于作为定制应用的一种扩展语言。
本教程向读者介绍了非正式的Python语言和系统的基本概念和功能。它有助于理解Python和实战练习,当然所有的例子都是自包含的,所以这本手册可以离线阅读为好。
有关标准对象和模块的详细介绍,请参见Python标准库。Python语言参考给出了语言的更正式的定义。需要编写C或C + +扩展,请阅读扩展和嵌入Python解释器和Python/C的API参考手册。也有几本书涵盖了各个深度的Python。
本教程并不试图全面,涵盖每一个功能,甚至每一个常用功能。相反,它介绍了许多Python中最引人注目的功能,会给Python语言的韵味和风格是一个好开始。看完之后,你就可以阅读和编写Python模块和程序,将准备进一步了解Python标准库描述的各种Python库模块。
Python概述
Python是一种高层次的,解释性的,交互式和面向对象的脚本语言。Python被设计成具有很强的可读性,它使用英语如其他语言常用空白作为标点符号,它比其他语言语法结构更少。
-
Python被解析:这意味着它是在运行时由解释器处理,你并不需要在执行前编译程序。这类似于Perl和PHP。
-
Python是互动:这意味着你可以在Python的提示和解释器进行交互,直接写出你的程序。
-
Python是面向对象的:这意味着Python支持面向对象的方式或程序,它封装了对象中的代码的技术。
-
Python是初学者的语言:Python是为初级程序员一种伟大的语言,并支持广泛的应用,从简单的文本处理,WWW浏览器,以游戏开发。
Python的历史:
Python是由Guido van Rossum在八十年代末和九十年代初在全国研究所数学与计算机科学在荷兰开发。
Python从许多其他语言,包括ABC,Modula-3语言,C语言,C+ +,Algol-68,Smalltalk和unix的shell等脚本语言得到参考开发。
Python是有版权的。比如Perl,Python源代码现在是GNU通用公共许可证(GPL)下提供。
Python的现在是由一个核心开发团队在维护,虽然Guido van Rossum仍然持有在指导其进展至关重要的作用。
Python的特点:
Python的功能亮点包括:
-
易于学习:Python有相对较少的关键字,结构简单,明确的语法。这让学生学习的时间相对较短。
-
易于阅读:Python代码是更加明确,可见。
-
易于维护:Python的成功在于它的源代码是相当容易维护。
-
广泛的标准库:Python的最大优点是体积库很方便,在UNIX,Windows和Macintosh跨平台兼容。
-
交互模式:支持交互模式中,可以从终端输入结果正确的语言,让交互测试的代码片段和调试。
-
便携式:Python可以在多种硬件平台上运行,并且对所有的平台上使用相同的接口。
-
扩展:可以添加低级别的模块在Python解释器。这些模块使程序员可以添加或自定义自己的工具来提高效率。
-
数据库:Python提供接口给所有主要的商业数据库。
-
GUI编程:Python支持,可以创建并移植到许多系统调用,库和Windows系统,如Windows MFC,Macintosh和Unix的X Window系统的GUI应用程序。
-
可扩展性:Python提供了一个更好的结构,并支持比shell脚本大型程序。
除了上面提到的功能,Python也有很好的功能,几个列举如下:
-
支持功能和结构化的编程方法,以及面向对象。
-
它可以作为一种脚本语言,或者可以被编译为字节码建立大型的应用程序。
-
非常高的动态数据类型,并且支持动态类型检查。
-
支持自动垃圾收集。
-
它可以用C,C + +,COM和ActiveX,CORBA和Java很容易地集成。
Python环境安装
本地环境设置
如果愿意设置您的Python环境,让我们了解如何建立Python环境。 Python可在各种平台,包括Linux和Mac OS X,可尝试打开一个终端窗口并输入“python”,以检查是否已经安装了python,什么版本,如果已经有安装。
-
Unix (Solaris, Linux, FreeBSD, AIX, HP/UX, SunOS, IRIX, etc.)
-
Win 9x/NT/2000
-
Macintosh (Intel, PPC, 68K)
-
OS/2
-
DOS (multiple versions)
-
PalmOS
-
Nokia 手机
-
Windows CE
-
Acorn/RISC OS
-
BeOS
-
Amiga
-
VMS/OpenVMS
-
QNX
-
VxWorks
-
Psion
-
Python也可被移植到Java和.NET 虚拟机
获得Python
最新源代码,二进制文件,文档,新闻等可在Python的官方网站:
Python官方网站:http://www.python.org/
可以从以下站点下载Python文档。文件格式是HTML,PDF和PostScript。
Python文档网站: www.python.org/doc/
安装Python:
Python发行版适用于各种平台。你只需要下载适用于您的平台的二进制代码并安装Python。
如果二进制代码针对您的平台无法使用,你需要一个C编译器来手动编译源代码。编译源代码提供了选择,为安装功能方面更大的灵活性。
这里是在各种平台上安装Python的快速概览:
UNIX和Linux的安装方式:
下面是简单的步骤,在Unix/ Linux机器上安装Python。
-
打开Web浏览器并转至http://www.python.org/download/
-
按照链接下载压缩的源代码在Unix/ Linux操作系统。
-
下载并解压文件。
-
编辑模块/安装文件,如果你想自定义一些选项。
-
执行./configure 脚本
-
make
-
make install
这将安装python的标准位置在 /usr/local/bin目录和它的库安装在/usr/local/lib/pythonXX,其中XX是Python使用的版本。
Windows上安装:
下面是Windows机器上安装Python的步骤。
-
打开Web浏览器并转至 http://www.python.org/download/
-
按照链接到Windows安装python-XYZ.msi文件,其中XYZ是你要安装的版本。
-
要使用此安装程序python-XYZ.msi,Windows系统必须支持Microsoft安装程序2.0。只需安装程序文件保存到本地计算机,然后运行它,看看是否你的机器支持MSI。
-
通过双击它在Windows中运行下载的文件。这将出Python的安装向导,这些都很容易使用。只需接受默认设置,等到安装完成后。
Macintosh上安装:
