hive中的正则表达式
这几天,忙着做一些测试。昨天刚刚做了一个hive的小测试,但是hive中的正则表达式写法让我痛苦不已,这里记录下问题和一些想法。
背景:
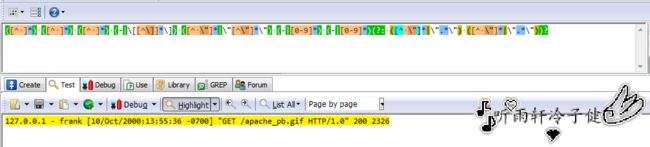
前几天拿来apache日志,用hive的正则进行匹配,发现匹配出来的字段算是NULL,但是我用RegexBuddy工具显示能够匹配的到啊!例子如下(我拿正常的apache日志来比较,我的apache日志格式被更改过)
1、apache日志格式:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 23262、正则表达式:
([^ ]*) ([^ ]*) ([^ ]*) (-|\[[^\]]*\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?
3.工具匹配后结果:
4.把正则拿到hive里面做create table操作,结果匹配出的全是null,之后查阅了资料吧正则写成如下格式就可以匹配了(多了转义符号):
([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?
主要原因有两个之后会详细讲解。
原因:
1、首先理解下转义字符,就是把具有特殊意义的字符例如?或[等。编程"单纯"的字符串,例如"\?"就表示'?'本身。
2、但是在方括号里面情况有点复杂:
如果你想匹配*?+这样的字符,第一点想到的是[\*\?\+];
首先要理解的是,在hive中‘\’本身就代表转义字符,这与原有正则里面的转义,也有点不同,意思是:要经过两次转义后(hive
和正则)才会匹配,我们在背景里面单一的做了正则的转义,而没有做hive的转义(这里面有点混乱,需要读者自己理清楚),但是在再加上一个转义符号后,就变得正常。我们的例子来说正常的hive写法应该为[\\*\\?\\+]。
这里只是基本的一些想法,也是看了别人的文章总结的:
Oracle,green plum,hive中正则表达式的元字符转义比较杂谈
在处理后正则语法就算成功,但是还是匹配不到字段,我用了最简单的正则也不能够匹配字符串里面的字段,后来做个测试,原因如下:
hive的正则表达式只支持全匹配,意思是:当读入一行日志做正则匹配时,必须从这一行的开始进行匹配到这一行的结束,不能够从中间进行匹配,就算只要中间的字段,也要用‘.’吸收掉前的或后面的”全部“字符。
错误的匹配方法(没有考虑hive转义,只有正则转义时,只匹配中间的部分):
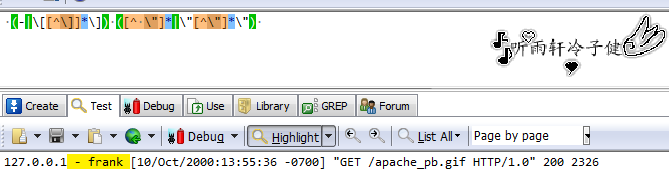
正确的方法: