Oracle DB 诊断数据库
• 检测和修复数据库损坏:
– 使用新的RMAN 数据修复命令执行以下操作:
— 列出故障
— 接收修复建议
— 修复故障
– 执行主动故障检查
• 处理块损坏:
– 实时验证块完整性
– 执行块介质恢复
• 设置自动诊断资料档案库
• 运行健康检查
- 数据恢复指导
• 快速检测、分析和修复故障
• 将对用户的干扰降到最低
• 停机时和运行时的故障
• 用户界面:
– EM GUI 界面(多个路径)
– RMAN 命令行
• 支持的数据库配置:
– 单实例
– 非RAC
– 支持故障转移到备用数据库,但不支持分析和修复备用数据库
在发生错误时,数据恢复指导可自动收集数据故障信息。此外,它还可以主动检查故障。
在这种模式下,它有可能在数据库进程发现损坏并指出错误之前就检测和分析数据故障(请注意,修复始终由人控制。)
数据故障可能会很严重。例如,如果缺少最新的日志文件,则无法启动数据库。一些数据故障(如数据文件中的块损坏)不是灾难性故障,因为它们不会使数据库停机,也不会阻止你启动Oracle 实例。数据恢复指导可以处理两种情况:一种情况是你无法启动数据库(因为缺少一些必需的数据库文件,或者这些数据库文件不一致或已损坏),另一种情况是运行时发现文件损坏。
用户界面
如删除了
/u01/app/oracle/oradata/test0924/lxtb01.dbf,实验:
[oracle@rtest ~]$ rm /u01/app/oracle/oradata/test0924/lxtb01.dbf
[oracle@rtest ~]$ ls /u01/app/oracle/oradata/test0924/lxtb01.dbf
ls: /u01/app/oracle/oradata/test0924/lxtb01.dbf: No such file or directory
可从Oracle Enterprise Manager (EM) Database Control 和Grid Control 使用数据恢复指导。
出现故障时,可使用多种方法访问数据恢复指导。以下示例都是从“Database Instance(数据库实例)”主页开始的:
• “Availability(可用性)”选项卡页> Perform Recover(执行恢复)> Advise and Recover(建议和恢复)
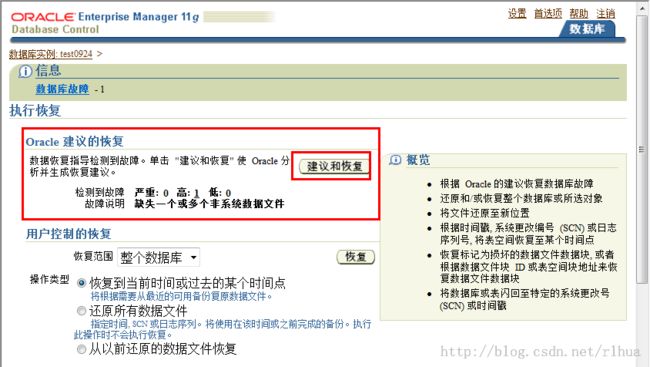
点击恢复和建议

点击建议:
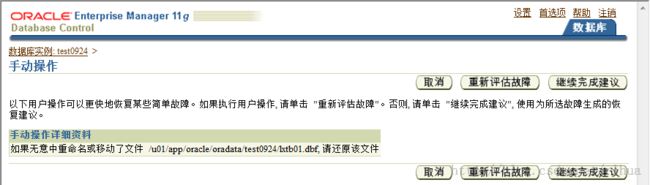
点击完成建议:

点击继续:

点击提交恢复作业,后查看结果,恢复成功。

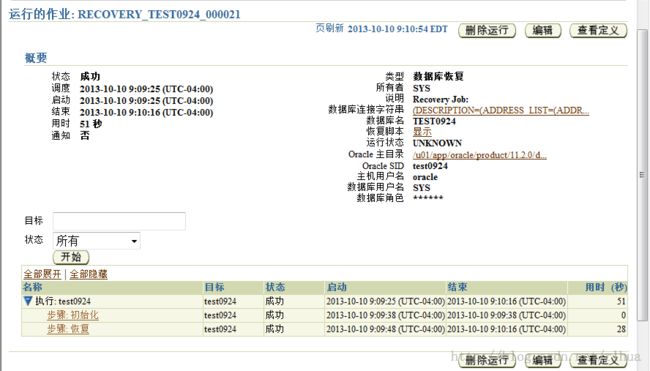
命令行恢复如下:
RMAN> list failure all;
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------------- -------
1242 HIGH OPEN 2013-10-10:09:19:39 One or more non-system datafiles are missing
RMAN> advise failure;
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------------- -------
1242 HIGH OPEN 2013-10-10:09:19:39 One or more non-system datafiles are missing
analyzing automatic repair options; this may take some time
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=8 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
no manual actions available
Optional Manual Actions
=======================
1. If file /u01/app/oracle/oradata/test0924/lxtb01.dbf was unintentionally renamed or moved, restore it
Automated Repair Options
========================
Option Repair Description
------ ------------------
1 Restore and recover datafile 6
Strategy: The repair includes complete media recovery with no data loss
Repair script: /u01/app/oracle/diag/rdbms/test0924/test0924/hm/reco_4147130920.hm
RMAN> repair failure;
Strategy: The repair includes complete media recovery with no data loss
Repair script: /u01/app/oracle/diag/rdbms/test0924/test0924/hm/reco_4147130920.hm
contents of repair script:
# restore and recover datafile
sql 'alter database datafile 6 offline';
restore datafile 6;
recover datafile 6;
sql 'alter database datafile 6 online';
Do you really want to execute the above repair (enter YES or NO)? yes
executing repair script
sql statement: alter database datafile 6 offline
Starting restore at 2013-10-10:09:22:13
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00006 to /u01/app/oracle/oradata/test0924/lxtb01.dbf