最新的Mac电脑配备安装了Python,但可能好几年前的机器没有安装。见http://www.python.org/download/mac/上获得的最新版本以及额外的工具来支持在Mac上开发的指令。对于老的Mac OS的Mac OS X10.3之前(2003年推出),MacPython上是可用的。“
只要到这个链接,完整Mac OS安装安装细节。
设置PATH:
程序和其他可执行文件可以住在许多目录,所以操作系统提供,列出目录的操作系统搜索可执行文件的搜索路径。
路径被存储在环境变量,这是由操作系统维护的命名字符串。这些变量包含可用于命令行解释器和其他程序的信息。
路径变量名为Path的Unix或路径在Windows(UNIX是区分大小写的,Windows是没有)。
在Mac OS中,安装程序处理的道路细节。调用任何特定目录Python解释器,必须Python的目录添加到您的路径。
设置路径,在Unix/Linux上:
将Python目录添加到在Unix系统中的特定会话的路径:
-
在csh shell: 输入
SETENV PATH "$PATH:/usr/local/bin/python" 然后按回车键。 -
在 bash shell (Linux): 输入
export PATH="$PATH:/usr/local/bin/python" 然后按回车键。 -
在 sh 或 ksh shell: 输入
PATH="$PATH:/usr/local/bin/python" 然后按回车键。
注: /usr/local/bin/python 为Python目录的路径
设置路径Windows系统:
以Python目录添加到了 Windows 特定会话的路径:
-
在命令提示符下: 输入
path %path%;C:\Python 然后按Enter键。
注意:C:\Python 是Python目录的路径
Python环境变量:
这里是重要的环境变量,其可以被Python确认:
| 变量 | 描述 |
|---|---|
| PYTHONPATH | 有类似路径的作用。这个变量告诉Python解释器在哪里可以找到导入到程序中的模块文件。 PYTHONPATH应包括Python源代码库目录,包含Python源代码的目录。 PYTHONPATH是由Python安装程序有时会预设。 |
| PYTHONSTARTUP | 包含了在每次启动的解释器(类似于Unix.profile或.login文件)时执行Python源代码的初始化文件的路径。这个文件通常命名为.pythonrc.py。在Unix中,通常包含加载实用程序或修改PYTHONPATH命令。 |
| PYTHONCASEOK | 在Windows中使用,以指示Python找到一个import语句,第一个不区分大小写的匹配。将此变量设置为任意值来激活它。 |
| PYTHONHOME | 备选模块搜索路径。它通常嵌入在PYTHONSTARTUP或PYTHONPATH目录,以使交换模块库的简单。 |
运行Python:
有三种不同的方式来启动Python:
(1) 交互式解释器:
可以输入python,并在开始通过命令行启动在交互式解释器它编码的时候。从UNIX,DOS或其他系统提供了一个命令行解释器或shell窗口。
$python # Unix/Linux or python% # Unix/Linux or C:>python # Windows/DOS
下面是所有可用的命令行选项的列表:
| 选项 | 描述 |
|---|---|
| -d | 提供调试输出 |
| -O | 生成优化代码(结果为.pyo文件) |
| -S | 不运行导入网站,在启动时查找Python路径 |
| -v | 详细输出(在导入语句详细的跟踪) |
| -X | 禁止基于类内置异常(只使用字符串);开始1.6版本过时 |
| -c cmd | 作为cmd 字符串运行Python脚本发送 |
| file | 从给定的文件运行Python脚本 |
(2) 脚本的命令行:
Python脚本可以在命令行中通过调用应用程序中的解释,如下面的执行:
$python script.py # Unix/Linux or python% script.py # Unix/Linux or C:>python script.py # Windows/DOS
注意:请确保该文件的权限模式可以执行。
(3)集成开发环境
您可以从图形用户界面(GUI)环境中运行Python。所有需要的是一个支持Python系统的GUI应用程序。
-
UNIX:IDLE也是早期的UNIX系统为Python的IDE。
-
Windows:PythonWin是第一个Windows界面的Python和一个GUI的IDE。
-
Macintosh:Python的的Macintosh版本随着闲置的IDE可从主站下载,不是MACBINARY就是BinHex'd文件。
Python基本语法
Python与Perl,C和Java语言等有许多相似之处。不过,也有语言之间有一些明确的区别。本章的目的是让你迅速学习Python的语法。
第一个Python程序:
交互模式编程:
调用解释器不经过脚本文件作为参数,显示以下提示:
$ python Python 2.6.4 (#1, Nov 11 2014, 13:34:43) [GCC 4.1.2 20120704 (Red Hat 5.6.2-48)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>>
键入下列文字在Python提示符,然后按Enter键:
>>> print "Hello, Python!";
如果您运行的是新的Python版本,那么需要使用打印语句括号像print ("Hello, Python!");。但是在Python版本2.6.4,这将产生以下结果:
Hello, Python!
脚本模式编程:
调用解释器及脚本作为参数,并开始执行的脚本,并一直持续到脚本完成。当脚本完成时,解释器不再是活动的。
让我们在脚本中编写一个简单的Python程序。所有的Python文件将具有.py扩展。所以,把下面的代码写在一个test.py文件。
print "Hello, Python!";
在这里,我假设你已经在PATH变量中设置Python解释器。现在,尝试如下运行这个程序:
$ python test.py
这将产生以下结果:
Hello, Python!
让我们尝试另一种方式来执行Python脚本。下面是修改后的test.py文件:
#!/usr/bin/python print "Hello, Python!";
在这里,假设Python解释器在/usr/bin目录中可用。现在,尝试如下运行这个程序:
$ chmod +x test.py # This is to make file executable $./test.py
这将产生以下结果:
Hello, Python!
