android surfaceflinger研究----SurfaceFlinger loop
上一篇文章介绍了整个Surface机制(我是这么称呼的,主要是Surface的建立,Surface的显示存储的管理),同时我们也介绍过了整个显示系统,那么这篇文章就介绍一下SurfaceFlinger 这个核心服务层的机制。
从代码中我们可以看出SurfaceFlinger 是一个thread,运行在system_server进程中,并且其threadLoop()方法的返回值为true,因此它是一个循环的loop。这样保证了SurfaceFlinger业务的循环周期性。
首先,先来个综述,下图是我总结的一个SurfaceFlinger结构的概括图:

1. SurfaceFlinger的同步
SurfaceFlinger 并不是时时刻刻都在执行业务中,当WMS请求SurfaceFlinger创建Surface,或者WMS对Surface进行属性设置时,我们希望此时的SurfaceFlinger并不进行显示操作,以保证对Surface的线程保护,因此SurfaceFlinger 的loop中实现了同步机制。
waitForEvent();
主要的同步情况有如下几种,当然也有其他一些要求SurfaceFlinger同步的情况,不够对于研究SurfaceFlinger就不太重要了
1. 创建Surface同步
假如当前只有一个Client,比如WMS请求SufaceFlinger创建一个Surface,那么此时应该保持SurfaceFlinger loop处在block状态,因为这个过程涉及到对一些成员变量的处理,为了保证同步而需要hold住整个loop。
2. 设置Surface属性或SurfaceFlinger属性同步
创建完Surface之后,WMS会请求SurfaceFlinger对其Layer进行属性设置或者对SurfaceFlinger的属性进行设置,如上面概括图中SurfaceComposerClient中的函数接口。
3. Surface绘制同步
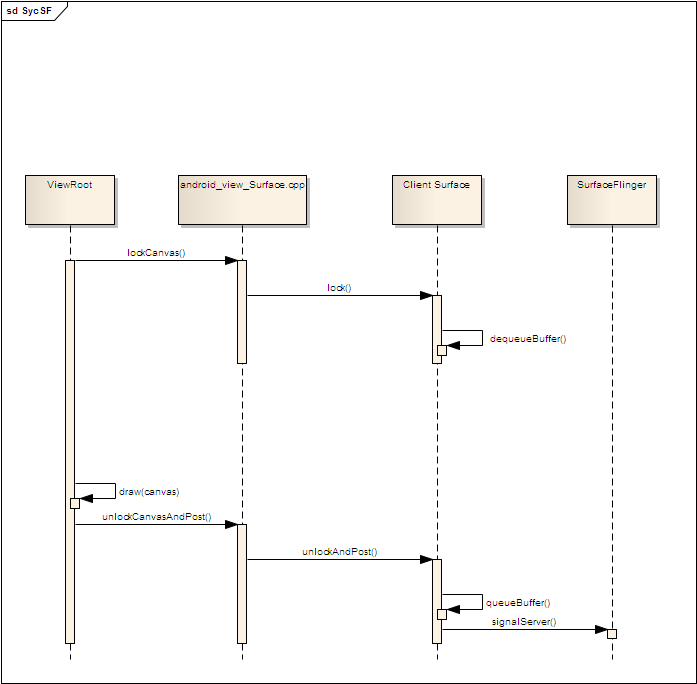
当ViewRoot对Surface进行绘制时,同样需要将SurfaceFlinger hold住,当整个窗口绘制完成之后,再向SurfaceFlinger发送signal信号。如下面时序图所示。
4. freeze/unfreeze同步
当每个Activity启动的时候,AMS都会请求WMS freeze整个屏幕,当Activity启动之后,再unfreeze整个屏幕,我猜测这么做的目的是为了保证在Activity以及Activity的窗口在创建过程中,对Activity窗口的Surface进行的线程保护,以免出现屏幕的闪烁等用户体验较差的现象。
2. Layer存储
在SurfaceFlinger中,Layer是怎么样存储的呢?所有的Layer,不论是那个Client创建的Layer,均保存在一个名为layersSortedByZ的变量中,也就是说WMS请求创建的Surface的Layer和其他Client请求创建的Layer都保存在layersSortedByZ中,但是layersSortedByZ保存过程中则遵守一定的规则。下面代码中的do_compare揭示了这个规则。
@SurfaceFlinger.h
class LayerVector : public SortedVector< sp<LayerBase> > {
public:
LayerVector() { }
LayerVector(const LayerVector& rhs) : SortedVector< sp<LayerBase> >(rhs) { }
virtual int do_compare(const void* lhs, const void* rhs) const {
const sp<LayerBase>& l(*reinterpret_cast<const sp<LayerBase>*>(lhs));
const sp<LayerBase>& r(*reinterpret_cast<const sp<LayerBase>*>(rhs));
// sort layers by Z order
uint32_t lz = l->currentState().z;
uint32_t rz = r->currentState().z;
// then by sequence, so we get a stable ordering
return (lz != rz) ? (lz - rz) : (l->sequence - r->sequence);
}
}; 每次向
layersSortedByZ中添加新的Layer,都会做一次排序,按照规则将其放在合适的位置。
1. 首先,按照Layer的Z-order值来排序,Z-order值小的,放在layersSortedByZ低索引值位置;
2. 其次,如果两个Layer Z-order值相同,sequence值小的,放在layersSortedByZ低索引值位置;
Z-order值如何确定?