channel ORA_DISK_1: reading from backup piece /u01/app/oracle/fast_recovery_area/TEST0924/backupset/2013_10_09/o1_mf_nnndf_TAG20131009T144059_95c8sy7r_.bkp
channel ORA_DISK_1: piece handle=/u01/app/oracle/fast_recovery_area/TEST0924/backupset/2013_10_09/o1_mf_nnndf_TAG20131009T144059_95c8sy7r_.bkp tag=TAG20131009T144059
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:03
Finished restore at 2013-10-10:09:22:17
Starting recover at 2013-10-10:09:22:17
using channel ORA_DISK_1
starting media recovery
archived log for thread 1 with sequence 132 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_132_95cjyqkg_.arc
archived log for thread 1 with sequence 133 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_133_95cwmnct_.arc
archived log for thread 1 with sequence 134 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_134_95d2kt5q_.arc
archived log for thread 1 with sequence 135 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_135_95d2m62x_.arc
archived log for thread 1 with sequence 136 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_10/o1_mf_1_136_95dfc1wt_.arc
archived log for thread 1 with sequence 137 is already on disk as file /u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_10/o1_mf_1_137_95f1586n_.arc
archived log file name=/u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_132_95cjyqkg_.arc thread=1 sequence=132
archived log file name=/u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_133_95cwmnct_.arc thread=1 sequence=133
archived log file name=/u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_134_95d2kt5q_.arc thread=1 sequence=134
archived log file name=/u01/app/oracle/fast_recovery_area/TEST0924/archivelog/2013_10_09/o1_mf_1_135_95d2m62x_.arc thread=1 sequence=135
media recovery complete, elapsed time: 00:00:01
Finished recover at 2013-10-10:09:22:19
sql statement: alter database datafile 6 online
repair failure complete
• Database Instance Health(数据库实例健康状况)> 单击特定的链接,例如,“Incidents(意外事件)”部分中的ORA 1578 >“Support Workbench(支持工作台)”的“Problems Detail(问题详细资料)”页> Data Recovery Advisor(数据恢复指导)
• Database Instance Health(数据库实例健康状况)>“Related Links(相关链接)”部分:Support Workbench(支持工作台)>“Checker Findings(检查器查找结果)”选项卡页:Launch Recovery Advisor(启动恢复指导)
• Related Links(相关链接):Advisor Central(指导中心)>“Advisors(指导)”选项卡页:Data Recovery Advisor(数据恢复指导)
• Related Links(相关链接):Advisor Central(指导中心)>“Checkers(检查器)”选项卡页:Details(详细资料)>“Run Detail(运行详细资料)”选项卡页:Launch Recovery Advisor(启动恢复指导)
也可以通过RMAN 命令行使用它。例如:
rman target / nocatalog
rman> list failure all;
支持的数据库配置
在当前版本中,数据恢复指导支持单实例数据库,不支持Oracle Real Application Clusters (RAC) 数据库。
数据恢复指导不能使用从备用数据库传送而来的块或文件修复主数据库中的故障。同时,也无法使用数据恢复指导诊断并修复备用数据库上的故障。但是,数据恢复指导确实支持故障转移到备用数据库(作为修复方案,如上所述)。
- 数据恢复指导
通过理清混乱缩短停机时间:

Oracle Database 11g中的自动诊断工作流按如下方式执行。使用数据恢复指导,只需启动建议和修复。
1.健康状况监视器会自动执行检查,并将故障及其故障现象作为“查找结果”记录到自动诊断资料档案库(ADR) 中。
