实现Django的全文检索功能(二):集成haytack
转自:http://blog.csdn.net/wenxuansoft/article/details/8170714
官方网站:
http://django-haystack.readthedocs.org/en/v2.0.0/tutorial.html
http://django-haystack.readthedocs.org/en/v2.0.0/
上篇我们已经学会了使用Whoosh进行中文全文检索的基本方法,这样基本上你就可以在Django自己去建立索引、更新索引并进行搜索了。
在Django中,我们一般是将文章之类的数据放在数据库model里面,如下面这样的models:
- class Blog(models.Model):
- Title=models.CharField(u'标题',max_length=200,blank=True)
- Content=models.TextField(u'内容',blank=True)
- def __unicode__(self):
- return self.Title
- class Meta:
- verbose_name=u"博客"
我们需要让用户可以对博客内容Content字段的内容进行全文搜索,当然你可以自己使用Whoosh去写自己的代码了。
不过,现在已经了一个专门针对Django的搜索app,那就是本文的主角:Django-haystack。
Django-haystack是一个第三方的app,专门用来为Django增加全文检索功能,让你可以方便地对model里面的内容进行索引,搜索,简化你的工作。
并且Django-haystack设计为支持whoosh,solr,Xapian,Elasticsearc四种全文检索引擎后端,属于一种全文检索的框架,这意味着如果你不想使用本文
介绍的whoosh,那你随时可以将之更换成Xapian等其他搜索引擎,而不用更改代码。
正如Django一样,Django-haystack的使用也非常简单。
首先安装Django-haystack,直接使用pip install django-haystack,不过,我建议上官方网站去下载最新的2.0,pip安装的是1.x的版本。
以上述Blog为例
1、我们在app目录下建立一个search_indexes.py,代码如下:
- from models import Blog
- from haystack import indexes
- class BlogIndex(indexes.SearchIndex, indexes.Indexable):
- text = indexes.CharField(document=True, use_template=True)
- def get_model(self):
- return Blog
- def index_queryset(self):
- """Used when the entire index for model is updated."""
- return self.get_model().objects.all() #确定在建立索引时有些记录被索引,这里我们简单地返回所有记录
2、在模板目录templates/indexes/<appname>/blog_text.txt,内容如下:
- <h2>{{ object.Title }}</h2>
- <p>{{ object.Content}}</p>
这个模板的作用是让text字段包含的内容,在后面的模板中可能会有用。
3、在settings.py里面配置:
- HAYSTACK_CONNECTIONS = {
- 'default': {
- 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
- 'PATH': os.path.join(PROJECT_PATH, 'whoosh_index'),
- },
- }
4、在模板目录templates/下建立search.html,内容如下:
- <form method="get" action="">
- <table>
- {{ form.as_table }}
- <tr>
- <td> </td>
- <td>
- <input type="submit" value="Search">
- </td>
- </tr>
- </table>
- {% if query %}
- <h3>结果</h3>
- {% for result in page.object_list %}
- <p>
- <a href="{{ result.object.get_absolute_url }}">{{ result.object.Title }}</a><br/>
- {% highlight result.object.Description with query css_class "keyword" %}
- </p>
- {% empty %}
- <p>没有结果发现.</p>
- {% endfor %}
- {% if page.has_previous or page.has_next %}
- <div>
- {% if page.has_previous %}<a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« Previous{% if page.has_previous %}</a>{% endif %}
- |
- {% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}Next »{% if page.has_next %}</a>{% endif %}
- </div>
- {% endif %}
- {% else %}
- {# Show some example queries to run, maybe query syntax, something else? #}
- {% endif %}
- </form>
5、在urls.py里面加入一行:
- url(r'^search/', include('haystack.urls')),
6、最后,在命令行了运行manage.py rebuild_index,创建索引。
好了,基本的配置就是这样了,如果不满意你可以啃官方文档,可以做更加复杂的控制。
然后运行,就可以看到:
输入关键字“中央”...........(你要事先填充一些数据到blog里面)
傻了,怎么没结果呢??
哦,想想我们在上一篇说的中文检索的文章里说的,是的,同样的默认whoosh是不支持中文的,必须进行一定的处理。
很简单,将我们在上一篇文谈到的内容建立一个ChineseAnalyzer.py,并且保存到haystack的安装文件夹\Lib\site-packages\haystack\backends里面。
代码如下:
- import jieba
- from whoosh.analysis import RegexAnalyzer
- from whoosh.analysis import Tokenizer,Token
- class ChineseTokenizer(Tokenizer):
- def __call__(self, value, positions=False, chars=False,
- keeporiginal=False, removestops=True,
- start_pos=0, start_char=0, mode='', **kwargs):
- #assert isinstance(value, text_type), "%r is not unicode" % value
- t = Token(positions, chars, removestops=removestops, mode=mode,
- **kwargs)
- seglist=jieba.cut(value,cut_all=True)
- for w in seglist:
- t.original = t.text = w
- t.boost = 1.0
- if positions:
- t.pos=start_pos+value.find(w)
- if chars:
- t.startchar=start_char+value.find(w)
- t.endchar=start_char+value.find(w)+len(w)
- yield t
- def ChineseAnalyzer():
- return ChineseTokenizer()
然后将\Lib\site-packages\haystack\backends里面的whoosh_backend.py复制为whoosh_cn_backend.py,
是的,我们必须写一个whoosh的后端,不过呢,完全没必要重新写,只要稍稍改几个小地方就行。
打开whoosh_cn_backend.py进行修改。如下:
- #在whoosh_cn_backend.py里面
- .........
- from ChineseAnalyzer import ChineseAnalyzer
- .............
- #然后找到build_schema函数处,这是一个构建分词模式的
- #找到
- schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=StemmingAnalyzer(), field_boost=field_class.boost)
- schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(), field_boost=field_class.boost)
保存,OVER.
在settings.py里面配置:
- HAYSTACK_CONNECTIONS = {
- 'default': {
- 'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
- 'PATH': os.path.join(PROJECT_PATH, 'whoosh_index'),
- },
- }
在我本地测试:
修改之后重建索引才行。
最后的运行效果如下:
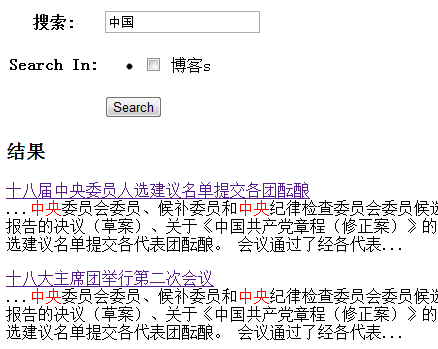
到这里基本上就可以收工了!
不过呢,为了让大家要中文分词更加有概念,我再以上篇提到的使用正则表达式进行分词的做一下试验。
我们将上面的代码改为:
- schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=RegexAnalyzer(ur"([\u4e00-\u9fa5])|(\w+(\.?\w+)*)"), field_boost=field_class.boost)
我们使用了RegexAnalyzer正则表达式分词方式,其实这根本就不是分词,只是识别中文而已。
再来看看搜索的效果:

大家可以看到,搜索中央时,第三条命中项里面并没有中央,但是还是出现在结果中,为什么呢?
对,有些朋友可能猜中了。
该条记录数据里面没有“中央”,不过里面有“中”,也有“央”,因为没有做中文分词处理,所以他们也一样会
被搜索出来。很显然,中文分词处理是必须的,否则可能会出现大量的无效结果。
最后,通过Whoosh+Haystack可以非常容易为Django增加全文搜索功能,并且全部python代码,安装配置简便,
易于集成,推荐大家使用。