WMS根据不同的Window Type来确定Z-order值,Z-order = LAYER*TYPE_LAYER_MULTIPLIER + TYPE_LAYER_OFFSET。
根据下面代码中的不同的Window Type的LAYER值,可以确定Z-order值,例如TYPE_APPLICATION窗口,其
Z-order = 2*10000+1000 = 21000。
@PhoneWindowManager.java
// wallpaper is at the bottom, though the window manager may move it.
static final int WALLPAPER_LAYER = 2;
static final int APPLICATION_LAYER = 2;
static final int PHONE_LAYER = 3;
static final int SEARCH_BAR_LAYER = 4;
static final int STATUS_BAR_PANEL_LAYER = 5;
static final int SYSTEM_DIALOG_LAYER = 6;
// toasts and the plugged-in battery thing
static final int TOAST_LAYER = 7;
static final int STATUS_BAR_LAYER = 8;
// SIM errors and unlock. Not sure if this really should be in a high layer.
static final int PRIORITY_PHONE_LAYER = 9;
// like the ANR / app crashed dialogs
static final int SYSTEM_ALERT_LAYER = 10;
// system-level error dialogs
static final int SYSTEM_ERROR_LAYER = 11;
// on-screen keyboards and other such input method user interfaces go here.
static final int INPUT_METHOD_LAYER = 12;
// on-screen keyboards and other such input method user interfaces go here.
static final int INPUT_METHOD_DIALOG_LAYER = 13;
// the keyguard; nothing on top of these can take focus, since they are
// responsible for power management when displayed.
static final int KEYGUARD_LAYER = 14;
static final int KEYGUARD_DIALOG_LAYER = 15;
// things in here CAN NOT take focus, but are shown on top of everything else.
static final int SYSTEM_OVERLAY_LAYER = 16;
static final int SECURE_SYSTEM_OVERLAY_LAYER = 17;
sequence值如何确定?