Python标识符:
Python标识符是用来标识一个变量,函数,类,模块或其他对象的名称。一个标识符开始以字母A到Z或a〜z或后跟零个或多个字母下划线(_),下划线和数字(0〜9)。
Python中标识符内不允许标点符号,如@,$和%。 Python是一种区分大小写的编程语言。因此,Manpower 和manpower在Python中是两个不同的标识符。
这里有Python标识符命名约定:
-
类名以大写字母以及所有其它标识符以小写字母。
-
开头单个前导下划线的标识符表示由该标识符约定意思是私有的。
-
开头两个前导下划线的标识符表示一个强烈的私有的标识符。
-
如果标识符末尾还具有两个下划线结束时,该标识符是一个语言定义的特殊名称。
保留字:
下面列出了在Python中的保留字。这些保留字不可以被用作常量或变量,或任何其它标识符。所有Python关键字只包含小写字母。
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和缩进:
一个程序员学习Python时,遇到的第一个需要注意的地方是,不使用括号来表示代码的类和函数定义块或流程控制。代码块是由行缩进,这是严格执行表示方式。
在缩进位的数目是可变的,但是在块中的所有语句必须缩进相同的量。在这个例子中,两个功能块都很好使用:
if True: print "True" else: print "False"
然而,在本实施例中的第二块将产生一个错误:
if True: print "Answer" print "True" else: print "Answer" print "False"
因此,在Python中所有的连续线缩进的空格数同样的会结成块。以下是各种语句块中的例子:
注意:不要试图理解所使用的逻辑或不同的功能。只要确定你明白,即使他们各种模块无需括号。
#!/usr/bin/python import sys try: # open file stream file = open(file_name, "w") except IOError: print "There was an error writing to", file_name sys.exit() print "Enter '", file_finish, print "' When finished" while file_text != file_finish: file_text = raw_input("Enter text: ") if file_text == file_finish: # close the file file.close break file.write(file_text) file.write("\n") file.close() file_name = raw_input("Enter filename: ") if len(file_name) == 0: print "Next time please enter something" sys.exit() try: file = open(file_name, "r") except IOError: print "There was an error reading file" sys.exit() file_text = file.read() file.close() print file_text
多行语句:
Python语句通常用一个新行结束。 但是,Python允许使用续行字符(\)来表示,该行应该继续下去(跨行)。例如:
total = item_one + \ item_two + \ item_three
包含在[],{}或()括号内的陈述并不需要使用续行符。例如:
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
Python引号:
Python接受单引号('),双引号(“)和三(''或”“”)引用,以表示字符串常量,只要是同一类型的引号开始和结束的字符串。
三重引号可以用于跨越多个行的字符串。例如,所有下列是合法的:
word = 'word' sentence = "This is a sentence." paragraph = """This is a paragraph. It is made up of multiple lines and sentences."""
Python注释:
一个井号(#),这不是一个字符串文字开头的注释。“#”号之后字符和到物理行是注释的一部分,Python解释器会忽略它们。
#!/usr/bin/python # First comment print "Hello, Python!"; # second comment
这将产生以下结果:
Hello, Python!
注释可能会在声明中表达或同一行之后:
name = "Madisetti" # This is again comment
你可以使用多行注释如下:
# This is a comment. # This is a comment, too. # This is a comment, too. # I said that already.
使用空行:
一行只含有空格,可能带有注释,如果是空行那么Python完全忽略它。
在交互式解释器会话中,必须输入一个空的物理行终止多行语句。
等待用户:
程序的下面一行显示的提示,按回车键退出,等待用户按下回车键:
#!/usr/bin/python raw_input("\n\nPress the enter key to exit.")
在这里,“\n\n已”被用来显示实际行之前创建两个换行。一旦用户按下键时,程序结束。这是一个很好的技巧,保持一个控制台窗口打开,直到用户完成应用程序运行。
在一行中多个语句:
分号( ; ) 允许在单行写入多条语句,不管语句是否启动一个新的代码块。下面是使用分号示例:
import sys; x = 'foo'; sys.stdout.write(x + '\n')
多个语句组作为套件:
一组单独的语句,在Python单一的代码块被称为序列。复杂的语句,如if, while, def, and class,那些需要一个标题行和套件。
标题行开始的声明(与关键字),并终止与冒号(:)),接着是一个或多个线构成该套件。例如:
if expression : suite elif expression : suite else : suite
命令行参数:
我们可能已经看到了,比如,很多程序可以运行,它们提供有关如何运行的一些基本信息。 Python中可以使用 -h 做到这一点:
$ python -h usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ... Options and arguments (and corresponding environment variables): -c cmd : program passed in as string (terminates option list) -d : debug output from parser (also PYTHONDEBUG=x) -E : ignore environment variables (such as PYTHONPATH) -h : print this help message and exit [ etc. ]
您也可以设定您的脚本,它应该以这样的方式接受各种选项。 命令行参数是一个高级主题并在以后学习,当您通过其它的Python概念后。
Python变量类型
变量是只不过保留的内存位置用来存储值。这意味着,当创建一个变量,那么它在内存中保留一些空间。
根据一个变量的数据类型,解释器分配内存,并决定如何可以被存储在所保留的内存中。因此,通过分配不同的数据类型的变量,你可以存储整数,小数或字符在这些变量中。
变量赋值:
Python的变量不必显式地声明保留的存储器空间。当分配一个值给一个变量的声明将自动发生。等号(=)来赋值给变量。
操作数=操作符的左边是变量,操作数=操作符的右侧的名称在变量中存储的值。例如:
#!/usr/bin/python counter = 100 # An integer assignment miles = 1000.0 # A floating point name = "John" # A string print counter print miles print name
在这里,分配值100,1000.0和“John”分别给变量counter,miles和respectively。当运行这个程序,这将产生以下结果:
100 1000.0 John
多重赋值:
Python允许您同时指定一个值给几个变量。例如:
a = b = c = 1
这里,整数对象创建的值1,并且所有三个变量被分配到相同的内存位置。您也可以将多个对象分别到多个变量。例如:
a, b, c = 1, 2, "john"
这里,两个整对象用值1和2分配给变量a和b,并且值为“john”的字符串对象被分配到变量c。
标准的数据类型:
存储在内存中的数据可以是多种类型的。例如,一个人的年龄被存储为一个数字值和他的地址被存储为字母数字字符。Python用于对每个人的操作的各种标准类型定义在存储方法。
Python有五个标准的数据类型:
-
数字
-
字符串
-
列表
-
元组
-
字典
Python数字:
数字数据类型存储数值。它们是不可变的数据类型,这意味着改变一个新分配的对象的数字数据类型的结果值。
当分配一个值给他们创建的对象。例如:
var1 = 1 var2 = 10
也可以使用del语句删去有关一些对象。 del语句的语法是:
del var1[,var2[,var3[....,varN]]]]
也可以使用del语句删除单个或多个对象。例如:
