Solr 5.x集成中文分词word,mmseg4j
-
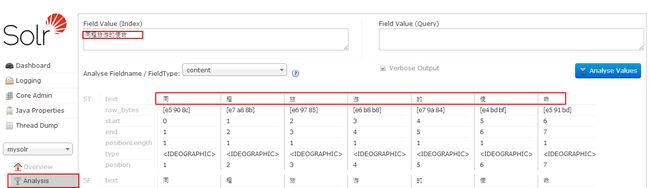
使用标准分词器,如图:
-
使用word分词器
- 下载word-1.3.jar,注意solr的版本和word分词的版本
- 将文件word-1.3.jar拷贝至文件夹C:\workspace\Tomcat7.0\webapps\solr\WEB-INF\lib\下
- 修改如下文件C:\workspace\solr_home\solr\mysolr\conf\schema.xml
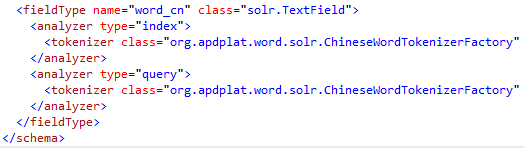
在schema节点下添加如下节点:
<fieldType name="word_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory"/>
</analyzer>
</fieldType>
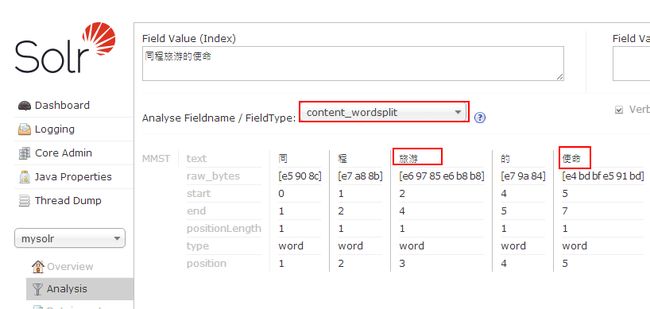
如图:
-
添加分词字段
<field name="content_wordsplit" type="word_cn" indexed="true" stored="true" multiValued="true"/>
- 重启tomcat
-
验证分词
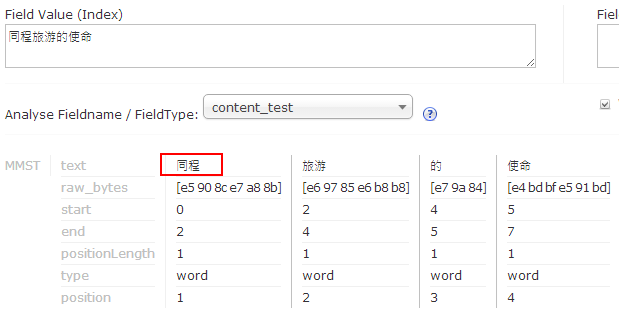
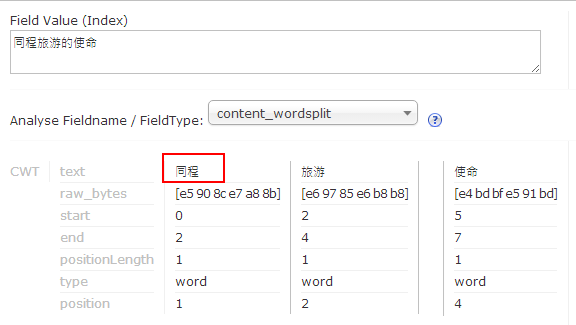
- 发现同程被分词分开了,需要将"同程"添加到词库中
-
编辑C:\workspace\solr_home\solr\mysolr\conf\schema.xml文件,修改如下:
<fieldType name="word_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory" conf="C:/workspace/solr_home/solr/mysolr/conf/word.local.conf"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apdplat.word.solr.ChineseWordTokenizerFactory" conf="C:/workspace/solr_home/solr/mysolr/conf/word.local.conf"/>
</analyzer>
</fieldType>
- 在文件夹C:\workspace\solr_home\solr\mysolr\conf\下新建文件word.local.conf
- 从github中复制word.conf的配置内容,复制dic.txt,stopwords.txt
-
修改word.local.conf文件
dic.path=classpath:dic.txt,classpath:custom_dic,C:/workspace/solr_home/solr/mysolr/conf/word_dic.txt
stopwords.path=classpath:stopwords.txt,classpath:custom_stopwords_dic,C:/workspace/solr_home/solr/mysolr/conf/word_stopwords.txt
修改后的word.local.conf全部内容如下:
#是否启用自动检测功能,如:用户自定义词典、停用词词典
auto.detect=true
#词典机制实现类,词首字索引式前缀树
#dic.class=org.apdplat.word.dictionary.impl.DictionaryTrie
#前缀树词首字索引分配空间大小,如过小则会导致碰撞增加,减小查询性能
dictionary.trie.index.size=24000
#双数组前缀树,速度稍快一些,内存占用稍少一些
#但功能有限,不支持动态增减单个词条,也不支持批量增减词条
#只支持先clear()后addAll()的动态改变词典方式
dic.class=org.apdplat.word.dictionary.impl.DoubleArrayDictionaryTrie
#双数组前缀树预先分配空间大小,如不够则逐渐递增10%
double.array.dictionary.trie.size=2600000