sequence值是根据Layer的创建的顺序来维护这个序列值,下面代码中的LayerBase的构造函数中的sequence值,每创建一个Layer,sSequence加一赋值给sequence。
@LayerBase.cpp
int32_t LayerBase::sSequence = 1;
LayerBase::LayerBase(SurfaceFlinger* flinger, DisplayID display)
: dpy(display), contentDirty(false),
sequence(uint32_t(android_atomic_inc(&sSequence))),
mFlinger(flinger),
mNeedsFiltering(false),
mOrientation(0),
mLeft(0), mTop(0),
mTransactionFlags(0),
mPremultipliedAlpha(true), mName("unnamed"), mDebug(false),
mInvalidate(0)
{
const DisplayHardware& hw(flinger->graphicPlane(0).displayHardware());
mFlags = hw.getFlags();
mBufferCrop.makeInvalid();
mBufferTransform = 0;
}
3. 属性更新
这一节的所描述的实现都在函数handleTransactionLocked()中。
从上面概括图中可以看出,WMS可以对SurfaceFlinger进行属性设置,也可以对当前的Surface对应的Layer进行属性设置,因此handleTransactionLocked()函数就是对SurfaceFlinger属性和设置了新属性的Layer的属性更新。
enum {
eTransactionNeeded = 0x01,
eTraversalNeeded = 0x02
};
SurfaceFlinger根据这个枚举值来确定handleTransactionLocked()需要更新SurfaceFlinger属性还是layer属性。
如果SurfaceFlinger属性被设置了新内容,则SurfaceFlinger会记录标志eTransactionNeeded;如果layer属性被设置了新内容,那么
SurfaceFlinger会记录标志eTraversalNeeded。handleTransactionLocked()通过记录的标志来执行各自的属性得更新。‘
这里提到的属性的更新,主要是看SurfaceFlinger或者laye新设置的属性与旧的属性相比,哪些属性做了修改,然后
记录下来,在接下来的SurfaceFlinger loop中使用新的属性来显示图形。
类SurfaceFlinger 和Layer中各自定义了两个属性的变量,其中mCurrentState为新设置属性,mDrawingState为显示图形时用到的属性,一般为旧属性。不过类SurfaceFlinger 和Layer分别定义了不同的State类。
State mCurrentState;
State mDrawingState;
4. 图形缓存
这一部分的的实现在函数handlePageFlip()中。
有这么一种可能,当前显示到显示设备上的layer不止一个,而且layer是按照Z-Order的顺序来叠加到OpenGL的surface上的,那么这就需要layer的Z-Order值和坐标来确定每个layer能够被显示的区域。
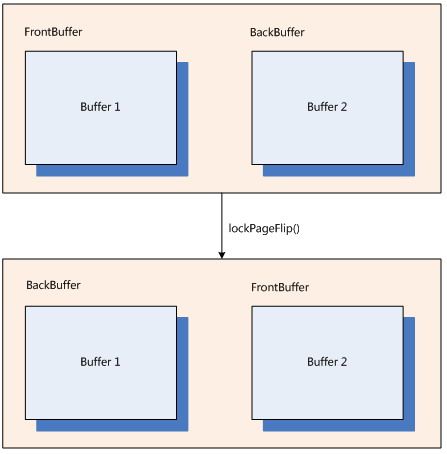
4.1 page flip
前面一篇文章中介绍过,每个surface均有2个buffer供使用,一个作为FronteBuffer供SurfaceFlinger去显示,另外一个作为BackBuffer供ViewRoot去绘制窗口。因此在显示各个layer之前,我们需要做一个page flip过程,将当前的已经绘制了应用窗口的BackBuffer选择为FrontBuffer,用于显示;将之前的已经显示完成的FrontBuffer在重置为BackBuffer供ViewRoot去绘制。
而实现这个page flip的过程很简单
lockPageFlip()@Layer.cpp
ssize_t buf = lcblk->retireAndLock();
SharedBufferServer::RetireUpdate::operator()@SharedBufferStack.cpp
head = (head + 1) % numBuffers;
4.2 纹理初始化
为每个Buffer的纹理进行初始化,为当前的纹理创建一个EGLImageKHR,将当前的Buffer最为该EGLImageKHR的源。这样OpenGL就可以进行纹理映射。
lockPageFlip()@Layer.cpp
/* a buffer was posted, so we need to call reloadTexture(), which
* will update our internal data structures (eg: EGLImageKHR or
* texture names). we need to do this even if mPostedDirtyRegion is
* empty -- it's orthogonal to the fact that a new buffer was posted,
* for instance, a degenerate case could be that the user did an empty
* update but repainted the buffer with appropriate content (after a
* resize for instance).