del var del var_a, var_b
Python支持四种不同的数值类型:
-
int (有符号整数)
-
long (长整数[也可以以八进制和十六进制表示])
-
float (浮点实数值)
-
complex (复数)
例如:
这里是数字的一些例子:
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3+e18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7j |
-
Python允许使用一个小写L表示长整型,但建议您只使用一个大写的L到避免和数字1 长得一样不容易分辨,Python显示长整数用一个大写L。
-
复数包含一个有序对表示为a + bj,其中,a是实部,b是复数的虚部实浮点数。
Python字符串:
在Python中的字符串被确定为一组连续的字符在引号之间。 Python允许在任何对单引号或双引号。串的子集,可以使用切片操作符可采用([]和[:]),索引从0开始的字符串的开始和结束(-1)。
加号(+)符号的字符串连接操作符,而星号(*)表示重复操作。例如:
#!/usr/bin/python str = 'Hello World!' print str # Prints complete string print str[0] # Prints first character of the string print str[2:5] # Prints characters starting from 3rd to 5th print str[2:] # Prints string starting from 3rd character print str * 2 # Prints string two times print str + "TEST" # Prints concatenated string
这将产生以下结果:
Hello World! H llo llo World! Hello World!Hello World! Hello World!TEST
Python列表:
列表是最通用的Python复合数据类型。列表中包含以逗号分隔,并在方括号([])包含的项目。在一定程度上,列表相似C语言中的数组,它们之间的一个区别是,所有属于一个列表中的项目可以是不同的数据类型的。
存储在一个列表中的值可以使用切片操作符来访问([]和[:])用索引从0开始,在列表的开始位置和结束为-1。加号(+)符号列表连接运算符,星号(*)重复操作。例如:
#!/usr/bin/python list = [ 'abcd', 786 , 2.23, 'john', 70.2 ] tinylist = [123, 'john'] print list # Prints complete list print list[0] # Prints first element of the list print list[1:3] # Prints elements starting from 2nd till 3rd print list[2:] # Prints elements starting from 3rd element print tinylist * 2 # Prints list two times print list + tinylist # Prints concatenated lists
这将产生以下结果:
['abcd', 786, 2.23, 'john', 70.200000000000003] abcd [786, 2.23] [2.23, 'john', 70.200000000000003] [123, 'john', 123, 'john'] ['abcd', 786, 2.23, 'john', 70.200000000000003, 123, 'john']
Python元组:
元组是类似于列表中的序列数据类型。一个元组由数个逗号分隔的值。不同于列表,不过,元组圆括号括起来。
列表和元组之间的主要区别是:列表括在括号([])和它们的元素和大小是可以改变的,而元组在圆括号(),不能被更新。元组可以被认为是只读列表。例如:
#!/usr/bin/python tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 ) tinytuple = (123, 'john') print tuple # Prints complete list print tuple[0] # Prints first element of the list print tuple[1:3] # Prints elements starting from 2nd till 3rd print tuple[2:] # Prints elements starting from 3rd element print tinytuple * 2 # Prints list two times print tuple + tinytuple # Prints concatenated lists
这将产生以下结果:
('abcd', 786, 2.23, 'john', 70.200000000000003)
abcd
(786, 2.23)
(2.23, 'john', 70.200000000000003)
(123, 'john', 123, 'john')
('abcd', 786, 2.23, 'john', 70.200000000000003, 123, 'john')
以下是元组无效的,因为我们尝试更新一个元组,这是不允许的。类似的操作在列表中是可以的:
#!/usr/bin/python tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 ) list = [ 'abcd', 786 , 2.23, 'john', 70.2 ] tuple[2] = 1000 # Invalid syntax with tuple list[2] = 1000 # Valid syntax with list
Python字典:
Python字典是一种哈希表型。他们像关联数组或哈希在Perl中一样,由键 - 值对组成。字典键几乎可以是任何Python类型,但通常是数字或字符串。值可以是任意Python的对象。
字典是由花括号括号({}),可分配值,并用方括号([])访问。例如:
#!/usr/bin/python dict = {} dict['one'] = "This is one" dict[2] = "This is two" tinydict = {'name': 'john','code':6734, 'dept': 'sales'} print dict['one'] # Prints value for 'one' key print dict[2] # Prints value for 2 key print tinydict # Prints complete dictionary print tinydict.keys() # Prints all the keys print tinydict.values() # Prints all the values
这将产生以下结果:
This is one
This is two
{'dept': 'sales', 'code': 6734, 'name': 'john'}
['dept', 'code', 'name']
['sales', 6734, 'john']
字典有元素顺序的概念。它的元素是无序的。
数据类型转换:
有时候,可能需要执行的内置类型之间的转换。类型之间的转换,只需使用类名作为函数。
有几个内置的功能,从一种数据类型进行转换为另一种。这些函数返回一个表示转换值的新对象。
| 函数 | 描述 |
|---|---|
| int(x [,base]) |
将x转换为一个整数。基数指定为base,如果x是一个字符串。 |
| long(x [,base] ) |
将x转换为一个长整数。基数指定为base,如果x是一个字符串。 |
| float(x) |
将x转换到一个浮点数。 |
| complex(real [,imag]) |
创建一个复数。 |
| str(x) |
转换对象x为字符串表示形式。 |
| repr(x) |
对象x转换为一个表达式字符串。 |
| eval(str) |
计算一个字符串,并返回一个对象。 |
| tuple(s) |
把s转换为一个元组。 |
| list(s) |
把s转换为一个列表。 |
| set(s) |
把s转换为一个集合。 |
| dict(d) |
创建一个字典。 d必须的(键,值)元组序列。 |
| frozenset(s) |
把s转换为冻结集。 |
| chr(x) |
整数转换为一个字符。 |
| unichr(x) |
整数转换为一个Unicode字符。 |
| ord(x) |
转换单个字符为整数值。 |
| hex(x) |
将整数转换为十六进制字符串。 |
| oct(x) |
将整数转换为以八进制的字符串。 |
Python 3开发网络爬虫(一)
选择Python版本
有2和3两个版本, 3比较新, 听说改动大. 根据我在知乎上搜集的观点来看, 我还是倾向于使用”在趋势中将会越来越火”的版本, 而非”目前已经很稳定而且很成熟”的版本. 这是个人喜好, 而且预测不一定准确. 但是如果Python3无法像Python2那么火, 那么整个Python语言就不可避免的随着时间的推移越来越落后, 因此我想其实选哪个的最坏风险都一样, 但是最好回报却是Python3的大. 其实两者区别也可以说大也可以说不大, 最终都不是什么大问题. 我选择的是Python 3.