2.数据恢复指导将查找结果与故障合并在一起,并按故障严重程度(严重或高)列出以前执行的评估结果。
3.请求提供有关故障的修复建议时,数据恢复指导会将故障映射到自动和手动修复选项,检查基本可行性,然后提供修复建议。
4.可以手动执行修复,也可请求数据恢复指导执行修复。
5.除了健康状况监视器和数据恢复指导自动执行的主要“被动”检查之外,Oracle 还建议使用VALIDATE命令执行“主动”检查。
- 数据故障
可通过检查来检测数据故障,检查是评估数据库或其组件健康状况的诊断过程。每个检查可对一个或多个故障进行诊断,然后将其映射到修复。
检查可以是被动检查,也可以是主动检查。数据库中出现错误时,将自动执行“被动检查”。此外,也可以启动“主动检查”,例如,执行VALIDATE DATABASE命令。
在Oracle Enterprise Manager 中,如果发现数据库处于“停机”或“已装载”状态,请选择“Availability(可用性)> Perform Recovery(执行恢复)”,或单击“Perform Recovery(执行恢复)”按钮。
- 数据故障:示例
• 组件不可访问,例如:
– 缺少操作系统级别的数据文件
– 访问权限不正确
– 表空间脱机等
• 物理损坏,如块校验和故障或块头字段值无效
• 逻辑损坏,如字典不一致、行片段损坏、索引条目损坏或事务处理损坏
• 不一致,如控制文件比数据文件和联机重做日志旧或新
• I/O 故障,如超过打开的文件数限制、通道不可访问、网络或I/O 错误
数据恢复指导可以分析故障并建议问题修复选项。
- 数据恢复指导RMAN 命令行界面
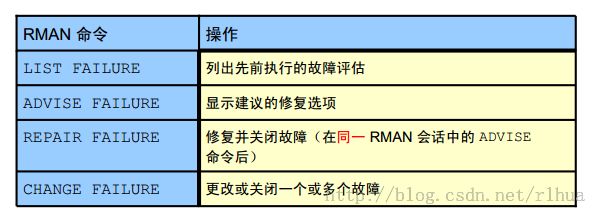
如果怀疑或已知道数据库出现故障,则可使用LIST FAILURE命令获得这些故障的信息。可以列出所有故障或部分故障并以多种方式限制输出。故障由故障号唯一标识。请注意,这些故障号不是连续的,因此它们之间的间隔没有任何意义。
ADVISE FAILURE命令将显示指定故障的建议修复选项。它打印输入故障概要并隐式关闭已修复的所有打开的故障。没有使用任何选项时,默认行为是对记录在ADR 中优先级为CRITICAL和HIGH的所有故障提供建议。
REPAIR FAILURE命令在
同一RMAN 会话中的ADVISE FAILURE命令之后使用。默认情况下,该命令使用当前会话中上次执行ADVISE FAILURE命令时建议的一个修复选
项。如果没有任何修复选项,REPAIR FAILURE命令将启动隐式ADVISE FAILURE命令。修复完成后,该命令会关闭故障。
CHANGE FAILURE命令将更改故障优先级或关闭一个或多个故障。仅能更改HIGH或LOW故障优先级。修复故障后,将隐式关闭打开的故障。不过,也可以显式关闭故障。
- 列出数据故障
RMAN
LIST FAILURE命令列出先前执行的故障评估。
• 包括新诊断的故障
• 删除关闭的故障(默认情况下)
语法:
LIST FAILURE
[ ALL | CRITICAL | HIGH | LOW | CLOSED |
failnum[,failnum,…] ]
[ EXCLUDE FAILURE failnum[,failnum,…] ]
[ DETAIL ]
RMAN LIST FAILURE命令列出故障。如果目标实例使用恢复目录,它可以处于
STARTED模式下,否则必须处于MOUNTED模式下。
LIST FAILURE命令不启动检查来
诊断新故障;它将列出先前执行的评估的结果。重复执行LIST FAILURE命令可重新验
证所有现有的故障。如果数据库诊断出新的故障(在命令执行之间),则会显示这些新故障。如果用户手动修复故障或临时故障消失,则数据恢复指导会将这些故障从LIST FAILURE输出中删除。以下是语法说明:
• failnum:要为其显示修复选项的故障数。
• ALL:列出所有优先级的故障。
• CRITICAL:列出优先级为CRITICAL且状态为OPEN的故障。这些故障(如控制文件缺失)使整个数据库不可用,因此需要立即进行关注。
• HIGH:列出优先级为HIGH且状态为OPEN的故障。这些故障(如归档重做日志缺失)使数据库部分不可用或不可恢复,因此应尽快修复。
• LOW:列出优先级为LOW且状态为OPEN的故障。低优先级的故障可以等到修复了更重要的故障后再进行修复。
• CLOSED:仅列出关闭的故障。
• EXCLUDE FAILURE:从列表中排除指定的故障号。
• DETAIL:列出故障并展开合并的故障。例如,如果一个文件中有多个块损坏,则DETAIL选项将列出每个块损坏。
- 修复建议
RMAN
ADVISE FAILURE命令:
• 显示输入故障列表概要
• 包括警告(如果ADR 中出现新故障)
• 显示手动核对清单
• 列出一个建议的修复选项
• 生成修复脚本(用于自动或手动修复)
. . .
Repair script:
/u01/app/oracle/diag/rdbms/orcl/orcl/hm/reco_2979
128860.hm
RMAN>
RMAN
ADVISE FAILURE命令显示针对指定故障建议的修复选项。ADVISE FAILURE命令打印输入故障概要。该命令会隐式关闭已修复的所有打开的故障。
默认行为(没有使用任何选项时)是对
自动诊断资料档案库(ADR) 中记录的CRITICAL和HIGH优先级的所有故障提供建议。如果自上次执行LIST FAILURE命令后ADR 中记录了新故障,则在对所有CRITICAL和HIGH故障提供建议前,该命令将包含一个
WARNING。
可执行两个常规修复选项:无数据丢失修复和数据丢失修复。
数据恢复指导在生成自动修复选项时会生成一个脚本,用于显示RMAN 计划如何修复故障。如果不希望数据恢复指导自动修复故障,可从该脚本开始执行手动修复。该脚本的操作系统(OS) 位置将显示在命令输出的末尾。可以检查此脚本,并对其进行自定义(如果需要),还可以手动执行该脚本(例如,你的审计线索要求建议执行手动操作时)。
语法
ADVISE FAILURE
[ ALL | CRITICAL | HIGH | LOW | failnum[,failnum,…] ]
[ EXCLUDE FAILURE failnum [,failnum,…] ]
- 执行修复
RMAN
REPAIR FAILURE命令:
• 在ADVISE FAILURE命令之后执行
• 修复指定故障
• 关闭修复的故障
语法:
REPAIR FAILURE
[USING ADVISE OPTION integer]
[ { {NOPROMPT | PREVIEW}}...]
