JavaWeb 之 XML文档的DOM和SAX解析方式详解
笔记摘要:
这里主要介绍了DOM与SAX两种解析思想,其中DOM解析的开发包有Ajax和DOM4j,对于DOM4j,其强大的功能,在XPath方面尤为抢眼,
XPath类似于正则表达式,构建XPath表达式后就可以更方便快捷地获取想要的节点,另外这里还对于解析中其中出现的乱码问题
进行了详细的分析和解决
一、 XML解析技术概述
XML解析方式分为两种:dom和sax
dom:(Document Object Model, 即文档对象模型)
1.将整个XML使用类似树的结构保存在内存中,再对其进行操作。
2.是 W3C 组织推荐的处理 XML 的一种方式。
3.需要等到XML完全加载进内存才可以进行操作
4.耗费内存,当解析超大的XML时慎用。
5.可以方便的对xml进行增删该查操作
sax: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。
1.逐行扫描XML文档,当遇到标签时触发解析处理器,采用事件处理的方式解析xml
2.(Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。
3.在读取文档的同时即可对xml进行处理,不必等到文档加载结束,相对快捷
4.不需要加载进内存,因此不存在占用内存的问题,可以解析超大XML
5.只能用来读取XML中数据,无法进行增删改
XML解析器
Crimson、Xerces 、Aelfred2
XML解析开发包
Jaxp(sun,J2SE)、Jdom、dom4j
二、JAXP
JAXP 开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成
在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
2.1 使用JAXP进行DOM解析
javax.xml.parsers 包中的DocumentBuilderFactory用于创建DOM模式的解析器对象, DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法 ,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
调用DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
调用工厂对象的newDocumentBuilder方法得到 DOM 解析器对象。
调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
//1.创建工厂 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //2。得到dom解析器 DocumentBuilder builder = factory.newDocumentBuilder(); //3。解析xml文档,得到代表文档的document Document document = builder.parse("src/book.xml");
Dom解析主要方法为:getElementsByTagNmae(name).item(index);
doc.create
获取标签内容为:getTextContent();
属性:NamedNodeMap nodemap=node.getAttributes();
2.2 更新XML文档
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。
我们可以通过:javax.xml.transform.dom.DOMSource类来关联要转换的document对象,用javax.xml.transform.stream.StreamResult对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
public void writeToFile(){ Transformer transformer = TransformerFactory.newInstance().newTransformer(); DOMSource source = new DOMSource(document); FileOutputStream outstream =new FileOutputStream(new File("src/outbook3.xml")); StreamResult reslut = new StreamResult(outstream); transformer.transform(source, reslut); outstream.close(); }
2.3 示例
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书 书号="a111" 出版社="中信出版社">
<书名>做最好的自己</书名>
<特价>11.0元</特价>
<年份>1998</年份><作者>李开复</作者>
<售价>39.00元</售价>
<售价>111</售价></书>
<书 书号="a222" 出版社="机械工业出版社">
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书><年份>1998</年份>
</书架>
package cn.xushuai.xml;
import java.io.FileOutputStream;
import javax.swing.text.DocumentFilter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.junit.Test;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomByJaxp {
public Document getDoc() throws Exception{
DocumentBuilderFactory buildFactory = DocumentBuilderFactory.newInstance(); //获取解析工厂
DocumentBuilder builder = buildFactory.newDocumentBuilder(); //获取解析器
Document doc = builder.parse("book.xml"); //对文件进行解析
return doc;
}
//获取指定元素信息
@Test
public void get() throws Exception{
Document doc = getDoc();
//获取书名节点
NodeList list = doc.getElementsByTagName("书名");
// Node node = list.item(1);
Element node = (Element) list.item(1);
String name = node.getTextContent();
System.out.println(name);
}
//在指定位置上添加新的节点
@Test
public void add() throws Exception{
Document doc = getDoc();
Node parentNode = doc.getElementsByTagName("书").item(1);//获取父节点
Element priceEle = doc.createElement("特价"); //创建要添加的子节点
priceEle.setTextContent("14.00"); //设置节点内容
parentNode.appendChild(priceEle); //添加子节点
write2Xml(doc); //写入xml文档
}
//在指定位置上插入新的节点:特价
@Test
public void add2() throws Exception{
Document doc = getDoc(); //获取解析后的文档
Node parentNode = doc.getElementsByTagName("书").item(0); //获取父节点
Element newChild = doc.createElement("特价"); //创建新节点
newChild.setTextContent("10.00");
Node refNode = doc.getElementsByTagName("书名").item(0); //获取参考节点
parentNode.insertBefore(newChild, refNode); //通过父节点在在参考节点前添加上新节点
write2Xml(doc); //写入xml
}
//更新节点
@Test
public void update() throws Exception{
Document doc = getDoc();
Node parentNode = doc.getElementsByTagName("特价").item(0);
parentNode.setTextContent("100.00");
write2Xml(doc);
}
//删除节点
@Test
public void delete() throws Exception{
Document doc = getDoc();