选择参考资料
由于我是一边学一边写, 而不是我完全学会了之后才开始很有条理的写, 所以参考资料就很重要(本来应该是个人开发经验很重要, 但我是零基础).
- Python官方文档
- 知乎相关资料(1) 这篇非常好, 通俗易懂的总览整个Python学习框架.
- 知乎相关资料(2)
写到这里的时候, 上面第二第三个链接的票数第一的回答已经看完了, 他们提到的有些部分(比如爬行的路线不能有回路)我就不写了。
一个简单的伪代码
以下这个简单的伪代码用到了set和queue这两种经典的数据结构, 集与队列. 集的作用是记录那些已经访问过的页面, 队列的作用是进行广度优先搜索.
queue Q
set S
StartPoint = "http://jecvay.com"
Q.push(StartPoint) # 经典的BFS开头
S.insert(StartPoint) # 访问一个页面之前先标记他为已访问
while (Q.empty() == false) # BFS循环体
T = Q.top() # 并且pop
for point in PageUrl(T) # PageUrl(T)是指页面T中所有url的集合, point是这个集合中的一个元素.
if (point not in S)
Q.push(point)
S.insert(point)
这个伪代码不能执行, 我觉得我写的有的不伦不类, 不类Python也不类C++.. 但是我相信看懂是没问题的, 这就是个最简单的BFS结构. 我是看了知乎里面的那个伪代码之后, 自己用我的风格写了一遍. 你也需要用你的风格写一遍.
这里用到的Set其内部原理是采用了Hash表, 传统的Hash对爬虫来说占用空间太大, 因此有一种叫做Bloom Filter的数据结构更适合用在这里替代Hash版本的set. 我打算以后再看这个数据结构怎么使用, 现在先跳过, 因为对于零基础的我来说, 这不是重点.
代码实现(一): 用Python抓取指定页面
我使用的编辑器是Idle, 安装好Python3后这个编辑器也安装好了, 小巧轻便, 按一个F5就能运行并显示结果. 代码如下:
#encoding:UTF-8
import urllib.request
url = "http://www.baidu.com"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)

urllib.request是一个库, 隶属urllib. 点此打开官方相关文档. 官方文档应该怎么使用呢? 首先点刚刚提到的这个链接进去的页面有urllib的几个子库, 我们暂时用到了request, 所以我们先看urllib.request部分. 首先看到的是一句话介绍这个库是干什么用的:
The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
然后把我们代码中用到的urlopen()函数部分阅读完.
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False)
重点部分是返回值, 这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各种方法, 比如我们用到的read()方法, 这些方法都可以根据官方文档的链接链过去. 根据官方文档所写, 我用控制台运行完毕上面这个程序后, 又继续运行如下代码, 以更熟悉这些乱七八糟的方法是干什么的.
>>> a = urllib.request.urlopen(full_url)
>>> type(a)
<class ‘http.client.HTTPResponse’>>>> a.geturl()
‘http://www.baidu.com/s?word=Jecvay’>>> a.info()
<http.client.HTTPMessage object at 0x03272250>>>> a.getcode()
200
代码实现(二): 用Python简单处理URL
如果要抓取百度上面搜索关键词为Jecvay Notes的网页, 则代码如下
import urllib
import urllib.request
data={}
data['word']='Jecvay Notes'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
data=urllib.request.urlopen(full_url).read()
data=data.decode('UTF-8')
print(data)
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=Jecvay+Notes’的字符串, 最后和url合并为full_url, 其余和上面那个最简单的例子相同. 关于urlencode(), 同样通过官方文档学习一下他是干什么的. 通过查看
- urllib.parse.urlencode(query, doseq=False, safe=”, encoding=None, errors=None)
- urllib.parse.quote_plus(string, safe=”, encoding=None, errors=None)
Python 3开发网络爬虫(二)
上一回, 我学会了
- 用伪代码写出爬虫的主要框架;
- 用Python的urllib.request库抓取指定url的页面;
- 用Python的urllib.parse库对普通字符串转符合url的字符串.
这一回, 开始用Python将伪代码中的所有部分实现. 由于文章的标题就是”零基础”, 因此会先把用到的两种数据结构队列和集合介绍一下. 而对于”正则表达式“部分, 限于篇幅不能介绍, 但给出我比较喜欢的几个参考资料.
Python的队列
在爬虫程序中, 用到了广度优先搜索(BFS)算法. 这个算法用到的数据结构就是队列.
Python的List功能已经足够完成队列的功能, 可以用 append() 来向队尾添加元素, 可以用类似数组的方式来获取队首元素, 可以用 pop(0) 来弹出队首元素. 但是List用来完成队列功能其实是低效率的, 因为List在队首使用 pop(0) 和 insert() 都是效率比较低的, Python官方建议使用collection.deque来高效的完成队列任务.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry") # Terry 入队
queue.append("Graham") # Graham 入队
queue.popleft() # 队首元素出队
#输出: 'Eric'
queue.popleft() # 队首元素出队
#输出: 'John'
queue # 队列中剩下的元素
#输出: deque(['Michael', 'Terry', 'Graham'])
(以上例子引用自官方文档)
Python的集合
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中, 然后再去爬这个页面.
