Libsvm与Liblinear源码浅析与封装(二)
封装Libsvm与Liblinear
开篇我们基于以下场景:
假设我们已经用libsvm或者是Liblinear训练了一个模型,现在需要读入该模型并基于该模型对一个样本进行预测,返回预测的类标签以及相应的隶属度分数。
从封装的角度我们需要考虑一下几个问题:
- 如何规范输入,使得读入的数据在Libsvm与Liblinear上都可以直接运行
- 系统如何识别读入的模型的类别,并根据模型类别,选择Libsvm或者是Liblinear中合适的函数进行预测
- 如何预测该样本对应的标签以及得分
系统输入
因为我们对单个样本进行预测,所以这里直接定义单个节点的格式即可。对于多个样本,则可以循环调用。
在上一篇文章中,我们看到虽然Libsvm与Liblinear在向量节点的定义上有所差别,但是其中的成员变量还是一致的,因此为了统一,我们只需要重新定义一个新的类。
public class SvmNode {
/** 封装的Libsvm与Liblinear的节点格式**/
private final int index;
private double value;
public SvmNode( final int index, final double value ) {
if (index < 0) throw new IllegalArgumentException("index must be >= 0");
this.index = index;
this.value = value;
}
/**以下Getter和Setter、hashCode、equals函数省略**/
}
模型读入
我们首先来剖析一下Libsvm与Liblinear生成的模型的文件格式

从上述文件中,我们看到两者的模型文件存在很大的差异,因此我们只需要写一个解析函数直接读取模型的格式来判断到底属于那种模型。
最简单的形式就是直接通过第一行来判断,因为其模型的文件都是固定的,所以这种最简单的方式也是很有效的。
/**
* 读入模型文件。通过文件中的格式来判断到底属于Libsvm还是liblinear
* @param model_filename 模型文件保存的路径及名称
*/
public void load_model(String model_filename){
BufferedReader fp;
try {
InputStream in = new FileInputStream(model_filename);
fp = new BufferedReader(new InputStreamReader(in,"UTF-8"));
String line = null;
try {
while((line = fp.readLine())!=null){
String[] arg = whitespace.split(line);
//通过判断文件中每行第一个字符是否包含"svm_type"或者是"solver_type"
//来判断是Libsvm还是Liblinear
if(arg[0].equals("svm_type")){
svm_type = "libsvm";
svmModel = svm.svm_load_model(model_filename);
nr_class = svmModel.nr_class;
linearModel = null;
break;
}
if(arg[0].equals("solver_type")){
svm_type="liblinear";
svmModel = null;
linearModel = Linear.loadModel(new File(model_filename));
nr_class = linearModel.getNrClass();
break;
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (UnsupportedEncodingException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
多分类策略
这里我们研究一下Libsvm与Liblinear的多分类策略,虽然为多分类,但其实也适用于二分类。
对于Libsvm来说,采用为One-against-one的策略,而Liblinear则采用为One-against-rest的策略,关于这两类分类策略的解释,可以看下图:
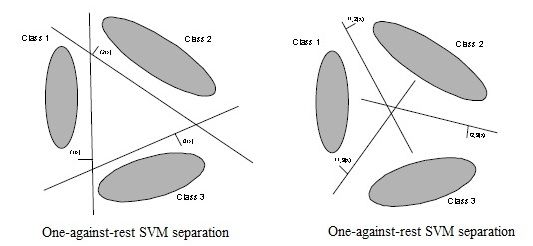
我们接下来通过源代码具体分析一下:
首先来看一下Libsvm的模型训练部分:
/**
* Libsvm的模型训练函数
* @param prob 输入的问题
* @param param 输入的参数
* @return 训练好的模型
*/
public static svm_model svm_train(svm_problem prob, svm_parameter param)
{
/**为了代码的简洁性,此处删除了部分**/
/**
* 此处省略了部分代码:这里的代码主要做:
* 1、统计类别总数,同时记录类别的标号,统计每个类的样本数目
* 2、计算权重C
* 3、初始化nozero数组,便于统计SV
* 4、初始化概率数组
*/
svm_model model = new svm_model();
model.param = param;
// 将属于同一个类别的数据组织起来
svm_group_classes(prob,tmp_nr_class,tmp_label,tmp_start,tmp_count,perm);
//采用one-against-one进行分类
int p = 0;
//定义决策函数数组,将每一个而分类存储起来
decision_function[] f = new decision_function[nr_class*(nr_class-1)/2];
