单词到散列表的唯一映射算法
散列表是一种数据结构。可用散列表中的元素唯一地指向另一种数据结构。如编程珠玑介绍的用散列表元素指向存储了“单词和单词数”的结构体,单词从输入流(一篇文章,一本书)中得来。可以将每次从输入流中读到的数据存储在栈和堆中。

Figure1:散列表和存储数据的数据结构
如上图,用散列表元素指向结构体的方便之处在于不管数据存储在哪里,都可以通过散列表元素将其访问到。散列表的存在是为了更好的管理存储数据的数据结构。我们希望通过散列表能够更好的访问存储数据的数据结构。如统计输入流中的不同单词,并统计每个单词的数目。为了实现这个目标,涉及到两个问题:
-
如何将新读入的单词保存到一个从未指向任何数据结构的散列表元素。
-
如果采用随机的方法,如和保证将每个不同的单词都得到存储并且对每个单词的计数准确无误。
存储输入数据的数据结构可以是如下结构:
| struct _word{ char *word; int count; }word; |
所以散列表就是此种数据类型:struct _word *pword[SIZE];。SIZE的选取要合适,要大于输入流的不同单词数。
选堆作为存储地:由于每个word的大小不一,输入单词的数目未知,为了给输入数据分配适当的空间而避免使用栈空间不够或太多,所以使用堆内存来保存输入流中的单词会更好。每当读取到一个单词的时候我们就为其分配一个恰当的堆内存存储它。如果使用栈来存储数据,我们一般就直接引用变量名或者数组名就能够索引到数据。只是堆内存无名,只有通过指针来索引。
首先,在程序开始时将散列表中的每一个元素初始化为NULL,避免使用野指针。
其次,每当读入一个单词时,判断是否为之前读入过的单词,若是新单词则有分配堆空间的操作(p = malloc(sizeof(word),p->word = malloc(sizeof(inputword)),然后存储单词在word指向的堆中)。然后将p的值赋给散列表中的某一个元素。若非新单词,则通过指向此单词数据结构的散列表元素为此单词计数。
为避免使用额外的代价实现以上功能,出现了映射。这里的映射就是每当输入一个单词时,可以根据单词的特性唯一地映射到散列表中的一个元素之上(标识每一个散列表元素的是下标值),这就解决了以上提到的两个问题。如此,若是输入重复单词时,会映射到散列表中相同的一个元素之上,就能够为单词计数了。散列表元素的下标是数字,字符串的字符是ASCII,可以由这里出发让单词和散列表元素发生一一对应的关系。
其实,无论多长的一个单词,我们都可以将这个单词看成是由ASCII组成的,特殊的(分治思想)将其看成如下格式:
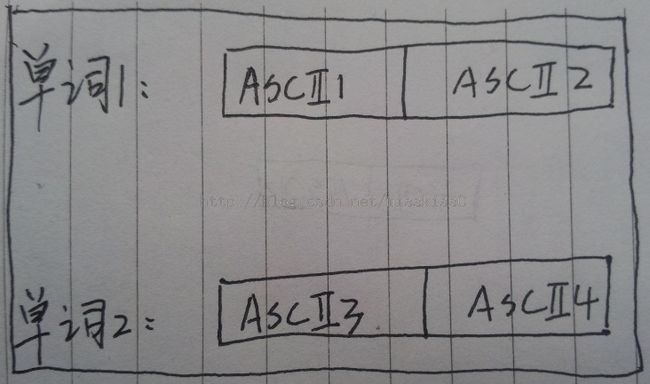
Figure2:用分治法等效单词的ASCII值计算
1)根据组成不同单词的字符不同,可以直接根据每个单词的ASCII值来唯一的标识每个单词。但不能保证不同的单词其ASCII就会不同。”on”和”on”就是最好的例子。
2)分析不同单词拥有相同的ASCII情况,只有下列三个等式中的其一成立时都可以得到不同单词具有相同的ASCII值。
-
等式1,ASCII1 = ASCII4且ASCII3 = ASCII2。
-
等式2,ASCII1 - ASCII3 = ASCII4 - ASCII2。
-
等式3,ASCII1 - ASCII4 = ASCII3 - ASCII2。
为了解决为不同单词具有相同ASCII的情况,为每个字符的ASCII值乘上一个正整数m^n(m> 1,如字符串”string”,i对应的n值为4,g对应的n值为6),这就使得两个单词新的ASCII值,单词1的ASCII值变为m^2 *ASCII1 + m * ASCII2;单词2的ASCII值变为m^2 *ASCII3 + m * ASCII4。这似乎就可以使得不同的单词具有不同的ASCII值。分析如下:
-
第一种情况,乘以系数m后,根据等式1,很明显此时单词1和单词2的ASCII已经不再相同。
-
第二种情况,m^2 * (ASCII1 - ASCII3) != m(ASCII4 - ASCII2)。
-
第三种情况,m^2 * ASCII1 - m *ASCII4 ?= m^2 *ASCII3 - m *ASCII2 --> m * ASCII1 - ASCII4 ?= m *ASCII3 - ASCII2,若要使这个等式成立则根据等式3则再需要(m-1) ASCII1 = (m-1) ASCII3,当这个条件成立时,再根据等式3得到ASCII4 = ASCII2。此时得到ASCII1 = ASCII2且ASCII3 = ASCII4,这个等式说明:单词1和单词2是同一个单词。
编程珠玑中是将每个字符扩大了31倍,这可以保证每个单词具有不同的标识值。笔记中的证明结果为:只要乘以一个大于1的正整数即可达到结果。
每个单词的唯一整数标识问题解决了,假设根据以上计算能得到的每个单词的新ASCII值为newASCII。然后就是将每个单词映射到散列表中的元素之上了。使用如下语句可以实现重复单词的计数:
| h = newASCII % SIZE; //SIZE为散列表的大小 pword[h]->word.count++; |
%使得h的值在不同的newASCII下可以得到[0,SIZE)中的不同值。可见程序中整数的除法。
最后,不能让保存堆地址的散列表元素值被覆盖。需要散列表元素值操作存储单词的结构体,最好还要靠它释放堆内存。
总结:对单词的ASCII值稍加运算为每个字符的ASCII值乘上一个正整数m^n(m > 1,如字符串”string”,i对应的n值为4,g对应的n值为6)就解决了存储每个单词的数据结构与散列表元素的一一对应。
此次笔记记录完毕。