此命令应在同一RMAN 会话中在ADVISE FAILURE命令之后使用。默认情况下(没有指定任何选项时),该命令使用当前会话中上次执行ADVISE FAILURE时建议的一个修复选项。如果没有任何修复选项,REPAIR FAILURE命令将启动隐式ADVISE FAILURE命令。
使用USING ADVISE OPTION integer,可按选项编号指定所需的修复选项(从ADVISE FAILURE命令中);这不是故障号。
默认情况下,需要确认是否执行该命令,因为可能需要花费许多时间完成大量更改。在执行修复期间,该命令的输出指明正在执行的修复阶段。修复完成后,该命令会关闭故障。
无法运行多个并发修复会话。但是,可以运行并发
REPAIR … PREVIEW会话。
• PREVIEW:不执行修复,而是显示先前生成的RMAN 脚本以及所有修复操作和注释。
• NOPROMPT:不要求确认。
- 分类(和关闭)故障
RMAN
CHANGE FAILURE命令:
• 更改故障优先级(CRITICAL除外)
• 关闭一个或多个故障
示例:
RMAN> change failure 5 priority low;
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------- -------
5 HIGH OPEN 20-DEC-06 one or more datafiles are missing
Do you really want to change the above failures (enter YES or NO)? yes
changed 1 failures to LOW priority
CHANGE FAILURE命令用于更改故障优先级或关闭一个或多个故障。
语法
CHANGE FAILURE
{ ALL | CRITICAL | HIGH | LOW | failnum[,failnum,…] }
[ EXCLUDE FAILURE failnum[,failnum,…] ]
{ PRIORITY {CRITICAL | HIGH | LOW} |
CLOSE }- 将故障的状态更改为关闭
[ NOPROMPT ]- 不要求用户确认
只能将故障优先级
从HIGH更改为LOW,以及从LOW更改为HIGH。
更改CRITICAL优
先级是错误做法。(将故障的优先级从HIGH更改为LOW的一个原因是避免该故障显示在LIST FAILURE命令的默认输出列表中。例如,如果某个损坏的块具有HIGH优先级,且该块位于很少使用的表空间中,你可能希望将其临时更改为LOW。)
修复故障后,将隐式关闭打开的故障。不过,你也可以显式关闭故障。这需要重新评估其它所有打开的故障,因为其中的某些故障会因该故障的关闭而变得不相关。
默认情况下,
该命令要求用户确认请求的更改。
- 数据恢复指导视图
查询V$视图:
• V$IR_FAILURE:所有故障的列表,其中包括已关闭的故障(LIST FAILURE命令的结果)
• V$IR_MANUAL_CHECKLIST:手动建议的列表(ADVISE FAILURE命令的结果)
• V$IR_REPAIR:修复的列表(ADVISE FAILURE命令的结果)
• V$IR_FAILURE_SET:故障和建议标识符的交叉引用
- 最佳做法:主动检查
调用对数据库及其组件的主动健康检查:
• 健康状况监视器或RMAN
VALIDATE DATABASE命令
• 检查逻辑和物理损坏
• 在ADR 中记录查找结果
对于非常重要的数据库,你可能需要执行其它主动检查(可以在每天的低峰时段执行)。
可
通过健康状况监视器或使用RMAN VALIDATE命令安排定期的健康检查。通常,如果被动检查在数据库组件中检测到故障,则可能需要对受影响的组件执行更全面的检查。RMAN
VALIDATE DATABASE命令用于调用对数据库及其组件的健康检查。它扩展了现有VALIDATE BACKUPSET命令。在验证期间检测到的所有问题都会显示出来,这些问题进而会启动故障评估。如果检测到故障,则该故障
会作为查找结果记录到ADR 中。可以使用
LIST FAILURE命令查看资料档案库中记录的所有故障。
VALIDATE命令支持对单个备份集和数据块进行验证。在物理损坏中,数据库根本无法识别块。在逻辑损坏中,块的内容在逻辑上不一致。默认情况下,
VALIDATE命令只检查物
理损坏。也可以指定CHECK LOGICAL来检查逻辑损坏。
块损坏可分为
块间损坏和块内损坏。在块内损坏中,块本身发生损坏,可能是物理损坏也可能是逻辑损坏。
在块间损坏中,块与块之间发生的损坏只能是逻辑损坏。VALIDATE命令只检查块内损坏。
- 什么是块损坏
• 只要对块执行读或写操作,就会执行下列一致性检查。
– 块版本
– 高速缓存中的DBA(数据块地址)值与块缓冲区中的DBA 值比较的结果
– 块校验和(如果启用)
• 损坏的块被标识为以下类别:
– 介质损坏
– 逻辑(或软件)损坏
所谓损坏的数据块,是指块没有采用可识别的Oracle 格式,或者其内容在内部不一致。通常情况下,损坏是由硬件故障或操作系统问题引起的。
Oracle DB 将损坏的块标识为“逻辑损坏”或“介质损坏”。如果是逻辑损坏,则是Oracle 内部错误。Oracle DB 检测到不一致之后,就将逻辑损坏的块标记为损坏。如果是介质损坏,则是块格式不正确;从磁盘读取的块没有包含有意义的信息。
正如上面所知,可以使用数据恢复指导修复一些数据故障和损坏。现在将学习手动诊断和修复损坏的方法。
通过恢复块,或者删除包含损坏块的数据库对象(或同时采用这两种方式),可以修复介质损坏的块。如果介质损坏是由硬件故障引起的,则只有修复了硬件故障后,才能彻底解决问题。
- 块损坏故障现象:ORA-01578
ORA-01578错误:"ORACLE data block corrupted (file # %s, block # %s)":
• 发现损坏的数据块时生成此信息
• 始终返回相对文件号和相对块号
• 返回到发出查询的会话(该查询在发现损坏时执行)