Node childNode = doc.getElementsByTagName("特价").item(0); //获取要删除的节点
Node parentNode = childNode.getParentNode(); //获取父节点
parentNode.removeChild(childNode); //由父节点删除子节点
write2Xml(doc); //写入xml文档
}
//通过遍历的方式获取所有元素信息
@Test
public void getAllElement()throws Exception{
Document doc = getDoc();
Node root=doc.getElementsByTagName("书架").item(0);
listNode(root);
}
//递归的方式获取所有信息
public void listNode(Node node){
Node child;
if (node instanceof Element)
// System.out.println(node.getNodeName()+":"+node.getTextContent());
System.out.println(node.getTextContent());
NodeList nodelist = node.getChildNodes();
for (int i=0;i<nodelist.getLength();i++)
{
child = nodelist.item(i);
listNode(child);
}
}
//属性增删该查
@Test
public void attr()throws Exception{
Document doc = getDoc();
//4.获取<书>节点
Element bookNode = (Element)doc.getElementsByTagName("书").item(0);
//----1.增加属性
//bookNode.setAttribute("出版社", "人民出版社");
//----2.查找属性
//String publish = bookNode.getAttribute("出版社");
//System.out.println(publish);
//----3.修改属性
//bookNode.setAttribute("出版社", "人民教育出版社");
//----4.删除属性
//bookNode.removeAttribute("出版社");
//----5.获取属性的集合
NamedNodeMap attrs = bookNode.getAttributes();
for(int i=0;i<attrs.getLength();i++){
Attr attr = (Attr)attrs.item(i);
System.out.println(attr.getName()+":"+attr.getValue());
}
}
//将内存中的文件写入xml文件
public void write2Xml(Document doc) throws Exception{
TransformerFactory transFactory = TransformerFactory.newInstance();//获取转换工厂
Transformer transformer = transFactory.newTransformer(); //获取转换器
transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312");//输出之前指定编码
transformer.transform(new DOMSource(doc), new StreamResult(new FileOutputStream("book.xml")));//将内存中的dom树转换成xml文件中的xml数据
}
}
三、DOM编程
DOM模型(document object model)
DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。
在dom中,节点之间关系如下:
位于一个节点之上的节点是该节点的父节点(parent)
一个节点之下的节点是该节点的子节点(children)
同一层次,具有相同父节点的节点是兄弟节点(sibling)
一个节点的下一个层次的节点集合是节点后代(descendant)
父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)
节点类型(下页ppt)
Node对象提供了一系列常量来代表结点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便于调用其特有的方法。(查看API文档)
Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容了。
四、SAX解析
4.1 DOM方式与SAX解析方式的异同点:
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的 方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
阅读ContentHandler API文档,常用方法:startElement、endElement、characters
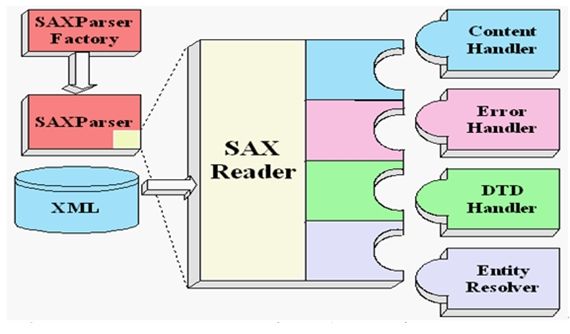
4.2 SAX方式解析XML文档
1.使用SAXParserFactory创建SAX解析工厂
SAXParserFactoryspf = SAXParserFactory.newInstance();
2.通过SAX解析工厂得到解析器对象
SAXParser sp =spf.newSAXParser();
3.通过解析器对象得到一个XML的读取器
XMLReaderxmlReader = sp.getXMLReader();
4.设置读取器的事件处理器
xmlReader.setContentHandler(newBookParserHandler());
5.解析xml文件
xmlReader.parse("book.xml");
增删改查元素,属性,把每一本书封装到一个book对象,并把book对象存入一个列表中
(注意断点调试的重要性。)
4.3 示例
<?xml version="1.0" encoding="GB2312" standalone="no"?> <书架> <书 email="[email protected]" 出版社="人民教育出版社" 种类="励志类"> <特价>100.00</特价><书名>做最好的自己</书名> <作者>李开复</作者> <价格>30</价格> <特价>10.00</特价> </书> <书 email="[email protected]" 出版社="机械工程出版社" 种类="励志类"> <书名>javaWeb开发</书名> <作者>张孝祥</作者> <价格>35</价格> </书> </书架>
package cn.xushuai.day02;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
public class SaxParser {
@Test
public void getParser() throws ParserConfigurationException, SAXException, IOException{
SAXParserFactory factory = SAXParserFactory.newInstance();//创建SAX解析工厂
SAXParser parser = factory.newSAXParser();//获取解析器
XMLReader reader = parser.getXMLReader(); //获取XML读取器
MyContentHandler4 handler4 = new MyContentHandler4();//设置事件处理器
reader.setContentHandler(handler4);
reader.parse("book.xml");//解析XMl文件
ArrayList bookList = (ArrayList) handler4.getList();//获取书本集合
for(int i=0;i<bookList.size();i++){
Book book = (Book) bookList.get(i);
System.out.println(book);
}
}
}
出现的问题:空指针异常,currentTag在标签介绍时未释放
package cn.xushuai.day02;
import java.util.ArrayList;
import java.util.List;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
//遍历整个标签体
public class MyContentHandler implements ContentHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("文档解析开始……");
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
//System.out.println("localName: "+localName);
System.out.println("发现开始标签: "+qName);
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("发现结束标签: "+qName);
}
@Override
public void endDocument() throws SAXException {
System.out.println("文档解析结束!!");
}
@Override
public void setDocumentLocator(Locator locator) {
// TODO Auto-generated method stub
}
@Override
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void endPrefixMapping(String prefix) throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void processingInstruction(String target, String data)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void skippedEntity(String name) throws SAXException {
// TODO Auto-generated method stub
}
}
//获取指定标签的标签体: 第二本书的作者
class MyContentHandler2 extends DefaultHandler{
boolean targetEle = false;
int count = 0;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if("作者".equals(qName)){
count++;
targetEle = true;
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if("作者".equals(qName))
targetEle = false;
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if(targetEle && count==2){
String author = new String(ch,start,length);
System.out.println(author);
}
}
}
//获取元素上的属性,注意:即使一个元素上没有属性,attrtibutes也并不是null,而是会传入一个没有封装任何属性的attributes。
//所以在判断一个元素是否有属性的时候不能attributes == null而应该attributes.getLength() == 0.
class MyContentHandler3 extends DefaultHandler{
int count= 0;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if("书".equals(qName)){
count++;
}
if(count == 2){
for(int i=0;i<attributes.getLength();i++){
String attName = attributes.getQName(i);
String attValue = attributes.getValue(i);
System.out.println("属性名:"+attName+"属性值:"+attValue);
}
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
}
}
//将解析出来的信息封装到对象中去,因为SAX解析只能读取,而且每次都要重新读取,所以将信息封装到集合当中存储起来就很有必要
class MyContentHandler4 extends DefaultHandler{
List<Book> bookList = new ArrayList<Book>();
Book book = null;
//String currentTag = "";
String currentTag = null;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
currentTag = qName;
/*if("作者".equals(qName))
currentTag = "作者";
if("书名".equals(qName))
currentTag = "书名";
if("价格".equals(qName))
currentTag = "价格";
if("特价".equals(qName))
currentTag = "特价";*/
if("书".equals(currentTag)){
book = new Book();
book.setPublishment(attributes.getValue("出版社"));
book.setEmail(attributes.getValue("email"));
book.setCategory(attributes.getValue("种类"));
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
/*if("书名".equals(currentTag)){
currentTag = "";
}
if("作者".equals(currentTag)){
currentTag = "";
}
if("价格".equals(currentTag)){
currentTag = "";
}
if("特价".equals(currentTag)){
currentTag = "";
}*/
if("书".equals(qName)){
bookList.add(book);
book = null;
}
//不置空会出现空指针异常
currentTag = null;
//currentTag= "";
/*这句有必要,否则会出现空指针异常,因为每一次在读到结束标签后,再次读取的是结束标签后的空白处,
由于currentTag在characters()中通过判断后,满足条件,所以会将空白部分的值赋给currentTag,
直到最后产生空指针异常*/
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
//获取标签体,为book设置属性
if("作者".equals(currentTag)){
book.setAuthor(new String(ch,start,length));
}
if("书名".equals(currentTag)){
book.setBookName(new String(ch,start,length));
}
if("价格".equals(currentTag)){
book.setPrice(new String(ch,start,length));
}
if("特价".equals(currentTag)){
book.setSpecialPrice(new String(ch,start,length));
}
}
public List getList(){
return bookList;
}
}
五、 DOM4J解析XML文档
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。
DOM4j方式解析都是先获取根节点,然后不断地:
.elements().get(index).element().getText( )/.element().getText( )
删除都是:
currentEle.getParent().remove(currentEle);
注意:
对于属性的删除操作,只能删除已经存在的属性,如果在一段代码中既创建了一个新的属性,又在后面进行删除,是删除不掉的
5.1 Document对象
DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = newSAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument();
//创建根节点
Element root = document.addElement("members");
5.2 节点对象
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Elementelement=node.element(“书名");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator();it.hasNext();) {
Element elm =(Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iteratorit=root.elementIterator();it.hasNext();){
Elementelement = (Element) it.next();
// dosomething
}
6.在某节点下添加子节点.
