Chrome高性能网络
Google Chrome的历史和指导原则
性能的方方面面
一个现代浏览器,像操作系统一样是一个平台,Chrome浏览器也不例外。Google Chrome出现之前,所有的浏览器都是巨大的单进程的应用。所有打开页面共享相同的地址空间,竞争访问相同的资源。任意一个页面、或者浏览器的bug,都会影响到整体的体验。
以此相反,Chrome采用多进程模型,这种模型为每个标签页(tab)提供了进程和内存的隔离,以及一个严格安全的沙箱(security sandbox)。在一个越来越多核的世界,隔离进程与保护每个打开标签以避免受到其它行为不端页面的影响的能力,使得Chrome在竞争中表现了卓越的性能。实际上,大多数其它的浏览器已经跟进了Chrome的做法,有的正在移植到类似的架构上。
在一个进程中,一个web应用主要需要执行三个任务:获取资源、页面排版与渲染、和运行JavaScript。渲染和脚本步骤在运行过程中是在单线程上交替执行的 – 不可能在DOM上执行并发修改操作。部分原因是JavaScript本身是一门单线程的语言。因此,优化渲染和脚本的执行显得极为重要。
对于渲染,Chrome使用的引擎是Blink,这是一个快速、开源、兼容标准的排版引擎。对于JavaScript,Chrome使用自己开发的、进行了深度优化的V8引擎。然而,如果网络不畅,无论是优化的V8 JavaScript执行,还是Blink的解析和渲染流水线,作用其实都很有限。巧妇难为无米之炊,数据没来都得等着。
浏览器对每一个网络资源的获取顺序、优先级、延迟的优化能力对整体用户体验的影响最为巨大。你也许察觉不到, Chrome的网络模块每天都在进步,逐步降低每个资源的加载成本:向DNS lookups学习,记住页面拓扑结构,预先连接可能的目标网址,等等。从外部来看,就是一个简单的资源加载机制,但在内部,这是一个为了优化网页性能和呈现最好的用户体验,经过精心设计并且也是个引人入胜的案例研究。
让我们深入下去。
关于Web应用
在我们讨论具体的与网络交互优化策略之前,我们先来看看“什么是现代web应用?”,这有助于我们理解我们正面临的问题的趋势和现状。换句话说,一个现代的web页面,或者应用看起来像什么?
HTTP Archive 项目一直在追踪网页构建,它能够帮助我们回答上述问题。HTTP Archive定期爬行最流行的那些网站,以记录和聚合分析每个网站所用资源的数量、类型、头信息和其它元信息。下面是2013年1月的统计数据,这些数据可能出乎你的预料。由300,000个最流行的网站得来的数据表明,每一个页面平均:
- 1280 KB 大小
- 由88个资源组成
- 连接到15台以上不同的主机(15+ distinct hosts)
对HTTP Archive的数据应用基本的数学分析得出:每个资源平均为15KB左右,这意味着浏览器内的网络传输大部分是短暂和突发性的。这和TCP被的优化方向(针对大量的流式下载)不一致。下面让我们抽丝剥茧考察浏览器的网络请求。
一个Resource Request的一生
给定一个主机名和资源路径,Chrome首先会检查看是否可以重用现有连接 -- sockets根据
{scheme, host, port}分为不同的池。如果你配置了一个代理,或者指定了一个代理自动配置 - proxy auto-config (PAC)脚本,Chrome就会检查与合适代理的连接。PAC脚本允许基于URL使用不同的代理,或者其它规则。每一个代理对应一个自己的连接池。最后,如果上述情况都不存在,请求就会以解析主机名为IP地址开始 -- 众所周知的DNS查询。幸运的话,该主机名可能已经在缓存中了,在这种情况下,响应就是一个快速的系统调用。否则,在继续其它事情之前必须先发送一个DNS查询。DNS查询的时间变化很大,主要由以下因素决定:你的ISP、网站的知名度、主机名在中间缓存的可能性、以及该域的权威服务器的响应时间。换句话说,存在很多的变量,一个DNS查询达到数百秒的情况并不罕见。
我们已经有了IP地址,Chrome现在可以打开同目标主机的TCP连接了,也就是说我们必须执行“三次握手”:SYN > SYN-ACK > ACK。这一过程给每一个新连接增加了一个完整的round-trip延迟,没有例外。取决于客户端与服务器的距离,和所选择的路径,这一过程可能产生几十到数百,甚至上千毫秒的延迟。而到现在,我们还一个有效字节都没收到。
TCP握手完成之后,如果我们正在连接一个安全的主机(HTTPS),那就还要经过SSL握手。这又会增加多达两个RTT的延迟。如果缓存有SSL,我们可以避免一个额外的RTT。
最后,Chrome终于可以发送HTTP请求了(图1.1中的requestStart)。服务器收到请求后,处理并返回数据给客户端。这又带来至少一个网络round-trip,再加上服务器处理时间。至此,请求完成了。如果响应是一个HTTP重定向,我们可能要再重复整个过程。