#词典,多个词典之间逗号分隔开
#如:dic.path=classpath:dic.txt,classpath:custom_dic,d:/dic_more.txt,d:/DIC,D:/DIC2
#自动检测词库变化,包含类路径下的文件和文件夹、非类路径下的绝对路径和相对路径
#HTTP资源:dic.path=http://localhost:8080/word_web/resources/dic.txt
dic.path=classpath:dic.txt,classpath:custom_dic,C:/workspace/solr_home/solr/mysolr/conf/word_dic.txt
#是否利用多核提升分词速度
parallel.seg=true
#词性标注数据:part.of.speech.dic.path=http://localhost:8080/word_web/resources/part_of_speech_dic.txt
part.of.speech.dic.path=classpath:part_of_speech_dic.txt
#词性说明数据:part.of.speech.des.path=http://localhost:8080/word_web/resources/part_of_speech_des.txt
part.of.speech.des.path=classpath:part_of_speech_des.txt
#二元模型路径
#HTTP资源:bigram.path=http://localhost:8080/word_web/resources/bigram.txt
bigram.path=classpath:bigram.txt
bigram.double.array.trie.size=5300000
#三元模型路径
#HTTP资源:trigram.path=http://localhost:8080/word_web/resources/trigram.txt
trigram.path=classpath:trigram.txt
trigram.double.array.trie.size=9800000
#是否启用ngram模型,以及启用哪个模型
#可选值有:no(不启用)、bigram(二元模型)、trigram(三元模型)
#如不启用ngram模型
#则双向最大匹配算法、双向最大最小匹配算法退化为:逆向最大匹配算法
#则双向最小匹配算法退化为:逆向最小匹配算法
ngram=bigram
#停用词词典,多个词典之间逗号分隔开
#如:stopwords.path=classpath:stopwords.txt,classpath:custom_stopwords_dic,d:/stopwords_more.txt
#自动检测词库变化,包含类路径下的文件和文件夹、非类路径下的绝对路径和相对路径
#HTTP资源:stopwords.path=http://localhost:8080/word_web/resources/stopwords.txt
stopwords.path=classpath:stopwords.txt,classpath:custom_stopwords_dic,C:/workspace/solr_home/solr/mysolr/conf/word_stopwords.txt
#用于分割词的标点符号,目的是为了加速分词,只能为单字符
#HTTP资源:punctuation.path=http://localhost:8080/word_web/resources/punctuation.txt
punctuation.path=classpath:punctuation.txt
#分词时截取的字符串的最大长度
intercept.length=16
#百家姓,用于人名识别
#HTTP资源:surname.path=http://localhost:8080/word_web/resources/surname.txt
surname.path=classpath:surname.txt
#数量词
#HTTP资源:quantifier.path=http://localhost:8080/word_web/resources/quantifier.txt
quantifier.path=classpath:quantifier.txt
#是否启用人名自动识别功能
