二级指针实现单链表的插入、删除及 linux内核源码双向链表之奇技
二级指针实现单链表的插入、删除
今天看了coolshell上关于二级指针删除单链表节点的文章。
文章中Linus 举例:
例如,我见过很多人在删除一个单项链表的时候,维护了一个”prev”表项指针,然后删除当前表项,就像这样:
if (prev)
prev->next = entry->next;
else
list_head = entry->next;
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.
(当我看到这样的代码时,我就会想“这个人不了解指针”。令人难过的是这太常见了。)
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head.
And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”.
(了解指针的人会使用链表头的地址来初始化一个“指向节点指针的指针”。当遍历链表的时候,可以不用任何条件判断(注:指prev
是否为链表头)就能移除某个节点,只要写)
*pp = entry->next
Linus看来,维护了一个”prev”表项指针进行删除,这是不懂指针的人的做法。那么,什么是core low-level coding呢?
那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。
coolshell上这篇 Linus:利用二级指针删除单向链表 文章对二级指针操作单链表删除的精妙之处已经做了说明。
下面,我们来探讨下,为什么 使用二级指针能达到如此的效果??
我们先来个简单的列子:
#include <cstdio>
#include <cstdlib>
void f(int v)
{
v = 1;
}
void f_(int *pv)
{
*pv = 1;
}
int main()
{
int n = 0;
f(n);
printf("%d\n", n);
f_(&n);
printf("%d\n", n);
return 0;
}输出:
0
1
上面是个 简单的例子,即是我们常说的c/c++ 语言的函数 参数传递 一律为 值传递。要达到改变所传递的参数的值,我们只能想法把 存放
这个实际值的内存地址当做参数进行传递,然后我们操作内存地址,通过修改这个地址所指向的值,间接达到修改这个值的效果。如图
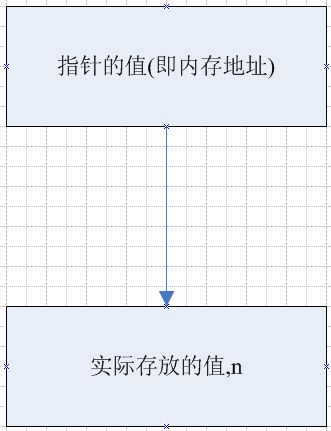
值传递,记住这条基本原理:形参相当于函数中定义的变量,调用函数传递参数的过程相当于定义形参变量并且用实参的值来初始化。
下面来说明下,单链表的操作。
单链表中,链表节点就是一个地址加上别的数据,这个地址指示着下一个节点的位置,只要我们有头节点head这个指针,用来指向第一个
节点。这样我们的链表中,每个节点都有一个指针指着,而且环环相扣。
为什么会想到二重指针操作的写法?因为我们意识到删除操作的本质是指针值的改变,这样用二级指针去操纵指针的值就是很自然的想法了。
说白了:显然二级指针是保存了可能会被修改的变量的地址,这就是head或prev->next。通过二级指针,head或prev->next这两个概念被统
一在一起。来个图吧。
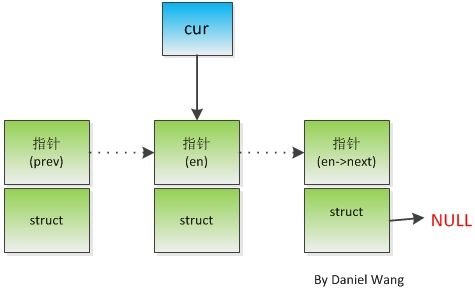
这个图可以结合下面代码中的 void remove_if(Node **pphead, int v) 函数。
对于上面的这个图我们声明了一个二级指针 cur,我们能够发现其实 二级指针是保存了被修改的变量的地址这里为图中的 en 指针,
en指针,好吧其实 en就是某个结构体或类型对象的地址,当这个指针en(在32位系统上其实就是一个4字节的无符号数)满足我们的
条件时 我们只需要 修改这个指针所指向的内存块(即图中的struct),下面的代码中我们是是否这个内存块,但在此之前我们可以利用
en这个指针变量所占的真实内存块(注意指针en的值所在内存其实就是上一个节点prev 结构体的netx所指内存),所以我们现在所要
做的就是改变这个prev节点netx所指内存的存储的值,即*cur 的值(因为cur=&en), 所以在释放en所指内存块前,我们需要把*cur 即
prev->next 的值修改为en->next, 即 *cur=en->next.
我们可以明白了,其实二级指针删除节点的做法把 en和prev这两个概念统一在一起了。
好了,代码如下:
#include <cstdio>
#include <cstdlib>
typedef struct node
{
int data;
struct node *next;
}Node;
int insert(Node **pphead, int v)//插入节点,采用头插法
{
Node *t= (Node*)malloc(sizeof(Node));
if(NULL == t)
return 0;
t->data = v;
t->next = *pphead;// 新头节点的next节点为保存的插入之前的头节点t
*pphead = t;
return 1;
}
void print(Node **pphead)//输出链表所有元素
{
for(Node *cur = *pphead; cur;)
{
printf("%d ", cur->data);
cur = cur->next;
}
}
void remove_if(Node **pphead, int v)//删除节点值为v的所有节点
{
for(Node **cur = pphead; *cur;)
{
Node *en = *cur;
if(en->data == v)
{
// *重要*
*cur = en->next;//用二级指针去操纵指针的值,*cur现在为待删除节点的next节点
free(en);//释放待删除节点,此时存放地址en值的二级指针cur依然存在 且cur地址
//所指内存已经了存储了 删除节点的下一个节点
}
else
{
cur = &en->next;
}
}
}
int main()
{
Node *pfirst=nullptr;//c++11,初始化头节点为空
for(int i=0; i != 5; ++i)
insert(&pfirst, i%2);
print(&pfirst);
printf("\n");
remove_if(&pfirst, 1);
print(&pfirst);
return 0;
}
输出:
0 1 0 1 0
0 0 0
二级指针 操作链表是不是精简了很多,很值得我们去学习、使用。
Linux 内核源码 双向链表 奇技淫巧 (常用)
怎么通过某个struct 结构体中的某一个变量来获取整个结构的变量?
