菜鸟学习Hadoop系列一----安装Hadoop
一前期准备
安装linux系统。这地方就不具体介绍了。网络上的博文很多。我一直使用的是Fedora 12(32bit).我的实验采用的系统就是这个了。以下的操作也都是基于该系统的。
下载jdk,这个在官网(http://www.oracle.com/technetwork/java/javase/downloads/index.html)上很容易就可以找到。目前提供的是1.7.0.9版本。
下载hadoop,在官网(http://hadoop.apache.org)上下载了目前的稳定版本。Hadoop-1.0.0版本。
二安装JDK
了解在安装hadoop之前是需要安装sun公司的jdk,所以,第一步就是安装jdk了。在网络搜索了好多博客。许多都是说下载个jdk-xxx.tar.gz的压缩文件解压,然后修改环境变量就可以了。可惜,本人是真的菜鸟,按照博文的说法来做了一遍,然后使用java –version命令验证下,结果出现的是:OpenJDK-xxx,看到这个心都凉了,好想联系这些博客的主人啊。完全按照他们的指导来的啊,可是结果却截然不同啊,这不科学。
接着搜索,发现了一篇博文,里面和上面的差不多,但是在配置那里使用了update-alternatives命令。我隐约觉得好像知道点什么了。然后继续搜索update-alternatives的作用,发现了该命令的作用。见我转载的博文。
下面是我在Fedora12,root用户下完成的配置。
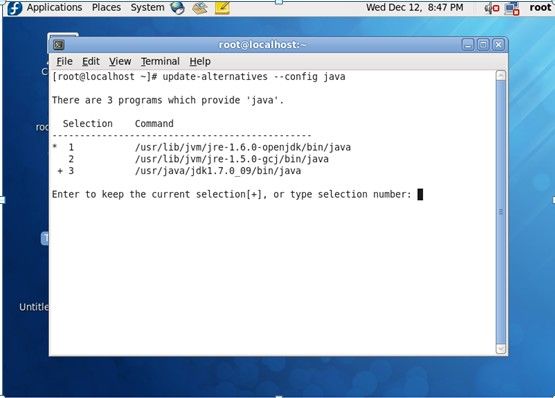
1、 采用的是jdk.xxx.rpm包安装的方式进行安装的。Rpm–ivh jdk-xxx.rpm,该操作完成后,有许多error信息,主要说未发现某些文件。但是,这些错误信息是可以忽略的。
2、 使用update-alternatives命令来配置默认的jdk。命令为:
Update-alternatives –config java
选择sun公司的jdk作为默认的jdk。
3、 这时候就可以用java –version来测试是否配置完成了。由于我使用的是rpm包的安装方式,我发现系统里没有JAVA_HOME等环境变量。这些环境变量留在安装hadoop的时候再配置。
4、 如果是采用虚拟机安装的话,我建议在此处设置一个snapshot。因为在后续的操作中,有点问题可能导致虚拟机无法登陆,需要rollback。
三 安装hadoop
从官网上下载的是hadoop.1.0.0.tar.gz压缩文件。根据官网的指导意见来安装。安装方式可以分为3中。单机模式(Standalone Operation),伪分布模式(Pseudo-Distributed Operation),集群模式(Fully-DistributedOperation)。当然,首先将这个压缩包解压到某个目录下吧。检测自己的电脑里是否安装了ssh。一般fedora好像是自带了这个。首先是查看自己的系统里有没有JAVA_HOME这些环境变量。如果没有的话在此就需要进行配置了。在/etc/profile文件的末尾添加上这些配置,然后再重新启动或者使用命令source来重新加载环境变量。
#set javaenvironment
exportJAVA_HOME=/usr/java/jdk1.7.0_09
exportJRE_HOME=/usr/java/jdk1.7.0_09/jre
exportHADOOP_HOME=/usr/hadoop
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOEM/lib/dt.jar:$JRE_HOME/lib:$HADOOP_HOME/lib:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
如果使用命令echo或者env能够查看到这些个环境变量就表示配置生效了。
1、 单机模式
单机模式主要用于调试,所以没什么配置信息需要配置。
进入hadoop的目录下,建立Input文件夹。操作命令如下。
mkdirinput
$ cpconf/*.xml input
$bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
$ cat output/*
一般情况下,得到的结果会是:1 dfsadmin
本人是纯菜鸟,暂时还不知道这个结果表示了什么意思。待我有点深入后再回来解答这个问题。不过可以大胆的猜测下,调用了example.jar这个文件来执行了map-reduce操作之类的咯。
2、 伪分布模式
伪分布模式仍然是在单机上运行的,但是其将hadoop运行在多个java进程中。配置Hadoop安装目录/conf/core-site.xml文件
1、在configuration节点中增加以下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/hadoop-${user.name}</value>
</property>
2、配置Hadoop安装目录/conf/hdfs-site.xml文件
在configuration节点中增加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3、配置Hadoop安装目录/conf/mapred-site.xml文件
在configuration节点中增加以下内容:
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
4、配置Hadoop安装目录/conf/mapred-site.xml文件
在configuration节点中增加以下内容:
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
5、设置无密码ssh登陆。
首先检查系统的ssh需要密码否。命令为:sshlocalhost。如果需要密码的话就需要配置了。命令如下:
$ ssh-keygen -tdsa -P '' -f ~/.ssh/id_dsa
$ cat~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果你没有使用root的话,那么就需要切换权限了。这样设置完成后,就不需要使用密码了。
6、运行hadoop
首先需要格式化一个namenode。使用命令:hadoopnamenode -format
启动:start-all.sh
停止:stop-all.sh
创建目录:hadoopdfs -mkdir 目录名称
浏览目录:hadoopdfs -ls 目录名称
复制文件到目录:hadoopdfs -copyFromLocal 文件名称目录名称
hadoop dfs 查询帮助