你已经计算过所有的延迟了吗?为了说明问题,我们以典型网络上最坏情况为例:没有本地缓存,接下来是一个较快的DNS查询(50ms),TCP握手,SSL协商,和一个较快的(100ms)服务器响应,加上一个80ms的RTT(穿越美国大陆的平均RTT):
- 50 ms for DNS
- 80 ms for TCP handshake (one RTT)
- 160 ms for SSL handshake (two RTTs)
- 40 ms for request to server
- 100 ms for server processing
- 40 ms for response from the server
- 如果服务器响应超过了初始TCP窗口大小,将会引入一到多个额外的RTT延迟
- 如果我们需要获取缺失的证书或者执行一个在线证书状态检测(两种情况都需要一个全新的TCP连接),SSL延迟将会更长,可能会增加数百甚至上千毫秒
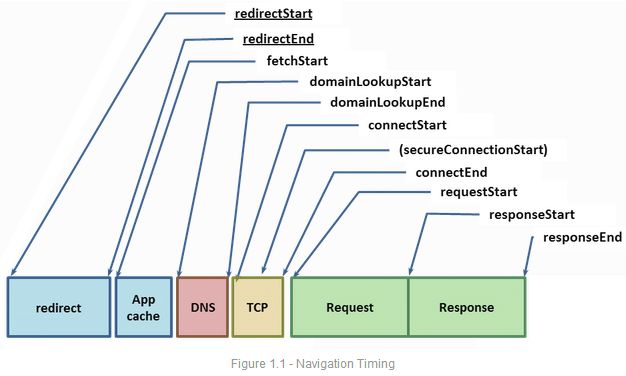
给定web上某个资源的URL,浏览器首先检查本地和应用缓存。假如之前已经读取到该资源并且它有合适的缓存头 -appropriate cache headers(Expires, Cache-Control, etc.),那我们就可以用缓存完成请求 -- 最快的请求就是不用请求。否则,如果资源已经过期,或者之前没有见过,我们就得重新验证该资源,一个耗时的网络请求就不可避免的发生了。

何谓足够快?

现在,你知道了,理想的延迟时间是不超过250ms,然而,从上面的例子可以看到,DNS查询、TCP和SSL握手、和请求传播时间加起来就有370ms,超过了理想延迟的50%,而且我们还没把服务器处理时间考虑进去。
对于大部分用户,甚至web开发者,DNS、TCP、SSL是透明的,这些东西都是有相应协议层协商的,很少有人进行深入考虑。然而, 这些步骤的每一步都会严重影响到整体的用户体验,每一个额外的请求都可能导致延迟增加数十至数百ms。这就是为什么Chrome的网络模块远远不只是一个socket处理器。
现在我们已经标识出了问题,让我深入到实现的内部
鸟瞰Google Chrome
多进程架构
默认情况下,桌面版的Chrome使用process-per-site模型,不同的站点相互隔离,访问同一个站点的实例被放在同一个进程。这里,为了容易说明问题,我们考虑最简单的情况:一个tab一个进程。从网络性能的角度来看,差别不大,只是process-per-tab模型比较好理解。
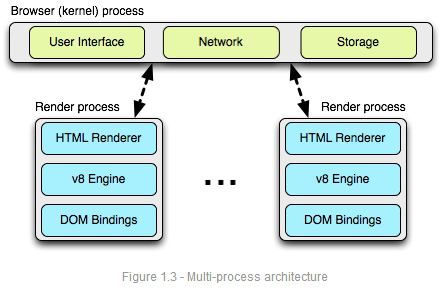
每一个渲染引进程都运行在一个沙盒里,沙盒对用户电脑,包括网络只有有限的访问权限。每一个渲染进程通过同主浏览器进程通信来获得对这些资源的访问,这种做法加强了每个渲染进程的安全性。
进程间通信和多进程资源加载
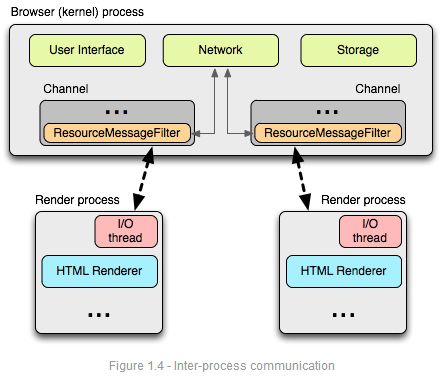
单例接口允许浏览器控制每一个渲染器对网络的访问,使资源共享高效、一致。一些例子如下:
- Socket pool and connection limits: 浏览器可以限制每一个profile至多打开256个socket,每一个proxy至多打开32个socket,每一组{scheme, host, port}至多打开6个。注意针对一组{host, port}至多只能打开6个HTTP和6个HTTPS连接。
- Socket reuse: 在socket池中保留了持久的TCP连接,以便一段时间后重用连接来服务器请求。这可以避免建立新连接附带的DNS,TCP,SSL握手延迟。
- Socket late-binding: 请求只有在socket准备好发送应用请求时才与TCP连接相关联,这种做法带来了更好的请求优先级、更好的吞吐量、一个通用的TCP预连接机制、以及一系列其它的优化。
- Consistent session state: 所有的渲染进程可以共享身份认证,cookies, 缓存数据
- Global resource and network optimizations: 浏览器能够基于所有的渲染进程和待执行的请求来做决策。例如:给予由前台tab发起的请求更高的优先级
- Predictive optimizations: 通过观察所有的网络流量,Chrome能够创建和改善预测模型以获得更好的性能
跨平台资源获取
当然,所有网络模块的代码都是开源的,你可以在
src/net subdirectory找到。我们不准备详细说明每一个部分,从代码布局你就可以大概知道每一部分的功能和结构。下表列举了其中的一小部分:| Component | Description |
|---|---|
net/android |
绑定到Android运行时 |
net/base |
公共网络辅助模块, 例如主机解析, cookies, 网络变更检查, and SSL certificate management |
net/cookies |
实现HTTP cookies存储, 管理和获取 |
net/disk_cache |
实现web资源在Disk and memory上的缓存 |