• 显示在alert.log文件中
块损坏故障现象:ORA-01578
一般情况下,ORA-01578错误是由硬件问题引起的。如果ORA-01578错误始终返回相同的参数,则最可能的原因是块介质损坏。
如果返回的参数每次都有变化,则可能存在硬件问题。应检查内存和页面空间,并检查I/O 子系统,以便查找有问题的控制器。
注:ORA-01578返回相对文件号,但伴随出现的ORA-01110错误会显示绝对文件号。
- 如何处理损坏
• 检查预警日志和操作系统日志文件。
• 使用可用的诊断工具,找出损坏的类型。
• 多次运行检查功能,确定错误是否持续存在。
• 根据需要,从损坏的对象中恢复数据。
• 解决硬件问题:
– 内存条
– 磁盘控制器
– 磁盘
• 根据需要,从损坏的对象中恢复或还原数据。
如何处理损坏
始终尝试确定错误是否持续出现。
多次运行ANALYZE命令;如果可能,可执行关闭再启动操作,然后再次尝试早先发生故障的操作。查找是否有其它损坏。如果发现一个损坏的块,则可能还存在其它损坏的块。
硬件故障必须立即解决。遇到硬件问题时,应与供应商取得联系,在检查并修复了计算机后再继续工作。此时应运行一次全面的硬件诊断会话。
硬件故障的类型可能会有很多种:
•I/O 硬件或固件故障
• 操作系统I/O 或高速缓存问题
• 内存或分页问题
• 磁盘修复实用程序
- 设置检测损坏的参数

EM > Server(服务器)> Initialization Parameters(初始化参数)
设置检测损坏的参数
可以使用DB_ULTRA_SAFE参数来简化管理。它会影响下列参数的默认值:
• DB_BLOCK_CHECKING,用于启动对数据库块的检查。此检查通常可防止内存和数据损坏。(默认值:FALSE,建议值:FULL)
• DB_BLOCK_CHECKSUM,将每个数据块写入到磁盘时,在其高速缓存标头中启动校验和的计算和存储。校验和有助于检测由基础磁盘、存储系统或I/O 系统引起的损坏。(默认值:TYPICAL,建议值:TYPICAL)
• DB_LOST_WRITE_PROTECT,用于启动对“丢失的写入”的检查。如果I/O 子系统指示块写入已完成,但该块尚未完全写入到持久存储中,则物理备用数据库上会发生
数据块写入丢失。当然,写入操作在主数据库中已完成。(默认值:TYPICAL,建议值:TYPICAL)
如果显式设置了其中任何一个参数,则你设置的值将保持有效。DB_ULTRA_SAFE参数(Oracle Database 11g中的新增参数)仅更改这些参数的默认值。
sys@TEST0924> show parameter DB_ULTRA_SAFE
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_ultra_safe string OFF
- 设置检测损坏的参数

根据系统对块损坏的容忍度,可以加强对块损坏的检查。启用DB_ULTRA_SAFE参数(默认值:OFF)会导致系统开销增加,因为这些检查更加密集。开销量与每秒更改的块数相关,所以无法进行简单量化。对于“高更新的”应用程序,CPU 使用率会显著增加,大约在10% 到20% 之间,不过可能更高。通过分配额外的CPU 可减轻此开销。
• 当DB_ULTRA_SAFE参数设置为DATA_ONLY时,DB_BLOCK_CHECKING参数设置为MEDIUM。这会检查块中的数据在逻辑上是否一致。内存中的块内容发生更改后
(例如,在执行UPDATE或INSERT命令、执行磁盘上读取或在Oracle RAC 中实例间传送块后),将执行基本的块标头检查。此级别的检查包括对非索引表块进行的语
义块检查。
• 当DB_ULTRA_SAFE参数设置为DATA_AND_INDEX时,DB_BLOCK_CHECKING参数设置为FULL。除了上面的检查外,还会执行语义检查以查找索引块(即遇到损坏
时,可实际删除和重新构造从属对象的块)。
• 当DB_ULTRA_SAFE参数设置为DATA_ONLY或DATA_AND_INDEX时,DB_BLOCK_CHECKSUM参数设置为FULL,DB_LOST_WRITE_PROTECT参数设置为
TYPICAL。
- 块介质恢复
块介质恢复:
• 降低平均恢复时间(MTTR)
• 提高介质恢复期间的可用性
– 恢复期间数据文件保持联机状态
– 只有正在恢复的块是不可访问的
• 是使用RMAN
RECOVER...BLOCK命令调用的
– 使用闪回日志以及完全备份或0 级备份还原块
– 介质恢复是使用重做日志执行的
•
V$DATABASE_BLOCK_CORRUPTION视图显示标记为损坏的块
大多数情况下,第一次遇到损坏时,数据库会将块标记为介质损坏,然后将其写到磁盘上在该块得到恢复之前,不能对其执行任何后续读取操作。只能对标记为损坏或者未通过损坏检查的块执行块恢复。块介质恢复是使用RMAN
RECOVER...BLOCK命令执行的。默认情况下,RMAN 会搜索闪回日志以查找好的块副本,然后在完全备份或0 级增量备份中搜索块。如果RMAN 找到了好的副本,则会还原这些副本,并对块执行介质恢复。块介质恢复只能使用重做日志进行介质恢复,不能使用增量备份。
V$DATABASE_BLOCK_CORRUPTION视图显示由数据库组件(如RMAN 命令、ANALYZ
dbv、SQL 查询等)标记为损坏的块。对于以下类型的损坏此视图会增加相应的行:
• 物理/介质损坏:数据库无法识别块:校验和无效、块内容全部为零或者块标头不完整物理损坏检查是默认启用的。
• 逻辑损坏:块的校验和有效,块头和块尾也匹配,但是内容不一致。块介质恢复不能修复逻辑块损坏。默认情况下,逻辑损坏检查处于禁用状态。通过指定BACKUP、
RESTORE、RECOVER和VALIDATE命令的CHECK LOGICAL选项,可以启用逻辑损坏检查。
- 块介质恢复的先决条件
• 目标数据库必须处于ARCHIVELOG 模式。
• 包含损坏块的数据文件的备份必须是完全备份或0 级备份。
– 要使用代理副本,必须先将它们还原到非默认位置。
• RMAN 只能使用归档重做日志进行恢复。
• 可从闪回日志(如果可用)还原损坏的数据块。
块介质恢复的先决条件
下列先决条件适用于RECOVER ... BLOCK命令:
• 目标数据库必须以ARCHIVELOG 模式运行,并且必须是打开的,或是使用当前控制文件装载的。
• 包含损坏块的数据文件备份必须是完全备份或0 级备份,不能是代理副本。如果只存在代理副本备份,则可将它们还原到磁盘上的非默认位置;在这种情况下,RMAN
会认为它们是数据文件副本,在块介质恢复过程中会在其中搜索块。
• RMAN 只能使用归档重做日志进行恢复。RMAN 不能使用1 级增量备份。块介质恢复不能恢复丢失或无法访问的归档重做日志,但有时可以恢复丢失的重做记录。
• 必须在目标数据库上启用闪回数据库,这样RMAN 才能在闪回日志中搜索损坏块的好副本。如果启用了闪回日志记录,而且该日志记录包含损坏块的较旧但未损坏的版本,则RMAN 可以使用这些块,因而可能会提高恢复的速度。
- RECOVER...BLOCK命令
RMAN RECOVER...BLOCK命令:
• 确定包含要进行恢复的块的备份
• 读取备份并将请求的块累积到内存缓冲区
• 必要时,通过从备份中读取归档日志来管理块介质恢复会话
RECOVER DATAFILE 6 BLOCK 3; Recover a single block
RECOVER
DATAFILE 2 BLOCK 43
DATAFILE 2 BLOCK 79
DATAFILE 6 BLOCK 183;
Recover multiple blocks in multiple data files
RECOVER CORRUPTION LIST;
Recover all blocks logged in V$DATABASE_BLOCK_CORRUPTION
恢复单个块
在进行块恢复之前,必须确定损坏的块。一般情况下,会在以下位置中报告块损坏:
• LIST FAILURE、VALIDATE或BACKUP ... VALIDATE命令的结果
• V$DATABASE_BLOCK_CORRUPTION视图
• 标准输出中的错误消息
• 预警日志文件和用户跟踪文件(在V$DIAG_INFO视图中标识)
•SQL ANALYZE TABLE和ANALYZE INDEX命令的结果
•DBVERIFY 实用程序的结果
例如,可能会在用户跟踪文件中发现以下消息:
ORA-01578: ORACLE data block corrupted (file # 7, block # 3)
ORA-01110: data file 7: '/oracle/oradata/orcl/tools01.dbf'
ORA-01578: ORACLE data block corrupted (file # 2, block # 235)
ORA-01110: data file 2: '/oracle/oradata/orcl/undotbs01.dbf'
确定了块以后,在RMAN 提示符下运行RECOVER ... BLOCK命令,指定损坏块的
文件号和块号。
RECOVER
DATAFILE 7 BLOCK 3
DATAFILE 2 BLOCK 235;
- 自动诊断工作流
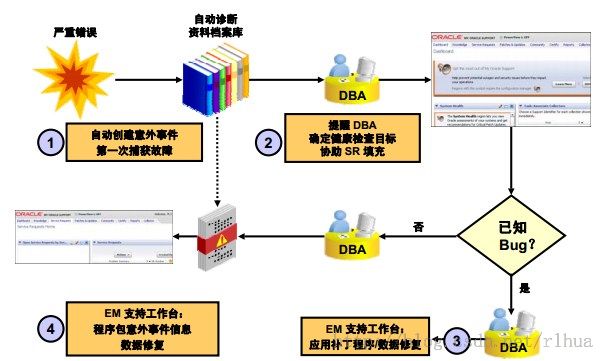
自动诊断工作流
通过一个始终处于打开状态的内存中跟踪工具,数据库组件可以在第一次出现严重错误故障时捕获诊断数据。系统将自动维护一个称为“自动诊断资料档案库”的特殊资料档案库以保存有关严重错误事件的诊断信息。此信息可用于创建要发送到Oracle 支持服务以进行调查的意外事件程序包。
下面是一个典型的诊断会话工作流:
1.意外事件导致Oracle Enterprise Manager (EM) 中出现预警。
2. DBA 可通过EM 的“Alert(预警)”页查看此预警。
3. DBA 可以细化到意外事件和问题的详细资料。
4. DBA 或Oracle 支持服务可以决定或要求将信息打包并通过My Oracle Support 发送到Oracle 支持服务。DBA 可以将文件添加到自动打包的数据中。
- 自动诊断资料档案库

自动诊断资料档案库(ADR)
ADR 是一个基于文件的资料档案库,用于存放数据库诊断数据(如跟踪、意外事件转储和程序包、预警日志、健康状况监视器报表、核心转储等)。它对存储在任何数据库外的多个实例和多种产品使用一个统一的目录结构。因此,在数据库关闭时可用来诊断问题。
从Oracle Database 11gR1 开始,数据库、自动存储管理(ASM)、集群就绪服务(CRS) 和其它Oracle 产品或组件将所有诊断数据都存储在ADR 中。每种产品的每个实例都将诊断数据存储在自己的ADR 主目录下。例如,在具有共享存储和ASM 的Real Application Clusters 环境中,每个数据库实例和每个ASM 实例在ADR 中都有一个主目录。利用ADR 的统一目录结构、用于各种产品和实例的统一诊断数据格式以及一组统一的工具,客户和Oracle 技术支持部门可以在多个实例间关联并分析诊断数据。
ADR 根目录又称为ADR 基目录,其位置由DIAGNOSTIC_DEST初始化参数设置。如果此参数被忽略或留为空值,则数据库在启动时将对DIAGNOSTIC_DEST进行如下设置:
如果设置了环境变量ORACLE_BASE,则将DIAGNOSTIC_DEST设置为$ORACLE_BASE。
如果未设置环境变量ORACLE_BASE,则将DIAGNOSTIC_DEST设置为$ORACLE_HOME/log。
- ADR 命令行工具(ADRCI)
• ADRCI 可以通过操作系统提示符与ADR 进行交互。
• 使用ADRCI 可以查看自动诊断资料档案库中的诊断数据。
$ adrci
ADRCI: Release 11.1.0.5.0 - On Sat Jul 7 08:01:40 2007
Copyright (c) 1982, 2007, Oracle. All rights reserved.