*/
reloadTexture( mPostedDirtyRegion );
4.3 计算显示区域
通过layer的叠加,我们可以计算出总的显示区域以及每个layer需要显示的区域,它的实现在computeVisibleRegions()函数中。这个函数主要计算了layer叠加后的总的显示区域,以及每个layer需要显示的区域。整个的计算过程比较简单,只是需要注意不透明区域的处理,computeVisibleRegions()需要计算出一个不透明区域,通过这个不透明区域验证WMS提供给layer的区域是否正确。即下面代码中的mWormholeRegion计算,mWormholeRegion为屏幕区域减去不透明区域,正常情况mWormholeRegion应该为空,即不透明区域范围应该为屏幕区域,如果不透明区域小雨屏幕区域,那么说明当前的应用程序出现了设置的错误。今天有个网友就出现了这个问题。
handlePageFlip()
const Region screenRegion(hw.bounds());
if (visibleRegions) {
Region opaqueRegion;
computeVisibleRegions(currentLayers, mDirtyRegion, opaqueRegion);
/*
* rebuild the visible layer list
*/
mVisibleLayersSortedByZ.clear();
const LayerVector& currentLayers(mDrawingState.layersSortedByZ);
size_t count = currentLayers.size();
mVisibleLayersSortedByZ.setCapacity(count);
for (size_t i=0 ; i<count ; i++) {
if (!currentLayers[i]->visibleRegionScreen.isEmpty())
mVisibleLayersSortedByZ.add(currentLayers[i]);
}
mWormholeRegion = screenRegion.subtract(opaqueRegion);
mVisibleRegionsDirty = false;
}
在computeVisibleRegions()叠加计算总的显示范围,layer的计算顺序从上到下的过程计算的,也就是先计算Z-Order值较大的,显示在最上层的layer开始往下计算。这么做的好处就是能够很好的计算出不透明区域的范围。
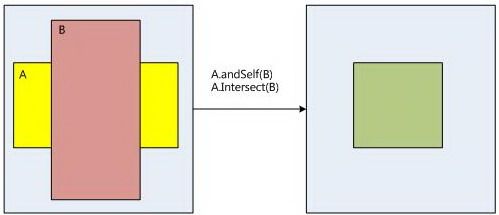
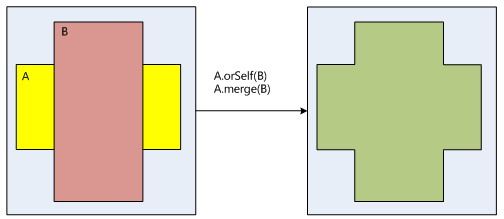
在SurfaceFlinger的区域相互之间的操作处理如下:
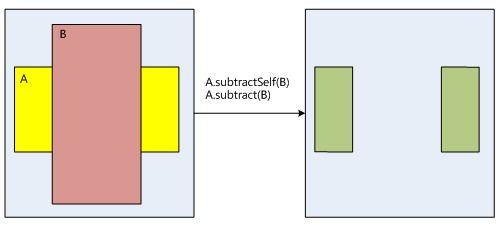
4.4 图形缓存
前面选择了FrontBuffer、初始化了纹理、计算了layer的显示区域,那么下一步就该将Buffer内容进行图形处理并保存到OpenGL缓存中。
调用每个layer的draw函数来进行这个操作。如下面代码所示。具体的图形处理过程很复杂,完全交给OpenGL去处理,这里我们就不去关心了。我们只需要知道最终经过图形处理的内容会被缓存到OpenGL的缓存区中。
void SurfaceFlinger::composeSurfaces(const Region& dirty)
{
if (UNLIKELY(!mWormholeRegion.isEmpty())) {
// should never happen unless the window manager has a bug
// draw something...
