对区间的模糊排序
7-6 对区间的模糊排序
考虑这样的一种排序问题,即无法准确地知道待排序的各个数字到底是多少。对于其中的每个数字,我们只知道它落在实轴上的某个区间。亦即,给定的是n个形如[ai,bi]的闭区间,其中ai≤bi。算法的目标是对这些区间进行模糊排序(fuzzy-sort),亦即,产生的各区间的一个排列<i1,i2,...,in>,使得存在一个cj∈[ai, bi],满足c1≤c2≤...≤cn。
a)为n个区间的模糊排序设计一个算法。你的算法应该具有算法的一般结构,它可以快速排序左部端点(即各ai),也要能充分利用重叠区间来改善运行时间。(随着各区间重叠得越来越多,对各个区间进行模糊排序的问题会变得越来越容易。你的算法应能充分利用这种重叠。)
b)证明:在一般情况下,你的算法的期望运行时间为Θ(nlgn),但当所有的区间都重叠时,期望的运行时间为Θ(n)(亦即,当存在一个值x,使得对所有的i,都有x∈[ai,bi])。你的算法不应显示地检查这种情况,而是应当随着重叠量的增加,性能自然地有所改善。
分析与解答:
先思考一个问题:为什么区间重叠能改善排序算法的期望运行时间呢?想明白了其实很简单,这相当于我们用快速排序一个数组时,数组中有很多重复元素,这样PARTITION时就可能非常高效。
a)首先定义两个线段的偏序关系(非唯一),如下图所示
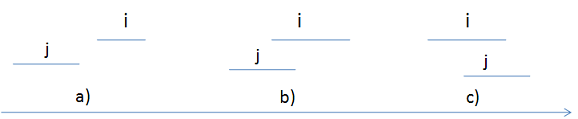
以线段i的左端点ai为参照物,分为三种情况:
1)线段j<线段i, 此时满足bj<ai
2)线段j=线段i, 此时满足bi≤ai≤bj。这样定义的原因是:最后可以让线段j和线段i的cj均取ai
3)现对j>线段i, 此时满足bi>ai
按照定义的偏序关系进行PATITION,期望的运行时间和快速排序的时间相同为Θ(nlgn)。
b)当所有的区间都重叠时,进行PATITION时

因为所有线段的右断点都位于X的右边,所以只需要考虑左端点
以线段i为枢轴元素为例,特别注意此时偏序关系只有两种情况:
1)若线段j的左端点bi≤ai,则线段j=线段i
因为线段j的右端点bj ≥x ≥ai,则bi≤ai≤bj,满足偏序关系的第2)定义。
2)若线段j的左端点bj>ai,则线段j>线段i
因为线段i是随机选择的,所以期望的情况下,ai位于所有线段的左端点的中间,可以写出运期望行时间的递归表达式
ET(n) = ET(n/2)+Θ(n)
根据主定律,可以得到期望运行时间 ET(n) 为Θ(n)