ADR base = "/u01/app/oracle"
ADRCI> show incident
ADR Home = /u01/app/oracle/product/11.1.0/db_1/log/diag/rdbms/orcl/orcl:
**************************************************************************
INCIDENT_ID PROBLEM_KEY CREATE_TIME
----------- ------------------------------------ ------------------------
1681 ORA-600_dbgris01:1,_addr=0xa9876541 17-JAN-07 09.17.44.843125…
1682 ORA-600_dbgris01:12,_addr=0xa9876542 18-JAN-07 09.18.59.434775…
2 incident info records fetched
ADR 命令行工具(ADRCI)
ADRCI 是一种命令行工具,属于数据库故障诊断基础结构的一部分。使用ADRCI 可以:
• 查看自动诊断资料档案库(ADR) 中的诊断数据
• 将意外事件和问题信息打包成zip 文件传输到Oracle 技术支持部门
ADRCI 可在交互模式下使用,也可以在脚本中使用。此外,ADRCI 还可以执行ADRCI 命令脚本,使用的方式与SQL*Plus 执行SQL 脚本和PL/SQL 命令的方式相同。由于未打算保护ADR 中数据的安全,所以没有必要登录到ADRCI。对ADR 目录的操作系统权限是针对ADR 数据的唯一保护机制。
对诊断数据进行打包和其它管理的最简单方法是使用Oracle Enterprise Manager 的支持工作台(帮助解析数据库错误以及ASM 错误)。
ADRCI 提供了一个可代替支持工作台大部分功能的命令行,并添加了一些功能,如列出和查询跟踪文件。本示例中显示了一个ADRCI 会话,该会话列出了存储在ADR中的所有打开的意外事件。
注:有关ADRCI 和支持工作台的详细信息,请参阅《Oracle Database Utilities》指南。
- V$DIAG_INFO视图
sys@TEST0924> SELECT * FROM V$DIAG_INFO;
INST_ID NAME VALUE
---------- ------------------------------ --------------------------------------------------
1 Diag Enabled TRUE
1 ADR Base /u01/app/oracle
1 ADR Home /u01/app/oracle/diag/rdbms/test0924/test0924
1 Diag Trace /u01/app/oracle/diag/rdbms/test0924/test0924/trace
1 Diag Alert /u01/app/oracle/diag/rdbms/test0924/test0924/alert
1 Diag Incident /u01/app/oracle/diag/rdbms/test0924/test0924/incident
1 Diag Cdump /u01/app/oracle/diag/rdbms/test0924/test0924/cdump
1 Health Monitor /u01/app/oracle/diag/rdbms/test0924/test0924/hm
1 Default Trace File /u01/app/oracle/diag/rdbms/test0924/test0924/trace/test0924_ora_20302.trc
1 Active Problem Count 0
1 Active Incident Count 0
11 rows selected.
V$DIAG_INFO视图
V$DIAG_INFO视图列出了所有重要ADR 位置:
• ADR Base:ADR 基目录的路径。
• ADR Home:当前数据库实例的ADR 主目录的路径。
•DiagTrace:文本预警日志和后台/前台进程跟踪文件的位置。
• Diag Alert:XML 版本的预警日志的位置。
• Diag Incident:意外事件日志的写入位置。
• Diag Cdump:诊断核心文件写入到此目录中。
• Health Monitor:运行健康状况监视器时产生的日志的位置。
• Default Trace File:会话的跟踪文件的路径。SQL 跟踪文件写入到此位置。
- 诊断跟踪的位置
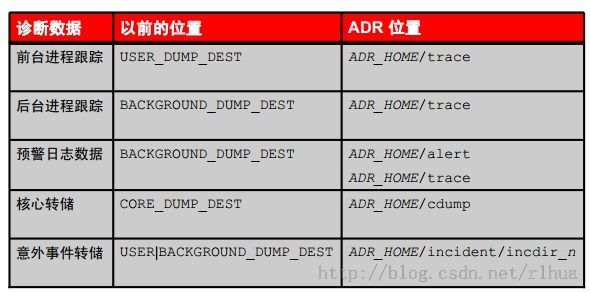
诊断跟踪的位置
上图中的表比较了Oracle Database 10g与Oracle Database 11g中都存在的各类跟踪数据和转储。
在Oracle Database 11g中,前台和后台跟踪文件的存储位置没有什么区别。这两种类型的文件都会放入ADR_HOME/trace目录中。
所有非意外事件跟踪都存储在trace子目录中。以前的版本会将严重错误信息转储到相应的进程跟踪文件而不是意外事件转储,这就是新旧版本之间的主要区别。从Oracle Database 11g开始,意外事件转储存放到独立于普通进程跟踪文件的文件中。
跟踪和转储之间的主要区别在于,跟踪是较为连续的输出(如打开SQL 跟踪时),而转储是为了响应事件(如意外事件)而进行的一次性输出。另外,核心是特定于端口的二进制内存转储。
注:在上图中,ADR_HOME表示路径/u01/app/oracle/diag/rdbms/orcl/orcl
(假定实例名称为orcl)。但是,不存在名为ADR_HOME的正式环境变量。
- 健康装款监视器:概览
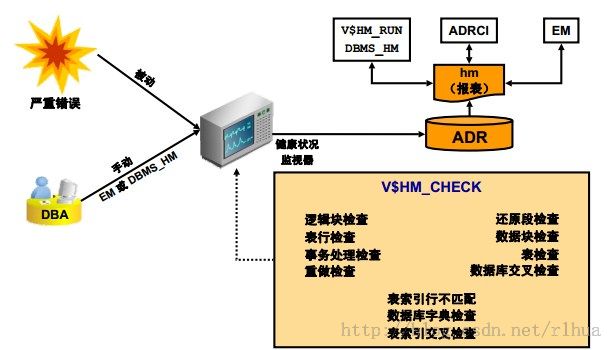
健康装款监视器
Oracle DB 包含一个称为健康状况监视器的框架,用于对数据库的各个组件运行诊断检查。
健康状况监视器可以检查数据库的各个组件(包括文件、内存、事务处理完整性、元数据和进程使用情况)。这些检查将生成查找结果报表以及解决问题的建议。故障诊断基础结构可以在严重错误发生后自动运行健康状况监视器检查;另外,DBA 可以使用DBMS_HM PL/SQL程序包或Oracle Enterprise Manager 界面手动运行健康状况监视器健康检查。