Element ageElm =newMemberElm.addElement("age");
7.设置节点文字.
element.setText("29");
8.删除某节点.
//childElm是待删除的节点,parentElm是其父节点
parentElm.remove(childElm);
9.添加一个CDATA节点.
Element contentElm = infoElm.addElement("content");
contentElm.addCDATA(diary.getContent());
5.3 节点对象属性
1.取得某节点下的某属性
Elementroot=document.getRootElement();
//属性名name
Attributeattribute=root.attribute("size");
2.取得属性的文字
Stringtext=attribute.getText();
3.删除某属性
Attribute attribute=root.attribute("size");
root.remove(attribute);
3.遍历某节点的所有属性
Elementroot=document.getRootElement();
for(Iteratorit=root.attributeIterator();it.hasNext();){
Attributeattribute = (Attribute) it.next();
Stringtext=attribute.getText();
System.out.println(text);
}
4.设置某节点的属性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.设置属性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
5.4 将文档写入XML文件
方式一:直接使用doc.write(writer);
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
doc.write(writer);
writer.close();
方式二:使用XMLWriter写入,直接通过指定编码
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
//writer.close();
5.5 乱码问题:
问题的出现:文件的编码与IO中Writer的编码不一致
IO字符流默认的编码为GB2312,字节流默认为UTF-8,而文件存储时一般默认为GB2312
方式一:
//这里会出现乱码问题,通常文件都是utf-8的,但是系统默认的编码是GB2312,所以使用字节转换流来指定编码
使用doc.write(writer)写入的乱码的解决:
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
doc.write(writer);
writer.close();
使用XMLWriter写入的乱码问题的解决
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
//writer.close();
使用XMLWriter时还可以使用OutputFormat来为xml文件指定编码,并根据指定的编码来确定XMLWriter参数中的Writer的编码格式
//指定编码为UTF-8,需要转换流指定编码
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");//会将xml文件的encoding属性改为给定的编码
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8"),format);
writer.write(doc);
writer.close();
//指定编码为GB2312
//因为setEncoding("gb2312")将文件的编码改成GB2312,又因为FileWriter默认为GB2312,所以可以解决乱码
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GB2312");
XMLWriter writer = new XMLWriter(new FileWriter("book.xml"),format);
writer.write(doc);
writer.close();
5.6 Dom4j在指定位置插入节点
1.得到插入位置的节点列表(list)
2.调用list.add(index,elemnent),由index决定element的插入位置。
Element元素可以通过DocumentHelper对象得到。
示例代码:
Element aaa =DocumentHelper.createElement("aaa");
aaa.setText("aaa");
List list = root.element("书").elements();
list.add(1, aaa);
//更新document
5.7 字符串与XML的转换
1.将字符串转化为XML
String text = "<members><member>sitinspring</member></members>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(newFile("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
5.8 示例
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书 书号="a111" 出版社="中信出版社">
<书名>做最好的自己</书名>
<特价>11.0元</特价>
<年份>1998</年份><作者>李开复</作者>
<售价>39.00元</售价>
<售价>111</售价></书>
<书 书号="a222" 出版社="机械工业出版社">
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书><年份>1998</年份>
</书架>
package cn.xushuai.day02;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class Dom4jTest {
@Test
public void find() throws DocumentException{
//创建解析器
SAXReader reader = new SAXReader();
//解析文档
Document doc = reader.read(new File("book.xml"));
//获取根节点
Element root = doc.getRootElement();
//获取第一本书的书名
String name = root.element("书").element("书名").getText();
//获取第二本书的书名
Element ele = (Element) root.elements().get(1);//获取第二本书
String name2 = ele.element("书名").getText();
System.out.println(name2);
//Attribute att = ele.attribute("种类");
}
@Test//通过DocumentHelper创建新节点后添加
public void add() throws DocumentException, IOException{
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("book.xml"));
Element root = doc.getRootElement();
//创建<页数>节点
Element paper = DocumentHelper.createElement("页数页数页数");
paper.setText("123");
//获取页数节点的父节点
Element bookEle = root.element("书");
bookEle.add(paper);
//更新XML文档
// doc.write(new FileWriter("book.xml"));//需要刷新,所以writer需要单独定义