net/dns |
实现异步DNS解析器 |
net/http |
HTTP 协议的实现 |
net/proxy |
代理 (SOCKS and HTTP) 配置, 解析, 脚本抓取, etc. |
net/socket |
TCP sockets, SSL流, socket pools的跨平台实现 |
net/spdy |
实现SPDY协议 |
net/url_request |
URLRequest, URLRequestContext, and URLRequestJob implementations |
net/websockets |
WebSockets 协议的实现 |
移动平台上的架构和性能
- 桌面用户使用鼠标来操作, 可以有重叠窗口, 很大的屏幕, 基本不受电源限制, 通常还有稳定的网络连接, 可以访问大得多的存储池和内存
- 移动用户使用触摸和手势操作, 小的多的屏幕, 受到电池和电源限制, 网络连接慢又昂贵, 本地存储和内存也很有限.
Chrome预测器的推测优化
Predictor 对象的帮助下完成的。该对象由浏览器内核进程创建,它的唯一任务是观察网络模式,进行学习并预测用户将来最可能的操作。下面举一些例子,看看由Predictor 处理的一些信号:
- 用户把鼠标悬停在一个超链接上,这是个很好的指示,表示很可能有一个即将到来的导航事件,Chrome可以通过发送一个推测的DNS查询、启动TCP握手,来帮助加速。当用户点击时,这一过程平均会有200ms,这是我们完成DNS和TCP步骤的好机会,借此我们可以为该导航事件消除数百毫秒的额外延迟。
- 地址栏中键入会触发高可能性建议, 类似的,这也可能发起一个DNS查询,TCP预连接,甚至可能对未显示的tab页进行预渲染
- 我们每一个人都会有一些经常访问的网站. Chrome 能够学习这些网站上的子资源,并且根据推测进行预解析,也可能预取这些资源,从而加速浏览体验。
| Technique | Description |
|---|---|
| DNS pre-resolve | 提前解析主机名,避免DNS延迟 |
| TCP pre-connect | 提前连接目标服务器,避免TCP握手延迟 |
| Resource prefetching | 提前预取网页上的关键资源,加速网页渲染 |
| Page prerendering | 提前读取整个网页包括它的所有资源,使用户可以即时浏览 |
Predictor 对象在用户和网络产生的活动上创建了许多过滤器
- IPC channel filter监控渲染进程产生的信号
每一个请求有一个ConnectInterceptor对象, 它能够观察流量模式并记录每个请求成功度
ResolutionMotivation
(
url_info.h
):
enum ResolutionMotivation {
MOUSE_OVER_MOTIVATED, // 用户鼠标悬停.
OMNIBOX_MOTIVATED, // 地址栏提示解析.
STARTUP_LIST_MOTIVATED, // 启动列表中的前10资源.
EARLY_LOAD_MOTIVATED, // In some cases we use the prefetcher to warm up
// the connection in advance of issuing the real
// request.
// The following involve predictive prefetching, triggered by a navigation.
// The referring_url_ is also set when these are used.
STATIC_REFERAL_MOTIVATED, // External database suggested this resolution.
LEARNED_REFERAL_MOTIVATED, // Prior navigation taught us this resolution.
SELF_REFERAL_MOTIVATED, // Guess about need for a second connection.
// <snip> ...
};Chrome网络架构小结
- Chrome使用多进程架构,渲染进程与浏览器进程相隔离
- Chrome维护一个资源调度程序的单个实例, 它运行在浏览器内核进程中 , 所有的渲染进程共享该实例
- 网络堆栈是个跨平台的,大部分基于单线程的库。
- 网络堆栈使用非阻塞操作管理所有的网络操作
- 共享网络堆栈带来诸多好处:高效的资源优先级、重用、浏览器能够执行跨进程的全局优化
- 渲染进程通过IPC与资源调度程序通讯
- 资源调度程序通过一个自定义的IPC过滤器来解释资源请求
- 预测器通过解释资源请求并跟踪流量,来学习优化将来的网络请求
- 预测器基于对流量模式的学习,来推测性的安排DNS,TCP,甚至资源请求,为用户实际操作时节约数百毫秒的时间。