有关健康状况监视器可运行的所有可能检查的完整说明,请参考V$HM_CHECK。这些健康检查分为两个类别:
• DB 联机:可以在数据库处于打开状态(即处于OPEN模式)时运行这些检查。
• DB 脱机:除在数据库处于打开状态时可运行这些检查以外,还可在实例可供使用但数据库本身处于关闭状态(即处于NOMOUNT模式)时运行。
运行检查器后,将生成一份报表。此报表包含有关检查器调查结果的信息,包括优先级(低、高或严重),调查及其结果的说明,以及有关执行的基本统计信息。健康状况监视器可生成XML 格式的报表并将其存储在ADR 中。可使用V$HM_RUN、DBMS_HM、ADRCI或Oracle Enterprise Manager 查看这些报表。
- 手动运行健康检查:PL/SQL 示例
SQL> set long 100000
SQL> select
dbms_hm.get_run_report('mycheck') from dual;
DBMS_HM.GET_RUN_REPORT('mycheck')
--------------------------------------------------------------------------------
<?xml version="1.0" encoding="US-ASCII"?>
<HM-REPORT REPORT_ID="mycheck"><TITLE>HM Report: mycheck</TITLE>
<RUN_INFO>
<CHECK_NAME>Database Dictionary Check</CHECK_NAME>
<RUN_ID>21</RUN_ID><RUN_NAME>mycheck</RUN_NAME>
<RUN_MODE>MANUAL</RUN_MODE><RUN_STATUS>COMPLETED</RUN_STATUS> …
</RUN_INFO>
<RUN_PARAMETERS><RUN_PARAMETER>TABLE_NAME=tab$</RUN_PARAMETER> … </RUN_PARAMETERS>
<RUN-FINDINGS><FINDING>
<FINDING_NAME>Dictionary Inconsistency</FINDING_NAME><FINDING_ID>22</FINDING_ID>
<FINDING_TYPE>FAILURE</FINDING_TYPE><FINDING_STATUS>OPEN</FINDING_STATUS>
<FINDING_PRIORITY>CRITICAL</FINDING_PRIORITY> …
<FINDING_CREATION_TIME>…</FINDING_CREATION_TIME>
<FINDING_MESSAGE>…invalid column number 7 on Object tab$ Failed</FINDING_MESSAGE>
<FINDING_MESSAGE>Damaged … Object SH.JFVTEST is referenced</FINDING_MESSAGE> …
SQL> exec dbms_hm.run_check('Database Dictionary Check',
'mycheck',0,'TABLE_NAME=tab$');
手动运行健康检查:PL/SQL 示例
可以使用
DBMS_HM.RUN_CHECK过程运行健康检查。要调用RUN_CHECK,请提供检查的名称(可在V$HM_CHECK中找到)、运行名称(就是稍后用于检索报表的标签)和控制其执行的一组相应输入参数。可使用V$HM_CHECK_PARAM查看这些参数。
在示例中,需要对TAB$表运行数据库字典检查(假定有一个重要的核心字典对象)。你将此运行命名为MYCHECK,而且不希望为此检查设置任何超时。
执行时,你将执行DBMS_HM.GET_RUN_REPORT函数获取从V$HM_RUN、
V$HM_FINDING和V$HM_RECOMMENDATION中提取的报表。输出明确地显示了在TAB$中发现了严重错误。此表包含一个列数无效的表的条目。此外,报表还提供TAB$中损坏的表的名称。
调用GET_RUN_REPORT函数时,会在ADR 的HM目录中生成XML 报表文件。在示例中,该文件称为HMREPORT_mycheck.hm。
- 使用ADRCI 实用程序查看HM 报表
adrci>>show hm_run
…
----------------------------------------------------------
RUN_ID 11081
RUN_NAME HM_RUN_11081
CHECK_NAME Database Cross Check
NAME_ID 2
MODE 2
START_TIME 2007-04-13 03:20:31.161396 -07:00
RESUME_TIME
END_TIME 2007-04-13 03:20:37.903984 -07:00
MODIFIED_TIME 2007-04-17 01:16:37.106344 -07:00
TIMEOUT 0
FLAGS 0
STATUS 5
SRC_INCIDENT_ID 0
NUM_INCIDENTS 0
ERR_NUMBER 0
REPORT_FILE
…
adrci>>create report hm_run HM_RUN_11081
Adrci>>show report hm_run HM_RUN_11081
…
使用ADRCI 实用程序查看HM 报表
可以使用ADRCI 实用程序创建和查看健康状况监视器检查器报表。要执行该操作,请确保操作系统环境变量(如ORACLE_HOME)设置正确,然后在操作系统命令提示符下输入以下命令:adrci。
该实用程序会启动,并显示示例所示的提示符。可以选择更改当前的ADR 主目录。
使用SHOW HOMES命令列出所有ADR 主目录,然后使用SET HOMEPATH命令更改当前的ADR 主目录。
然后,可以输入SHOW HM_RUN命令列出ADR 资料档案库中注册的且在V$HM_RUN中可以找到的所有检查器运行。找到要为其创建报表的检查器运行,使用相应RUN_NAME字段记下检查器运行名称。如果此检查器运行的报表已存在,则REPORT_FILE字段中将包含一个文件名。如果不存在,可以使用CREATE REPORT HM_RUN命令生成报表,如幻灯片中所示。要查看报表,请使用SHOW REPORT HM_RUN命令。