再谈pipeline-filter模式
本文结合最近我正在实现的一个基于RabbitMQ的消息总线上所走的弯路来谈谈设计层面上的责任链模式以及架构层面上的pipeline-filter模式。写这篇文章的另一个目的是为了纠正我之前针对pipeline-filter模式写的一篇博文:《pipeline-filter模式变体之尾循环》,如果你想看看我之前为什么要那么做,你可以先看看那篇文章,不过无论看不看都不影响这篇文章的行文。
消息总线需要扩展性
目前这个消息总线实现了produce/consume、request/response、publish/subscribe、broadcast这几种消息通信场景。这些场景中都涉及到消息的处理。
我想实现一种基于plugin的消息处理。它们需要是粒度较细的,并可在各种消息通信模式之间可复用、易于扩展的,并且基于配置文件可以自动将这些不同的plugin串联成一个pipeline。这种模式称之为责任链模式或pipeline-filter模式(如果你区分得严谨,那么可能会将pipeline-filter划归为架构模式,见POSA 卷4),如果你做过java web开发,你总是容易将它跟filter联系起来。没错,filter的这种模式其实就是责任链模式。
两种模式的主流认识
其实通常我们谈责任链跟pipeline-filter,大部分的注意力都集中在“进”的意识上:数据(通常被封装在一个上下文对象中)在调用链上被每个filter依次处理,向前推进。但java web技术里的filter的实现却同时关注了“进与退”:
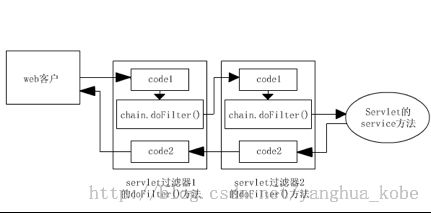
这是多种原因共同作用的结果:
- http有请求也有响应:数据的处理不是单向的,是个闭合的回路
- 它的上下文其实是两个对象:HttpServletRequest、HttpServletResponse,进的时候关注HttpServletRequest对象,退的时候关注HttpServletResponse对象,分工明确,互不干扰
- 实现这种filter-chain的做法通常都是递归调用;而递归调用在方法执行上涉及到入栈跟出栈的过程。临界点就是方法内部对该递归方法的调用(见上面的chain.doFilter。调用之前的代码可看做入栈,会被先调用;调用之后的代码可被看做出栈,会在所有入栈完成后再依次出栈时被调用)。而图中最后的servlet的Service可以看作是该递归的break point,执行完成之后,将会开始退的(处理HttpServletResponse)流程
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
logger.info("[doFilter] enter into CompressionFilter");
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpServletResponse resp = (HttpServletResponse) servletResponse;
String encoding = Strings.nullToEmpty(req.getHeader("Accept-Encoding"));
if (encoding.contains("gzip")) {
CompressionResponseWrapper warppedResp = new CompressionResponseWrapper(resp);
warppedResp.setHeader("Content-Encoding", "gzip");
filterChain.doFilter(req, warppedResp);
GZIPOutputStream gzos = warppedResp.getGZIPOutputStream();
gzos.finish();
} else {
filterChain.doFilter(req, resp);
}
}
消息总线中遇到的问题
改进方案
写在最后
pipeline这个词在表述中一直不是太精确,有人用它表达责任链模式,有人将其代指pipeline&filter。在交流上自然不必太过较真,但我想从这篇文章可以给出一个很好的区分:责任链模式是设计模式,面向程序实现;pipeline&filter是架构模式。而不同点,我想你也看到了。
当时实现这部分代码的时候我正好在看POSA卷四,里面谈及了架构模式pipeline-filter。而我想这就是设计模式跟架构模式的区别:设计模式面向代码实现,而在代码实现中不关注运行代码的服务器的部署拓扑结构;而架构模式是一种抽象级别更高的模式,而且卷四本身就是面向分布式系统的,因此它所谓的filter其实是一个分布式的数据处理组件,这自然是一种纯粹的有进无退的的pipeline。
事实上这种设计到现在已经经历到第三版了。第一版是就是那篇文章中说明的方式,完全是POSA表达的那种;第二版,我有意看了一下java filter的实现,但当时被其两个上下文对象搞糊涂了,认为这是一种特定场景下的实现(有请求,有响应),并且我确实没有正视递归调用的实现起了主要作用。第三版,完全基于责任链的设计模式。
代码见: banyan