Python提供了set这种数据结构. set是一种无序的, 不包含重复元素的结构. 一般用来测试是否已经包含了某元素, 或者用来对众多元素们去重. 与数学中的集合论同样, 他支持的运算有交, 并, 差, 对称差.
创建一个set可以用 set() 函数或者花括号 {} . 但是创建一个空集是不能使用一个花括号的, 只能用 set() 函数. 因为一个空的花括号创建的是一个字典数据结构. 以下同样是Python官网提供的示例.
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'
其实我们只是用到其中的快速判断元素是否在集合内的功能, 以及集合的并运算.
Python的正则表达式
在爬虫程序中, 爬回来的数据是一个字符串, 字符串的内容是页面的html代码. 我们要从字符串中, 提取出页面提到过的所有url. 这就要求爬虫程序要有简单的字符串处理能力, 而正则表达式可以很轻松的完成这一任务.
参考资料
- 正则表达式30分钟入门教程
- w3cschool 的Python正则表达式部分
- Python正则表达式指南
虽然正则表达式功能异常强大, 很多实际上用的规则也非常巧妙, 真正熟练正则表达式需要比较长的实践锻炼. 不过我们只需要掌握如何使用正则表达式在一个字符串中, 把所有的url都找出来, 就可以了. 如果实在想要跳过这一部分, 可以在网上找到很多现成的匹配url的表达式, 拿来用即可.
Python网络爬虫Ver 1.0 alpha
有了以上铺垫, 终于可以开始写真正的爬虫了. 我选择的入口地址是Fenng叔的Startup News, 我想Fenng叔刚刚拿到7000万美金融资, 不会介意大家的爬虫去光临他家的小站吧. 这个爬虫虽然可以勉强运行起来, 但是由于缺乏异常处理, 只能爬些静态页面, 也不会分辨什么是静态什么是动态, 碰到什么情况应该跳过, 所以工作一会儿就要败下阵来.
import re
import urllib.request
import urllib
from collections import deque
queue = deque()
visited = set()
url = 'http://news.dbanotes.net' # 入口页面, 可以换成别的
queue.append(url)
cnt = 0
while queue:
url = queue.popleft() # 队首元素出队
visited |= {url} # 标记为已访问
print('已经抓取: ' + str(cnt) + ' 正在抓取 <--- ' + url)
cnt += 1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue
# 避免程序异常中止, 用try..catch处理异常
try:
data = urlop.read().decode('utf-8')
except:
continue
# 正则表达式提取页面中所有队列, 并判断是否已经访问过, 然后加入待爬队列
linkre = re.compile('href=\"(.+?)\"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print('加入队列 ---> ' + x)
这个版本的爬虫使用的正则表达式是
'href=\"(.+?)\"'
所以会把那些.ico或者.jpg的链接都爬下来. 这样read()了之后碰上decode(‘utf-8′)就要抛出异常. 因此我们用getheader()函数来获取抓取到的文件类型, 是html再继续分析其中的链接.
if 'html' not in urlop.getheader('Content-Type'):
continue
但是即使是这样, 依然有些网站运行decode()会异常. 因此我们把decode()函数用try..catch语句包围住, 这样他就不会导致程序中止. 程序运行效果图如下:

爬虫是可以工作了, 但是在碰到连不上的链接的时候, 它并不会超时跳过. 而且爬到的内容并没有进行处理, 没有获取对我们有价值的信息, 也没有保存到本地. 下次我们可以完善这个alpha版本.
Python3网络爬虫(三): 伪装浏览器
上一次我自学爬虫的时候, 写了一个简陋的勉强能运行的爬虫alpha. alpha版有很多问题. 比如一个网站上不了, 爬虫却一直在等待连接返回response, 不知道超时跳过; 或者有的网站专门拦截爬虫程序, 我们的爬虫也不会伪装自己成为浏览器正规部队; 并且抓取的内容没有保存到本地, 没有什么作用. 这次我们一个个解决这些小问题.
此外, 在我写这系列文章的第二篇的时候, 我还是一个对http的get和post以及response这些名词一无所知的人, 但是我觉得这样是写不好爬虫的. 于是我参考了 <<计算机网络–自顶向下方法>> 这本书的第二章的大部分内容. 如果你也一样对http的机制一无所知, 我也推荐你找一找这方面的资料来看. 在看的过程中, 安装一个叫做Fiddler的软件, 边学边实践, 观察浏览器是如何访问一个网站的, 如何发出请求, 如何处理响应, 如何进行跳转, 甚至如何通过登录认证. 有句老话说得好, 越会用Fiddler, 就对理论理解更深刻; 越对理论理解深刻, Fiddler就用得越顺手. 最后我们在用爬虫去做各种各样的事情的时候, Fiddler总是最得力的助手之一.
添加超时跳过功能
首先, 我简单地将
urlop = urllib.request.urlopen(url)
改为
urlop = urllib.request.urlopen(url, timeout = 2)
运行后发现, 当发生超时, 程序因为exception中断. 于是我把这一句也放在try .. except 结构里, 问题解决.
支持自动跳转
在爬 http://baidu.com 的时候, 爬回来一个没有什么内容的东西, 这个东西告诉我们应该跳转到 http://www.baidu.com . 但是我们的爬虫并不支持自动跳转, 现在我们来加上这个功能, 让爬虫在爬 baidu.com 的时候能够抓取 www.baidu.com 的内容.
首先我们要知道爬 http://baidu.com 的时候他返回的页面是怎么样的, 这个我们既可以用 Fiddler 看, 也可以写一个小爬虫来抓取. 这里我抓到的内容如下, 你也应该尝试一下写几行 python 来抓一抓.
<html>
<meta http-equiv=”refresh” content=”0;url=http://www.baidu.com/”>
</html>
看代码我们知道这是一个利用 html 的 meta 来刷新与重定向的代码, 其中的0是等待0秒后跳转, 也就是立即跳转. 这样我们再像上一次说的那样用一个正则表达式把这个url提取出来就可以爬到正确的地方去了. 其实我们上一次写的爬虫已经可以具有这个功能, 这里只是单独拿出来说明一下 http 的 meta 跳转.