//更新文档的第一种方式直接使用doc,write();
//这里会出现乱码问题,通常文件都是utf-8的,但是系统默认的编码是GB2312,所以使用字节转换流来指定编码
/* OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
doc.write(writer);
writer.close();*/
//使用XMLWriter写入
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
//writer.close();
//指定编码为UTF-8,需要转换流指定编码,
/*OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");//会将xml文件的encoding属性改为给定的编码
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8"),format);
writer.write(doc);
writer.close();*/
//指定编码为GB2312
//FileWriter默认为GB2312,所以只需setEncoding("gb2312")将文件的编码改成GB2312即可
/*OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GB2312");
XMLWriter writer = new XMLWriter(new FileWriter("book.xml"),format);
writer.write(doc);
writer.close();*/
}
@Test
public void add2() throws Exception{
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("book.xml"));
//直接添加新的节点:售价
Element bookEle = doc.getRootElement().element("书");
bookEle.addElement("售价").setText("111");
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
}
//在指定位置添加元素
@Test
public void add3()throws Exception{
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("book.xml"));
Element root = doc.getRootElement();
List book = root.element("书").elements();//书名,作者,价格,特价
Element day = DocumentHelper.createElement("年份");
day.setText("1998");
book.add(2, day);
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
}
@Test
public void del() throws Exception{
SAXReader reader = new SAXReader();
Document doc = reader.read(new File("book.xml"));
Element root = doc.getRootElement();
Element targetEle = (Element) root.elements("书").get(1);
Element specialEle = targetEle.element("特价");
specialEle.getParent().remove(specialEle);
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
}
@Test
public void attrTest() throws Exception{
SAXReader reader = new SAXReader();
Document doc = reader.read("book.xml");
Element root = doc.getRootElement();
Element bookEle = root.element("书");
//获取指定属性
Attribute attr = bookEle.attribute("种类");
String attrName = attr.getName();
String attrValue = attr.getValue();
System.out.println(attrName+":"+attrValue);
System.out.println("--------------");
//遍历所有属性
List attrList = bookEle.attributes();
for(int i=0;i<attrList.size();i++){
Attribute attribute = (Attribute) attrList.get(i);
String name = attribute.getName();
String value = attribute.getValue();
System.out.println(name+":"+value);
}
//添加属性
Attribute newAttr = DocumentHelper.createAttribute(bookEle, "年代", "90");
bookEle.add(newAttr);
//删除属性,只能删除原来已经存在的属性
bookEle.remove(bookEle.attribute("年代"));
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("book.xml"),"utf-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.write(doc);
xmlWriter.close();
}
@Test
public void xPath() throws Exception{
SAXReader reader = new SAXReader();
Document doc = reader.read("book.xml");
Element root = doc.getRootElement();
List list = root.selectNodes("/书架/书/作者");//获取所有书的作者
List author = root.selectNodes("//作者");//获取所有的作者
List book = root.selectNodes("/书架/书/*");//获取所有的书的所有节点
List book2 = root.selectNodes("/书架/书[1]/*");//获取第1本书的所有信息
List lastBook = root.selectNodes("/书架/书[last()]/*");//获取最后一本书的所有节点
List attList = root.selectNodes("//@书号");
List book3 = root.selectNodes("//书[@书号]");//获取具有书号属性的所有书
//只有父级节点才可以调用elementText(),通过子级节点名获取子级节点内容,否则会获取null
for(Iterator it = author.iterator();it.hasNext();){
Element ele = (Element)it.next();
//对于使用哪种方法获取信息,要看被遍历的元素的级别
System.out.println(ele.getText());
// System.out.println(ele.element("作者").getText());//当ele为书时,先获取作者节点再获取内容
// System.out.println(ele.elementText("作者"));//直接获取作者
// Attribute att = (Attribute) it.next();
// System.out.println(att.getText());
}
}
}