for(i=0;i<nr_class;i++)
for(int j=i+1;j<nr_class;j++)
svm_problem sub_prob = new svm_problem();
//计算第i个类与第j个类的起始位置与数目。
int si = start[i], sj = start[j];
int ci = count[i], cj = count[j];
sub_prob.l = ci+cj;
//将第i个类的标签定义为+1,第j个类的标签定义为-1
for(k=0;k<ci;k++)
{
sub_prob.x[k] = x[si+k];
sub_prob.y[k] = +1;
}
for(k=0;k<cj;k++)
{
sub_prob.x[ci+k] = x[sj+k];
sub_prob.y[ci+k] = -1;
}
//对第i个类与第j个类采用二分类策略,训练模型
f[p] = svm_train_one(sub_prob,param,weighted_C[i],weighted_C[j]);
++p;
}
/**
* 此处省略了部分代码:这里的代码主要做:
* 1、统计一下nozero,如果nozero已经是真,就不变,如果为假,则改为真
* 2、输出模型,主要是填充svm_model
*/
return model;
}
然后再来看一下其模型预测部分:
/**
* Libsvm模型预测部分,预测该样本的类标签以及属于该类的分值。
* 这里采用的方法为投票策略
* @param model 已训练好的Libsvm模型
* @param x 一个待预测的样本向量
* @param dec_values 保存预测结果的向量,其维度为k*(k-1)/2
* @return
*/
public static double svm_predict_values(svm_model model, svm_node[] x, double[] dec_values)
{
//对一些变量进行初始化
int i;
int nr_class = model.nr_class;
int l = model.l;
double[] kvalue = new double[l];
//根据模型中的支持向量以及内核函数计算数值
for(i=0;i<l;i++)
kvalue[i] = Kernel.k_function(x,model.SV[i],model.param);
int[] start = new int[nr_class];
start[0] = 0;
for(i=1;i<nr_class;i++)
start[i] = start[i-1]+model.nSV[i-1];
//初始化vote向量
int[] vote = new int[nr_class];
for(i=0;i<nr_class;i++)
vote[i] = 0;
//依次计算k*(k-1)/2个二分类模型的预测值
int p=0;
for(i=0;i<nr_class;i++)
for(int j=i+1;j<nr_class;j++)
{
double sum = 0;
int si = start[i];
int sj = start[j];
int ci = model.nSV[i];
int cj = model.nSV[j];
//根据决策函数计算每一个二分类对样本预测的分值
int k;
double[] coef1 = model.sv_coef[j-1];
double[] coef2 = model.sv_coef[i];
for(k=0;k<ci;k++)
sum += coef1[si+k] * kvalue[si+k];
for(k=0;k<cj;k++)
sum += coef2[sj+k] * kvalue[sj+k];
sum -= model.rho[p];
//dec_values存储的就是第p个二分类模型对样本的预测值
dec_values[p] = sum;
//根据dec_values 值的正负决定给那个类别投票
if(dec_values[p] > 0)
++vote[i];
else
++vote[j];
p++;
}
//遍历vote向量,找出具有最大投票数的所对应类别即为所预测的类标签。
//而dec_values则存储了k*(k-1)/2个二分类模型的预测值
int vote_max_idx = 0;
for(i=1;i<nr_class;i++)
if(vote[i] > vote[vote_max_idx])
vote_max_idx = i;
return model.label[vote_max_idx];
}
接下来我们分析一下Liblinear的模型训练与模型预测部分
模型训练部分:
/**
* Liblinear模型训练部分
* @param prob 输入的问题
* @param param 输入的参数
* @return 返回训练好的模型
*/public static Model train(Problem prob, Parameter param) {
/**
* 此处省略了部分代码:这里的代码主要做:
* 1、统计类别总数,同时记录类别的标号,统计每个类的样本数目
* 2、将属于相同类的样本分组,连续存放
* 3、计算权重C
* 4、初始化nozero数组,便于统计SV
* 5、初始化概率数组
*/
//此处可以看出需要寻k个模型
for (int i = 0; i < nr_class; i++) {
int si = start[i];
int ei = si + count[i];
//重建子数据集,样本的特征不变,但样本的类别要改为+1/-1
int k = 0;
for (; k < si; k++)
sub_prob.y[k] = -1;
for (; k < ei; k++)
sub_prob.y[k] = +1;
for (; k < sub_prob.l; k++)