伪装浏览器正规军
前面几个小内容都写的比较少. 现在详细研究一下如何让网站们把我们的Python爬虫当成正规的浏览器来访. 因为如果不这么伪装自己, 有的网站就爬不回来了. 如果看过理论方面的知识, 就知道我们是要在 GET 的时候将 User-Agent 添加到header里.
如果没有看过理论知识, 按照以下关键字搜索学习吧 :D
- HTTP 报文分两种: 请求报文和响应报文
- 请求报文的请求行与首部行
- GET, POST, HEAD, PUT, DELETE 方法
我用 IE 浏览器访问百度首页的时候, 浏览器发出去的请求报文如下:
GET http://www.baidu.com/ HTTP/1.1
Accept: text/html, application/xhtml+xml, */*
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encoding: gzip, deflate
Host: www.baidu.com
DNT: 1
Connection: Keep-Alive
Cookie: BAIDUID=57F4D171573A6B88A68789EF5DDFE87:FG=1; uc_login_unique=ccba6e8d978872d57c7654130e714abd; BD_UPN=11263145; BD
然后百度收到这个消息后, 返回给我的的响应报文如下(有删节):
HTTP/1.1 200 OK
Date: Mon, 29 Sep 2014 13:07:01 GMT
Content-Type: text/html; charset=utf-8
Connection: Keep-Alive
Vary: Accept-Encoding
Cache-Control: private
Cxy_all: baidu+8b13ba5a7289a37fb380e0324ad688e7
Expires: Mon, 29 Sep 2014 13:06:21 GMT
X-Powered-By: HPHP
Server: BWS/1.1
BDPAGETYPE: 1
BDQID: 0x8d15bb610001fe79
BDUSERID: 0
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=0; path=/
Content-Length: 80137<!DOCTYPE html><!–STATUS OK–><html><head><meta http-equiv=”content-type” content=”text/html;charset=utf-8″><meta http-equiv=”X-UA-Compatible” content=”IE=Edge”><link rel=”dns-prefetch” href=”//s1.bdstatic.com”/><link rel=”dns-prefetch” href=”//t1.baidu.com”/><link rel=”dns-prefetch” href=”//t2.baidu.com”/><link rel=”dns-prefetch” href=”//t3.baidu.com”/><link rel=”dns-prefetch” href=”//t10.baidu.com”/><link rel=”dns-prefetch” href=”//t11.baidu.com”/><link rel=”dns-prefetch” href=”//t12.baidu.com”/><link rel=”dns-prefetch” href=”//b1.bdstatic.com”/><title>百度一下,你就知道</title><style index=”index” > ……….这里省略两万字……………. </script></body></html>
如果能够看懂这段话的第一句就OK了, 别的可以以后再配合 Fiddler 慢慢研究. 所以我们要做的就是在 Python 爬虫向百度发起请求的时候, 顺便在请求里面写上 User-Agent, 表明自己是浏览器君.
在 GET 的时候添加 header 有很多方法, 下面介绍两种方法.
第一种方法比较简便直接, 但是不好扩展功能, 代码如下:
import urllib.request
url = 'http://www.baidu.com/'
req = urllib.request.Request(url, headers = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
})
oper = urllib.request.urlopen(req)
data = oper.read()
print(data.decode())
第二种方法使用了 build_opener 这个方法, 用来自定义 opener, 这种方法的好处是可以方便的拓展功能, 例如下面的代码就拓展了自动处理 Cookies 的功能.
import urllib.request
import http.cookiejar
# head: dict of header
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
oper = makeMyOpener()
uop = oper.open('http://www.baidu.com/', timeout = 1000)
data = uop.read()
print(data.decode())
上述代码运行后通过 Fiddler 抓到的 GET 报文如下所示:
GET http://www.baidu.com/ HTTP/1.1
Accept-Encoding: identity
Connection: close
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept: text/html, application/xhtml+xml, */*
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
可见我们在代码里写的东西都添加到请求报文里面了.
保存抓回来的报文
顺便说说文件操作. Python 的文件操作还是相当方便的. 我们可以讲抓回来的数据 data 以二进制形式保存, 也可以经过 decode() 处理成为字符串后以文本形式保存. 改动一下打开文件的方式就能用不同的姿势保存文件了. 下面是参考代码:
def saveFile(data):
save_path = 'D:\\temp.out'
f_obj = open(save_path, 'wb') # wb 表示打开方式
f_obj.write(data)
f_obj.close()
# 这里省略爬虫代码
# ...
# 爬到的数据放到 dat 变量里
# 将 dat 变量保存到 D 盘下
saveFile(dat)
下回我们会用 Python 来爬那些需要登录之后才能看到的信息. 在那之前, 我已经对 Fiddler 稍微熟悉了. 希望一起学习的也提前安装个 Fiddler 玩一下.
Python3网络爬虫(四): 登录
今天的工作很有意思, 我们用 Python 来登录网站, 用Cookies记录登录信息, 然后就可以抓取登录之后才能看到的信息. 今天我们拿知乎网来做示范. 为什么是知乎? 这个很难解释, 但是肯定的是知乎这么大这么成功的网站完全不用我来帮他打广告. 知乎网的登录比较简单, 传输的时候没有对用户名和密码加密, 却又不失代表性, 有一个必须从主页跳转登录的过程.
不得不说一下, Fiddler 这个软件是 Tpircsboy 告诉我的. 感谢他给我带来这么好玩的东西.
第一步: 使用 Fiddler 观察浏览器行为
在开着 Fiddler 的条件下运行浏览器, 输入知乎网的网址 http://www.zhihu.com 回车后到 Fiddler 中就能看到捕捉到的连接信息. 在左边选中一条 200 连接, 在右边打开 Inspactors 透视图, 上方是该条连接的请求报文信息, 下方是响应报文信息.
其中 Raw 标签是显示报文的原文. 下方的响应报文很有可能是没有经过解压或者解码的, 这种情况他会在中间部位有一个小提示, 点击一下就能解码显示出原文了.

以上这个截图是在未登录的时候进入 http://www.zhihu.com 得到的. 现在我们来输入用户名和密码登陆知乎网, 再看看浏览器和知乎服务器之间发生了什么.

