网络爬虫:采用“负载均衡”策略来优化网络爬虫
前言:
这里说的负载均衡并非大家熟悉的网络中的负载均衡。
只是这里我使用了和负载均衡同样的一种思维来优化程序罢了,其实就是压力分摊。
问题描述:
对于上一篇《分离生产者和消费者来优化爬虫程序》博客中遗留的问题:线程阻塞。
当我们的程序运行到一定时间之后,会出现线程池中的500条线程不够用的情况,进而程序长期处于等待的状态。
压力测试实验:
本实验基于之前的爬虫程序,线程池中的线程最大为320条。下面是对在主线程中以不同时间间隔执行程序的测试结果:
sleep 300ms

sleep 500ms
sleep 1000ms
内存使用状态图:
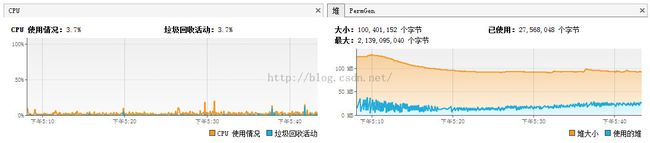
代码优化逻辑:
1.python代码优化
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from time import clock, sleep
import threading
from list_web_parser import ListWebParser
import get_html_response as geth
def visited_html(html):
myp = ListWebParser()
get_html = geth.get_html_response(html)
myp.feed(get_html)
link_list = myp.getLinkList()
myp.close()
for item in link_list:
if item[0] and item[1]:
print item[0], '$#$', item[1]
global thread_done_flag
thread_done_flag = True
def count_down():
start = clock()
while True:
sleep(1)
end = clock()
if int(end - start) >= 2:
print 'TIME OUT'
global thread_done_flag
thread_done_flag = True
break
thread_done_flag = False
def start_work(url):
thread1 = threading.Thread(target=visited_html, args=(url,))
thread2 = threading.Thread(target=count_down)
thread1.setDaemon(True)
thread2.setDaemon(True)
thread1.start()
thread2.start()
while not thread_done_flag:
''
if __name__ == "__main__":
if not sys.argv or len(sys.argv) < 2:
print 'You leak some arg.'
start_work(sys.argv[1]) 这段代码做了一件事,主线程跟随第一个子线程结束而结束。
目的是为了让程序在1秒钟之内结束运行,而超过1秒的html解析,我们将抛弃。我想这是合理的。因为我们不可能让Python一直占用我们的线程资源,这样很快线程就会出现阻塞。而且,随着我们解析HTML的线程数的增加。CPU的消耗也很快,这样我们的计算机就会出现卡顿的情况。
2.Java代码优化
public void visittingUrl(String startAddress) {
// url 合法性判断
if (startAddress == null) {
return;
}
// 种子url 入库
SpiderBLL.insertEntry2DB(startAddress);
// 解析种子url
PythonUtils.fillAddressQueueByPython(mUnVisitedQueue, startAddress, 0);
if (mUnVisitedQueue.isQueueEmpty()) {
System.out.println("Your address cannot get more address.");
return;
}
boolean breakFlag = false;
int index = 0;
startThread();
while (!breakFlag) {
WebInfoModel model = mUnVisitedQueue.poll();
if (model == null) {
System.out.println("------ 此URL为NULL ------");
continue;
}
// 判断此网站是否已经访问过
if (DBBLL.isWebInfoModelExist(model)) {
// 如果已经被访问,进入下一次循环
System.out.println("已存在此网站(" + model.getName() + ")");
continue;
}
poolQueueFull(mThreadPool);
System.out.println("LEVEL: [" + model.getLevel() + "] NAME: " + model.getName());
mThreadPool.execute(new ParserRunner(mResultSet, model, index++, mResultMap));
SystemBLL.cleanSystem(index);
// 对已访问的address进行入库
DBBLL.insert(model);
model = null;
SystemBLL.sleep(300);
}
mThreadPool.shutdown();
} Java代码的代码主要体现在,我们每次调用Python进行解析HTML时,都会sleep 300毫秒。这样我们CPU的压力就转移到时间上了。而这300毫秒其实对整体程序的影响不大,算是优点大于缺点吧。
关于上一篇:
1.覆盖equals时总要覆盖hashCode
我们需要覆盖WebInfoModel的equals和hashCode方法,目的是我们把这个对象保存到HashSet中,需要保证它的唯一性。那么我们就必须自己来写一些唯一性的策略:重写equals方法。而重写equals时,必须要重写hashCode方法。关于这一点,大家可以参看笔者的另一篇博客《Effective Java:对于所有对象都通用的方法》
@Override
public int hashCode() {
return (name.hashCode() + address.hashCode() + level);
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof WebInfoModel)) {
return false;
}
if (((WebInfoModel)obj).getName() == name && ((WebInfoModel)obj).getAddress() == address && ((WebInfoModel)obj).getLevel() == level) {
return true;
}
return false;
}
遗留的问题:
1.python无故停止运行
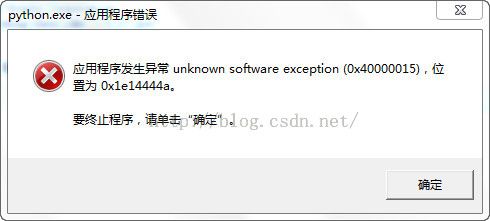
下一步的目标:
1.解决python程序停止运行的Bug
2.分布式
(终于,终于可以开始利用分布式来优化我的蜘蛛程序了。想想还有一点小激动呢 ^_^)