即 如下的struct node 结构体,当我们知道了next变量后 我们怎么获得整个结构体的起始地址从而获得结构体中其它的变量??
typedef struct node
{
int data;
struct node *next;
}Node;
下面这个宏就为你解开答案:
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_struct within the struct. */ #define list_entry(ptr, type, member) / ((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
在 linux源代码中有个头文件为 list.h 中有这个 宏的定义。
下面根据一些参考和自己的理解,说明如下:
我们还是利用 上面的结构体 struct node,现在我们知道struct node *next,怎么去获得这个指针所在结构体变量,
下面我们这样即可,Node *pn = list_entry(&n.next,Node,next); ,把宏展开更明了:
((Node *)((char *)(&n.next) - (unsigned long)(&((Node *)0)->next)))
首先分成两部分(char *)(&n.next) 减去(unsigned long)(&((Node *)0)->next) 然后转换成(Node *) 类型的指针。
关键是(unsigned long)(&((Node *)0)->next) :
其中((Node *)0) ,它是把0 地址转换成Node类型 指针,然后(Node*)0)->next 就是指向next 变量,之后是&((Node *)0)->next
是取这个变量的地址,最后是(unsigned long)(&((Node *)0)->next) 把这个变量的地址值变成一个整数。
呀!原来这个(unsigned long)(&((Node *)0)->next) 的意思就是取next 变量在struct node 结构中的偏移量。
其中(char*)(&n.next)把存储 next的地址转成 char*。最后将 指向next的指针向前移动offset 位置,此时指针移动到结构体 struct node
起始地址,然后转换成(Node *)指针,这是我们就可以轻松操作 Node结构体变量了, 是不是很精秒,不知道是哪位大牛想起来这个方法的!!
我们看到了C强制类型转换的好处,![]() 。
。
下面举个我写的简单例子 帮助理解:
#include <cstdio>
#include <cstdlib>
typedef struct node
{
int data;
struct node *next;
}Node;
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
int main()
{
/* c++11 统一的初始化
Node n{1,nullptr};
Node m{2,nullptr};
*/
Node n = {1, NULL};
Node m = {2, NULL};
n.next = &m;
// 通过 n.next变量找到n这个Node变量
Node *pn = list_entry(&n.next,Node,next);
// 输出 n,m,pn地址
printf("&n:%0x\n&m:%0x\npn:%0x\n", &n, &m, pn);
//可以输出n.next变量所指结构体的值
printf("pn->data:%d\n", pn->data);
return 0;
}
输出为:
&n:22ff14&m:22ff0c
pn:22ff14
pn->data:1
do...while(0)的妙用
inux内核和其他一些开源的代码中,经常会遇到这样的代码:
do{
...
}while(0)
while(0)没有循环呀?有什么意义?为什么要这么用呢?( 参考)
实际上,do{...}while(0)的作用远大于美化你的代码。
总结起来有如下好处:
1、避免使用goto:
有些函数中,在函数return之前我们经常会进行一些收尾的工作,比如free/delete掉一块函数开始malloc的内存,
常规的做法是,失败后goto到err处理。goto名声比较坏了!用do while(0)试试;
...
资源分配...
// 执行并进行错误处理
do{
dosomething...;
if(!err)
break;
dosomething...;
if(err)
break;
}while(0);
// 释放资源
delete p;
p = NULL;
将函数主体使用do()while(0)包含起来,使用break来代替goto,后续的处理工作在while之后,就能够达到同样的效果。
2.用于宏定义中用作代码块
举例来说,假设你需要定义这样一个宏:
#define DO_() f1(); f2();
使用时
if(flag)
DO_();
else
...
…展开宏,就知道问题了 报错了吧.
这个宏的想要调用DO_()时,函数f1()和f2()都会被调用.
因为宏在预处理的时候会直接被展开,上面的代码会成这个样子的:
if(flag)
f1();
f2();
出现了问题, 因为无论flag是否为真,f2()都会被执行,导致程序出错。
我们在写代码的时候都习惯在语句右面加上分号,如果在宏中使用{},代码里就相当于这样写了:“{...};”,展开后就是这个样子:
if(flag)
{
f1();
f2();
};
else
...
因为else没有匹配的if, 这样不会编译通过的。
所以do{}while(0)可以兼容各种编程习惯,保证宏展开后不会有错误了。同时,我们也要养成良好的习惯 每次使用if else都加上{},
任何宏展开都不会有副作用了。
3、避免空宏引起的warning
内核中由于不同架构的限制,有很多空的宏,在编译的时候,空宏会给出warning,为了避免这样的warning,就可以使用do{}while(0)来定义空宏:
#define EMPTYMICRO do{}while(0)
4、定义一个单独的函数块来实现复杂的操作:
当你实现的模块比较复杂,变量比较多,而你又不愿意增加一个新函数的时候,使用do{}while(0);,将你的代码写在里面,里面可以定义变量而不用考虑变量
名会同函数之前或者之后的重复。
更多的linux内核链表相关源码学习参见,点我。