person.name.recognize=true
#是否保留空白字符
keep.whitespace=false
#是否保留标点符号,标点符号的定义见文件:punctuation.txt
keep.punctuation=false
#将最多多少个词合并成一个
word.refine.combine.max.length=3
#对分词结果进行微调的配置文件
word.refine.path=classpath:word_refine.txt
#同义词词典
word.synonym.path=classpath:word_synonym.txt
#反义词词典
word.antonym.path=classpath:word_antonym.txt
#lucene、solr、elasticsearch、luke等插件是否启用标注
tagging.pinyin.full=false
tagging.pinyin.acronym=false
tagging.synonym=false
tagging.antonym=false
#是否启用识别工具,来识别文本(英文单词、数字、时间等)
recognition.tool.enabled=true
#如果你想知道word分词器的词典中究竟加载了哪些词
#可在配置项dic.dump.path中指定一个文件路径
#word分词器在加载词典的时候,顺便会把词典的内容写到指定的文件路径
#可指定相对路径或绝对路径
#如:
#dic.dump.path=dic.dump.txt
#dic.dump.path=dic.dump.txt
#dic.dump.path=/Users/ysc/dic.dump.txt
dic.dump.path=
#redis服务,用于实时检测HTTP资源变更
#redis主机
redis.host=localhost
#redis端口
redis.port=6379
- 修改文件C:/workspace/solr_home/solr/mysolr/conf/word_dic.txt,添加字库:同程
- 重启tomcat
-
验证分词结果,如图:
-
使用mmseg4j分词器
- 下载mmseg4j,如:mmseg4j-core-1.10.1-SNAPSHOT.jar,mmseg4j-solr-2.3.1-SNAPSHOT.jar,字典文件夹:data/
- 将mmseg4j-core-1.10.1-SNAPSHOT.jar,mmseg4j-solr-2.3.1-SNAPSHOT.jar拷贝至文件夹C:\workspace\Tomcat7.0\webapps\solr\WEB-INF\lib\下
- 修改如下文件C:\workspace\solr_home\solr\mysolr\conf\schema.xml
在schema节点下添加如下节点:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word"/>
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple"/>
</analyzer>
</fieldtype>
-
添加分词字段
<field name="content_test" type="textMaxWord" indexed="true" stored="true" multiValued="true"/>
- 重启tomcat
-
验证分词
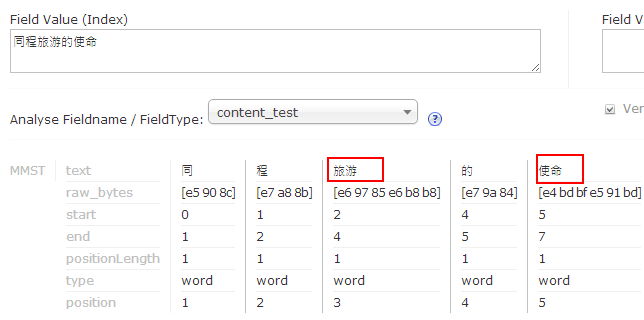
- 添加字典,修改如下文件C:\workspace\solr_home\solr\mysolr\conf\schema.xml
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="data/dic/"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="data/dic/"/>
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="data/dic/" />
</analyzer>
</fieldtype>
-
将自带的字典拷贝到C:\workspace\solr_home\solr\mysolr\data\dic\文件夹下,如图:

- 修改words.dic,添加"同程"关键字
- 重启tomcat
-
验证分词