sub_prob.y[k] = -1;
//训练子数据集svm_train_one
train_one(sub_prob, param, w, weighted_C[i], param.C);
for (int j = 0; j < n; j++)
model.w[j * nr_class + i] = w[j];
}
/**
* 此处省略了部分代码:这里的代码主要做:
* 1、统计一下nozero,如果nozero已经是真,就不变,如果为假,则改为真
* 2、输出模型,主要是填充svm_model
*/
return model;
}
模型预测部分:
/**
* 模型预测部分,根据训练好的模型对样本进行预测。
* @param model 已训练好的模型
* @param x 样本的向量
* @param dec_values 每个模型预测分值
* @return 预测的类标签
*/
public static int predictValues(Model model, Feature[] x, double[] dec_values) {
//变量的初始化
int n;
if (model.bias >= 0)
n = model.nr_feature + 1;
else
n = model.nr_feature;
double[] w = model.w;
int nr_w;
if (model.nr_class == 2 && model.solverType != SolverType.MCSVM_CS)
nr_w = 1;
else
nr_w = model.nr_class;
for (int i = 0; i < nr_w; i++)
dec_values[i] = 0;
//计算每个模型预测分值
for (Feature lx : x) {
int idx = lx.getIndex();
// the dimension of testing data may exceed that of training
if (idx <= n) {
for (int i = 0; i < nr_w; i++) {
dec_values[i] += w[(idx - 1) * nr_w + i] * lx.getValue();
}
}
}
//根据预测的分值来计算所属的标签,和Libsvm所不同的是:
//这里采用的方式是比较那个模型预测分值大。
if (model.nr_class == 2)
return (dec_values[0] > 0) ? model.label[0] : model.label[1];
else {
int dec_max_idx = 0;
for (int i = 1; i < model.nr_class; i++) {
if (dec_values[i] > dec_values[dec_max_idx]) dec_max_idx = i;
}
return model.label[dec_max_idx];
}
}
模型结果
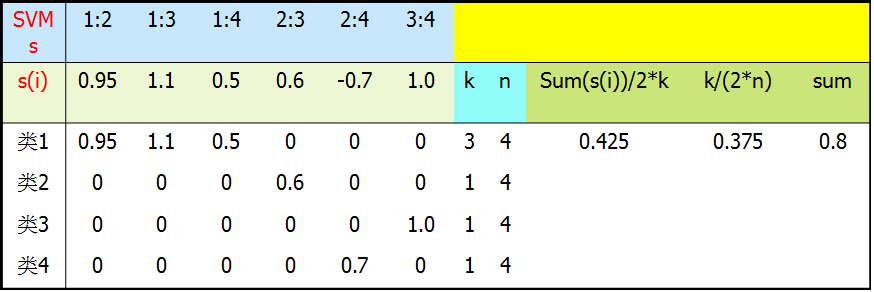
模型会返回两个结果:label和score,其中label即其预测的标签。而score是该样本属于该类的隶属度,分值越大,代表属于该类的置信度越大。具体的计算方式则是根据:

其中k为所有支持判别类得个数,n为所有类别个数,si 为所有支持判别类的分数。这样就相当于把两个软件计算出来的分数进行了统一,而且经过公式的计算,会将分数的映射到[0,1]区间内,这样方便进行阈值控制。
代码为
/**
* 返回具有最大投票数的标签所获得分数的总和
* @param des_values
*/
public double sumPreValue(double[] des_values){
int size=1;
double init_score=0.0;
int k=1;
//对于Libsvm的类型,对其k*(k-1)/2个值进行计算
if (this.svm_type.equals("libsvm")){
int n = 1+(int)Math.sqrt(2.0*des_values.length+1);
size = n-1;
int [] vote = new int[n];
double[] score = new double[n];
int p =0;
for(int i =0;i<n-1;i++){
for(int j =i+1;j<n;j++){
if(des_values[p]>0){
vote[i]+=1;
score[i]+=Math.abs(des_values[p]);
}else{
vote[j]+=1;
score[j]+=Math.abs(des_values[p]);
}
p+=1;
}
}
int max = 0;
for(int i =1;i<n;i++)
if(vote[i]>vote[max])
max = i;
k = vote[max];
init_score = score[max];
}
//对于Liblinear的类型,对其k个值进行计算
if (this.svm_type.equals("liblinear")){
int n =des_values.length;
int max = 0;
for(int i =1;i<n-1;i++){
if(des_values[i]>des_values[max]){
max = i;
}
}
size =1;
k=1;
init_score = des_values[max];
}
return init_score/(2.0*k)+k/(2.0*size) ;
}
以Libsvm为例,说明一下分数的计算
总结
这样我们通过输入一个样本,根据读入的模型,就可以真正的对样本进行预测了。而且通过归一化两者的分值,可以很好的对结果进行阈值控制。更多详细的代码请见 https://code.google.com/p/tmsvm/