drawWormhole();
}
const Vector< sp<LayerBase> >& layers(mVisibleLayersSortedByZ);
const size_t count = layers.size();
for (size_t i=0 ; i<count ; ++i) {
const sp<LayerBase>& layer(layers[i]);
const Region clip(dirty.intersect(layer->visibleRegionScreen));
if (!clip.isEmpty()) {
layer->draw(clip);
}
}
}
从前面的显示系统中,介绍过,Surface的缓存Buffer就是FramebufferNativeWindow中定义的2个Buffer,如果/dev/fb0读取设备信息,如果设备支持page flip,那么Surface的缓存Buffer即从/dev/fb0设备中申请;如果不支持,我们则需要从/dev/pmem中申请,同时/dev/fb0还会提供一个Buffer以便图形最终的显示。
/dev/fb0不支持page flip模式

/dev/fb0支持page flip模式
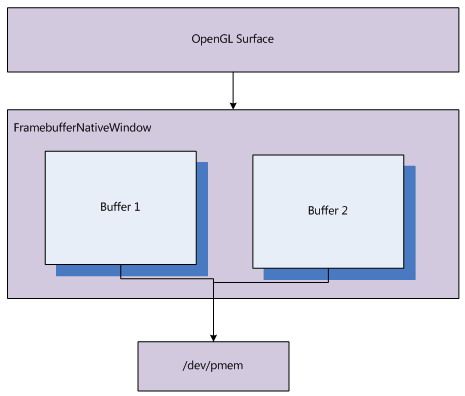
5. 图形显示
当图形内容被缓存到frameBuffer中后,最后的一步就是图形显示。代码中很明确就是SurfaceFlinger loop中的postFramebuffer()函数了。
这个函数最终回调到OpenGL的eglSwapBuffers()函数,这个函数主要有2个步骤(由于硬件加速代码不可见,我们仍然以软件加速为例)
1. 显示当前缓存buffer中内容;
首先,将原来的屏幕上的内容与最新需要显示的内容进行区域相减,将原来的内容copy到当前的缓存buffer中;
EGLBoolean egl_window_surface_v2_t::swapBuffers()@frameworks\base\opengl\libagl\egl.cpp
/*
* Handle eglSetSwapRectangleANDROID()
* We copyback from the front buffer
*/
if (!dirtyRegion.isEmpty()) {
dirtyRegion.andSelf(Rect(buffer->width, buffer->height));
if (previousBuffer) {
const Region copyBack(Region::subtract(oldDirtyRegion, dirtyRegion));
if (!copyBack.isEmpty()) {
void* prevBits;
if (lock(previousBuffer,
GRALLOC_USAGE_SW_READ_OFTEN, &prevBits) == NO_ERROR) {
// copy from previousBuffer to buffer
copyBlt(buffer, bits, previousBuffer, prevBits, copyBack);
unlock(previousBuffer);
}
}
}
oldDirtyRegion = dirtyRegion;
} 其次,如果当前的缓存buffer是申请自/dev/fb0,那么直接去显示这个缓存区中内容;如果
缓存buffer是申请自/dev/pmem,那么需要将缓存buffer中内容拷贝到/dev/fb0 buffer中去,其结构如上一节所示。
2. 对2个缓存buffer进行page flip(swap)操作。
通过 queueBuffer()操作将将当前Buffer交还给FramebufferNativeWindow,同时调用fb_post进行图形显示。然后通过dequeueBuffer()操作获得另外一个FramebufferNativeWindow的缓存Buffer,实现page flip(swap)操作。
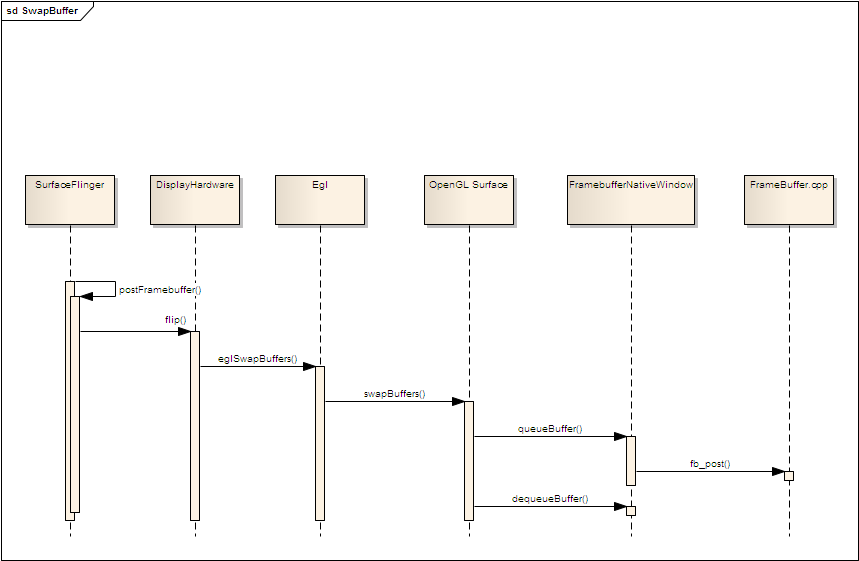
至此,整个的SurfaceFlinger的机制就分析完了。