点击登陆后, 回到 Fiddler 里查看新出现的一个 200 链接. 我们浏览器携带者我的帐号密码给知乎服务器发送了一个 POST, 内容如下:
POST http://www.zhihu.com/login HTTP/1.1
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
Referer: http://www.zhihu.com/#signin
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 6.4; WOW64; Trident/7.0; rv:11.0) like Gecko
Content-Length: 97
DNT: 1
Host: www.zhihu.com
Connection: Keep-Alive
Pragma: no-cache
Cookie: __utma=51854390.1539896551.1412320246.1412320246.1412320246.1; __utmb=51854390.6.10.1412320246; __utmc=51854390; __utmz=51854390.1412320246.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmv=51854390.000–|3=entry_date=20141003=1_xsrf=4b41f6c7a9668187ccd8a610065b9718&email=此处涂黑%40gmail.com&password=此处不可见&rememberme=y
截图如下:
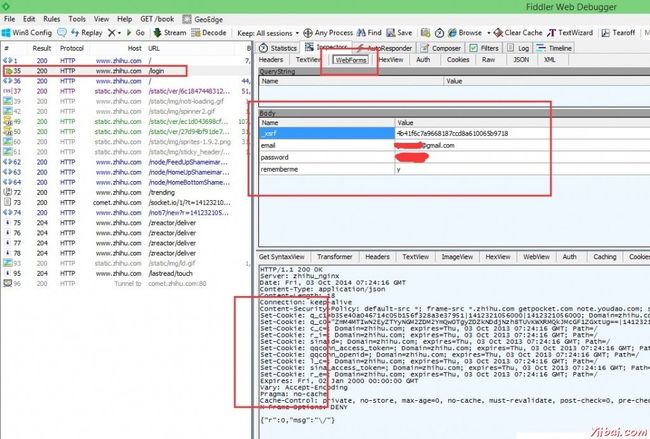
我的浏览器给 http://www.zhihu.com/login 这个网址(多了一个/login) 发送了一个POST, 内容都已经在上面列出来了, 有用户名, 有密码, 有一个”记住我”的 yes, 其中这个 WebForms 标签下 Fiddler 能够比较井井有条的列出来 POST 的内容. 所以我们用 Python 也发送相同的内容就能登录了. 但是这里出现了一个 Name 为 _xsrf 的项, 他的值是 4b41f6c7a9668187ccd8a610065b9718. 我们要先获取这个值, 然后才能给他发.
浏览器是如何获取的呢, 我们刚刚是先访问了 http://www.zhihu.com/ 这个网址, 就是首页, 然后登录的时候他却给 http://www.zhihu.com/login 这个网址发信息. 所以用侦探一般的思维去思考这个问题, 就会发现肯定是首页把 _xsrf 生成发送给我们, 然后我们再把这个 _xsrf 发送给 /login 这个 url. 这样一会儿过后我们就要从第一个 GET 得到的响应报文里面去寻找 _xsrf
截图下方的方框说明, 我们不仅登录成功了, 而且服务器还告诉我们的浏览器如何保存它给出的 Cookies 信息. 所以我们也要用 Python 把这些 Cookies 信息记录下来.
这样 Fiddler 的工作就基本结束了!
第二步: 解压缩
简单的写一个 GET 程序, 把知乎首页 GET 下来, 然后 decode() 一下解码, 结果报错. 仔细一看, 发现知乎网传给我们的是经过 gzip 压缩之后的数据. 这样我们就需要先对数据解压. Python 进行 gzip 解压很方便, 因为内置有库可以用. 代码片段如下:
import gzip
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
通过 opener.read() 读取回来的数据, 经过 ungzip 自动处理后, 再来一遍 decode() 就可以得到解码后的 str 了
第二步: 使用正则表达式获取沙漠之舟
_xsrf 这个键的值在茫茫无际的互联网沙漠之中指引我们用正确的姿势来登录知乎, 所以 _xsrf 可谓沙漠之舟. 如果没有 _xsrf, 我们或许有用户名和密码也无法登录知乎(我没试过, 不过我们学校的教务系统确实如此) 如上文所说, 我们在第一遍 GET 的时候可以从响应报文中的 HTML 代码里面得到这个沙漠之舟. 如下函数实现了这个功能, 返回的 str 就是 _xsrf 的值.
import re
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
第三步: 发射 POST !!
集齐 _xsrf, id, password 三大法宝, 我们可以发射 POST 了. 这个 POST 一旦发射过去, 我们就登陆上了服务器, 服务器就会发给我们 Cookies. 本来处理 Cookies 是个麻烦的事情, 不过 Python 的 http.cookiejar 库给了我们很方便的解决方案, 只要在创建 opener 的时候将一个 HTTPCookieProcessor 放进去, Cookies 的事情就不用我们管了. 下面的代码体现了这一点.
import http.cookiejar
import urllib.request
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
getOpener 函数接收一个 head 参数, 这个参数是一个字典. 函数把字典转换成元组集合, 放进 opener. 这样我们建立的这个 opener 就有两大功能:
- 自动处理使用 opener 过程中遇到的 Cookies
- 自动在发出的 GET 或者 POST 请求中加上自定义的 Header
第四部: 正式运行
正式运行还差一点点, 我们要把要 POST 的数据弄成 opener.open() 支持的格式. 所以还要 urllib.parse 库里的 urlencode() 函数. 这个函数可以把 字典 或者 元组集合 类型的数据转换成 & 连接的 str.
str 还不行, 还要通过 encode() 来编码, 才能当作 opener.open() 或者 urlopen() 的 POST 数据参数来使用. 代码如下:
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())
url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode()) # 你可以根据你的喜欢来处理抓取回来的数据了!
代码运行后, 我们发现自己关注的人的动态(显示在登陆后的知乎首页的那些), 都被抓取回来了. 下一步做一个统计分析器, 或者自动推送器, 或者内容分级自动分类器, 都可以.
完整代码如下:
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parse
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'DNT': '1'
}
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解压
_xsrf = getXSRF(data.decode())
url += 'login'
id = '这里填你的知乎帐号'
password = '这里填你的知乎密码'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode())