高性能设计思路,兼谈12306
文章转载只能用于非商业性质,且不能带有虚拟货币、积分、注册等附加条件,转载须注明出处:http://blog.csdn.net/flowingflying/
最近有一些关于12306的技术帖子,例如http://www.zhihu.com/question/22451397,谈及12306的设计。说的很是回事,但是仔细想想,我觉得这类的帖子还是归为洗地贴。实际上,春运的问题不是票务的问题,是运力的问题,供不应求是最关键的矛盾点,而这,我认为是无解。任何系统都不是将峰值容量作为常规容量来设计,否则,在平时就会出现很大的资源浪费,就如同城市不可能为了疏导上下班的高峰期,将所有马路扩大一倍。当然也不是完全没办法,闲时货运、忙时客运,铁路可以去抢快递的肥肉。当如具体如何处理,留给铁道部自己去想。
今年12306确实在性能上比以往提高,但是提高的性能,并不能改变供求关系,更坏的是性能提高极大地方便了黄牛的囤票,某种意义上,情况更糟,还不如去年的烂系统。对用户而言,去年还有机会买到票,今年难多了。12306在防止机器人抢票方面存在漏洞,这是功能上考虑不足,是设计中的失误,不是说性能高就可以掩盖。目前,还有多少人能只采用铁道部提供的web网站,不使用浏览器插件或者抢票软件,能够在紧张车次中抢到票,这点就是12306的错了。今年12306团队的技术水平也有显著提高,亡羊补牢,做了不少补救措施。如果封堵漏洞,是猫和老鼠的游戏,不在本文中讨论。
无论如何,铁路票务系统的技术实现是个很有趣题目,是很好的头脑体操。既然已经有些技术帖子,可由此讨论如何实现高性能的铁路票务系统。
去I去O的选择
铁路票务系统和淘宝系统确实有差异。淘宝的分布式架构很大程度是因为海量数据的存贮,不同淘宝网店的信息,每个商品的图片,而这些铁路票务系统都不需要,要的不是海量数据的存贮,而是海量请求处理。也就是淘宝关键是存贮(含对数据的快速索引,如图片地址),铁路票务要的是计算能力。
这几年,淘宝在推它的去I去O设计,也就是不要IBM,不要Oracle。在技术贴也提到相关的信息:
他们发现市面上可以买到的成套解决方案都不足以应付春运购票负载,所以只能自己改进已有的数据库(注:其实是改用VMware SQLFire/GemFire,这里我之前理解错误)。以前12306用的是小型机,发现性能严重不足,遂改用x86系统+linux平台(原平台为HP Superdome小型机,UNIX系统,Sybase ASE数据库)。最后他们的核心系统用了十几个节点(现在应该是17节点)的多路Xeon E7(具体几路待考),每个节点配1TB内存,数据库全部在内存中运行。2013年春运,12306系统峰值负载11万tps,与2012年淘宝双11活动峰值负载相当,新的系统基本经受住了考验。......直到数日之前,铁总首次向媒体公开了技术改造的详情:分布式集群内存数据技术引领12306技术革命。
实际上IBM+Oracle是个好东西,运营商的计费系统就是这么做的,前几年流行短信拜年时,巨大的话务计费压力并没有问题。但是淘宝不适合,运营商的计费中心是集中式的,淘宝由于海量数据采用分布式,就必须考虑到成本和扩容问题,因此需要分布式的云存储,而Oracle除了价格外,最大的技术瓶颈在于不适用于分布式,它是针对高性能设备的集中数据库处理而设计的。采用Linux,可以采用普通PC机,解决海量数据和低成本扩容问题,而这个解决,也决定了不能采用oracle。当淘宝做大做强后,他的去I去O架构得到业界推崇,甚至是膜拜,有些项目的决策者不考虑项目的实际特点,盲目追求云存在IaaS,追求去I去O。
我N年前的一个计费项目为了提高峰值性能,在启动时将数据库读入内存,数据处理在内存,不进行数据库的I/O操作,这是提高性能的最直接方式。
从铁路票务看,火车票销售的部分适合使用内存处理。而用户信息方面仍可采用常规方式,结合web server的分布处理,也可以读入内存,由于用户帐号是身份证号码,很容易进行索引,将不同的用户分摊到不同机器上处理。对于读入内存方式,具体存储在哪个数据库上并不很重要。
票务架构设计:将核心业务处理从用户处理中分离
哪些可以分布处理,哪些应该集中处理?
铁路票务的核心是出票(含退票),第一步我们可以将出票和用户关联部分分开。用户买票身份认证、请求票权,得到票权后付费等等要与票权发放分开。将票权发放和用户处理分开,保证前者简洁高性能,后者适合web集群和分布处理。

票务架构设计:独立处理模块划分
技术贴这样说道:淘宝的问题是其系统架构是分散度较高的,各个订单之间关联度不大;而12306每出一张票都要对全线路做数据更新(因为一条线路存在多个站点),因此系统负载相较淘宝来说集中很多,直接搬淘宝的方案也无法解决问题。淘宝的应用类型决定了阿里巴巴可以通过部署大量的服务器来分散压力,但12306就不行。
这段话似是而非,所以一开始我说这贴有洗地贴的嫌疑。某一班次的同一类型座位的票是有关联,但是不同线路的票有关联吗?同一线路不同班次的票有关联吗?同一班次不同发车日的票有关联吗?木有啊。即便是同一趟列车,不同类型的票也没有关联,如果从A到B是硬座,再从B到C是卧铺,就算是同一趟车,你也要两张票。因此铁路票务是可以分散处理的,每趟车都可作为独立单元来处理,在不同进程,甚至不同机器上运行。
票务架构设计:合理票务模型设计
至于“12306每出一张票都要对全线路做数据更新(因为一条线路存在多个站点)”。这要看如何设计我们的出/退票模型。假设某趟车有15个站,那么根据始发地点和目的地点数目,根据排列组合为n(n-1)/2=15×14/2=105,但如果这样设计,分为105个商品,就是简单问题复杂化,处理复杂度为N2。合理的做法是分为14段,每段是1个商品,用户购买其中1个商品或者连续的几个商品,处理复杂度为N。

某用户购买站4到站9的票,余票显示为MIN(商品4,商品5,商品6、商品7、商品8),即220张。票权模块收到同时出货商品4,商品5,商品6、商品7、商品8的请求,如果均有库存,则票权模块对着5个商品库存各减1,并出票,否则拒绝。
我不是很明白出一张票就要对全线数据更新这个说法,合理的模型将会避免复杂逻辑。一趟车等于商品池,出一张票就是若干商品的出库。组合有105,但对应的商品只有14,每个组合的存票就是其所对应的各商品最小值。
避免加锁保护
如果多个用户同时请求某趟车的票,要避免同时写操作。如果对数据库进行操作,数据库是可以对同一数据源进行保护,但是读写很慢。你要是问数据库厂家能否支撑春运抢票,他们回复不能是情理之中。
即便放在内存,在代码中进行读写操作,需要避免同时写,要完成一个请求,再完成一个请求,对写的部分需要加锁保护。在Java中,也就是要进行synchronized保护。要提高性能,需要做到:
1、尽量避免加锁保护操作
2、需要保护的代码段尽可能少
先说说第二点,我们将出/退票作为模块独立出来,不考虑用户处理,设计行程池的方式,就是尽可能地简化修改库存的操作。
重点分析一下第一点,即如何避免家锁保护?现在假设
modifyTickets(int requestId /*请求Id,可以对应用户请求*/,
int number /*正表示出票,负表示退票*/,
int[] entities /*货品组,其实可以进行位操作,用32位正整数代表32段行程,
* 不知道一趟火车最多几站,可设置4个32位(128站)作为预留*/);
里面的代码是必须要保护的,我们要避免不同线程或进程(可通过进程间通信来请求)直接操作modifyTickets()。一个有效策略是排队机制。
请求进入队列,而不是直接调用modifyTickets(),ticketProcess()处理队列的请求,由它来调用modifyTickets()。问题又来了,那这就变成加入队列也需要保护。我们知道modifyTickets()的处理是最繁忙的,通过进行队列管理,避免繁忙的核心代码的同步保护,建保护转移到队列管理中。而对于队列的处理,实际上我们还可以利用一些技术手段来进行改善。
双队列的设计
在这里,要强调的是高级语言对复杂处理有很好的封装,程序的简洁应放于首位,目前CPU的处理能力很高,不要为了追求性能,而导致程序复杂。Java中,队列提供List类,语句简单用写list.add(),读list.remove(0),对于多线程的处理d,由于list.add()是一句一行,java不需要编写额外同步保护。实际每趟车的票是有限的,甚至可以采用简单的数组方式,可以将长度设置为(站数-1)×座位数,不能进入队列就直接拒绝,这很简单,实际上不需要那么长队列,减半也是安全的,具体还可以根据剩余商品数来调整最大有效长度。
现在,我们单纯讨论一下,假设一列车的可以很大很大,挂个上百上千车厢,在这种比实际情况疯狂得多的情形下,如何更高效地进行单机处理的方式。
C的处理能力比Java强,就假设以C为编程语言吧。在C里面,队列有很多方式,数组和链表。表格操作增加当然是链表方便,但是高效处理则是数组,特别是数组很方便地进行数据块的copy,能方便进行定位和索引,所以选择数组。
但是数组是有边界的,有限空间不能放置不确定疯狂数量的请求。如果我们以环形数据(到size-1后,又从0开始),有些麻烦,server处理是不能犯错的。若干年前,我有一个在GE口抓包并实时分析过滤的项目,有部分处理在内核代码中写,内核要用自旋锁进行保护,碰到的情况有些类似。队列的管理可以更为灵活,例如采用双队列进行有效处理。
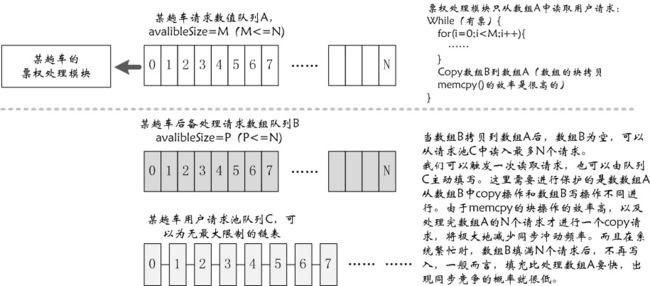
当然“某趟车的票全处理模块”从数组A中读完,就从数组B中读,来回切换,而非当前处理队列可以从请求池中写入用户请求,直至队列满或者变为当前处理队列。但是我觉得上图更为简洁,因为模块间的操作界面更为清晰、独立、简洁(犯错几率不那么大)。
来此不同线程、进程写请求池队列C,这是独立的同步保护单元,不会扩散,不会影响到票权处理模块。数组B是从C中读,和写同步保护无关,当然读完后,要删除还是有些影响,不过一个是在表头操作,一个是在表尾操作,当池中具有一定数量的请求时,这两者将不会相互影响。要知道队列中有数据,是因为处理没有请求来得快。N的大小定多少,需要通过压力测试,找到一个合适的值。
这个设计思想有两个关键要素:
1、避免或减少最繁忙的核心处理模块被多个线程调用
2、避免或减少最繁忙的核心处理模块进行同步保护
由此,我们将队列变成双队列,通过数组B来分割排队和处理。对于发现票为0,可以通知数组B和队列C,直接拒绝请求,直至有退票放出。实际上某段行程存量为0,所涉及的票在web层面就可以直接拒绝用户请求,不需要将请求放到队列C中。
多进程和多线程
对于应用,多线程比多进程要方便得多,可以共享内存空间。但是在极致的性能追求中,我们应当考虑多进程。现在机器是多CPU的,每个CPU可能是双核或4核,如何将处理分摊到不同CPU上是关键。在Linux 2.6之后,据说可以将多线程分摊到多核上处理。但是在Java虚拟机上,情况不清楚。无论如何,多线程多处理器分摊对操作系统还是会带来负担的。
对于多进程,有个好处是,无论C还是Java,都可以在不同的CPU上分摊,而且通过恰当的设计,还可以在不同物理机器上分摊。这对于扩容,可以进行简单的搭积木方式累加。
从铁路票务系统看,单趟车的售票可作为一个进程来处理。极致的情况下,单趟车的售票可以独享一台物理设备。一列车有多少座位,最多能出多少票,我想即便有大量短途,也顶多是万级别,对于万级别的请求,一台设备是很富裕的。事实上,我认为以目前机器的处理能力,从web请求过来后,单趟车票务处理都不需要多线程,直接单线程处理都是足够的,不过为了更好保护票权处理模块,可以分开两个线程,对于用户体验,可能并不会有太大的差异。
关于抽签
有网友提出抽签方式,这个比较有趣。用户可以在指定时间之前通过网站、电话、现场登记方式提交请求,并缴纳50%的违约金(打击票贩),请求某段时间内,请求某地到某地的票权。分批对列车进行抽奖,抽中一个,票池相关的行程进行更新,越早提交请求的,如提前20天申请的,可以提高权重。倒也是解决票供不应求的好方法,只是我不喜欢博彩相类的活动。