spark-shell初体验
1、复制文件至HDFS:
hadoop@Mhadoop:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user
hadoop@Mhadoop:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/hadoop
hadoop@Mhadoop:/usr/local/hadoop$ bin/hdfs dfs -copyFromLocal /usr/local/spark/spark-1.3.1-bin-hadoop2.4/README.md /user/hadoop/
hadoop@Mhadoop:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/hadoop
hadoop@Mhadoop:/usr/local/hadoop$ bin/hdfs dfs -copyFromLocal /usr/local/spark/spark-1.3.1-bin-hadoop2.4/README.md /user/hadoop/
2、运行spark-shell
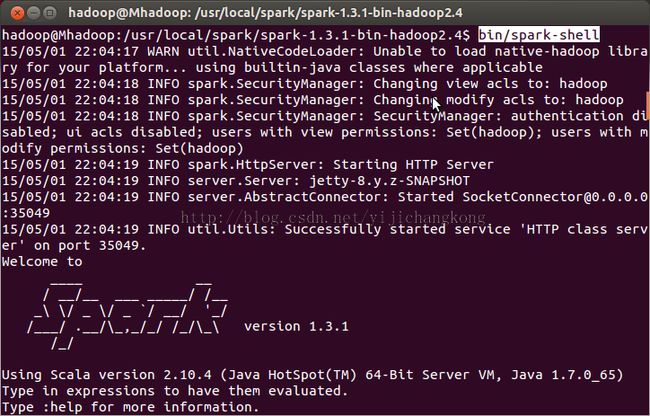
3、读取文件统计spark这个词出现次数
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@472ac3d3
scala> val file = sc.textFile("hdfs://Mhadoop:9000/user/hadoop/README.md")
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@472ac3d3
scala> val file = sc.textFile("hdfs://Mhadoop:9000/user/hadoop/README.md")
file: org.apache.spark.rdd.RDD[String] = hdfs://Mhadoop:9000/user/hadoop/README.md MapPartitionsRDD[1] at textFile at <console>:21
file变量是一个MapPartitionsRDD;接着过滤spark这个词
scala> val sparks = file.filter(line => line.contains("spark"))
sparks: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:23
sparks: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:23
统计spark出现次数,结果为11:
scala> sparks.count
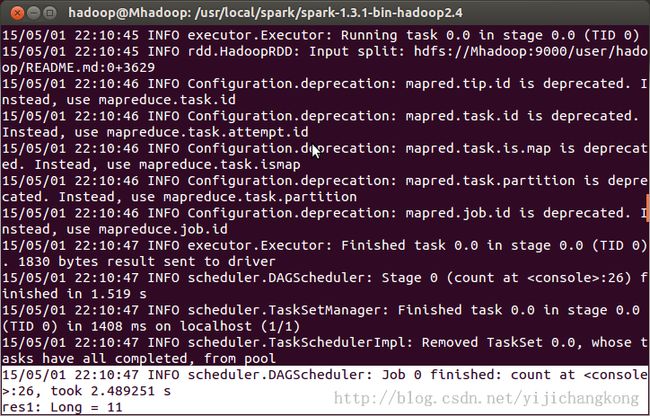
另开一个terminal用ubuntu自带的wc命令验证下:
hadoop@Mhadoop:/usr/local/spark/spark-1.3.1-bin-hadoop2.4$ grep spark README.md|wc
11 50 761
11 50 761
4、执行spark cache看下效率提升
scala> sparks.cache
res3: sparks.type = MapPartitionsRDD[2] at filter at <console>:23
res3: sparks.type = MapPartitionsRDD[2] at filter at <console>:23
登录控制台: http://192.168.85.10:4040/stages/

可见cache之后,耗时从s变为ms,性能提升明显。