字符编码的概念及字符编码的探测
1 关于多字节与宽字符的解释
非英语系的大部分语言,存在无法用有限的ascii字符表达的问题。由此产生了使用多字节字符来表示的办法,比如GB编码的汉字。
但多字节带来的一个显著不便就是多字节字符在处理的时候不太方便。比如文本编辑的时候,中英文混排,光标移动、汉字删除时会出现半个汉字的问题。
为了文本处理的方便,许多系统内部采用了将多字节字符和单字节字符都转换称宽字符的办法,将所有的字符都变成等宽,一切都方便了。
在中文windows中,内码为GBK,而在Linux中,内码为utf32 。这样VC在中文系统下的wchar_t为2字节,GCC在Linux系统下wchar_t为4字节。
2 代码中的中文字符编码
2.1 C++源码中的中文
如果是多字节字符串,则编译器按照源文件的编码,对文件中的字符串进行处理,将字符硬编码到可执行文件中,在执行时,输出也直接输出此编码。这样有一个缺点,不同的字符使用不同的长度,操作效率不高。优点是,字符串占用内存空间小。
如果是使用wchar_t类型宽字符串,在常量字符串前加L"中国",这样编译器会根据系统代码页的编码,对源码字符串转换为UTF16(Win)/UTF32(Linux)的宽字符,然后硬编码到可执行程序中。这样,所有字符串均为等长编码;但采用这种作法,VC只能处理GBK编码的源文件,而GCC只能处理UTF8的源文件件。
采用上面策略处理的程序,如果在另外一个编码环境下执行,就会以错误的Locale来解码,界面或输出出现乱码。一种比较笨拙的办法,就是根据不同的系统环境,执行源码中编码到目的系统的编码的编码转换。这通常会比较笨拙,难以较好的实现国际化。较好的办法是不依赖本地的Locale编码,只使用标准编码之间的转换。
因此在Win平台下,淘汰多字节,只用宽字符。将所有字符串增加L宏,更好的办法是_T()宏。这样,如果是Unicode编译,就直接编码成UTF16。
在Linux下就不存在这个问题,由于在Linux版本均使用UTF8编码,编码转换均为UTF8到UTF32。
在Java和Python中,内码均Unicode。同时这些语言都有自己的解释器,解释器会将源代码中的字符都统一编码为Unicode在虚拟机内部统一使用。
2.2 Python源码中的中文
源代码文件可以是各种编码格式,如果不是UTF8,需要在源码的第一行指明:#-*-coding:gbk-*-;这样编译器会将源文件进行转换,从文件自身的编码转换为第一行指定的编码,然后再对源码文件进行解释执行。
#-*- coding:utf8 -*-
import sys
import os
print(sys.getdefaultencoding())
print(sys.stdout.encoding)
print(sys.stdin.encoding)
s = "中国ABAB"
print(s)
print(s.encode("utf8"))
print(s.encode("gbk"))
![]() 输出
输出 ![]()
utf-8
cp936
cp936
中国ABAB
b'\xe4\xb8\xad\xe5\x9b\xbdAB\xef\xbc\xa1\xef\xbc\xa2'
b'\xd6\xd0\xb9\xfaAB\xa3\xc1\xa3\xc2'
2.3 Java源码中的中文
类似于 Python
public static void testSrcCode()
{
String s = "中国ABAB";
int len = s.length();
for(int i=0; i<s.length();i++)
{
System.out.print(s.charAt(i));
System.out.printf(" code point: 0x%1$x\n",s.codePointAt(i));
}
System.out.println("-----------------------------------");
try
{
System.out.print("UTF8: ");
byte[] bt = s.getBytes("utf8");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
System.out.println("-----------------------------------");
try
{
System.out.print("GBK: ");
byte[] bt = s.getBytes("gbk");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
System.out.println("-----------------------------------");
try
{
System.out.print("UTF16: ");
byte[] bt = s.getBytes("utf16");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
输出
中 code point: 0x4e2d
国 code point: 0x56fd
A code point: 0x41
B code point: 0x42
A code point: 0xff21
B code point: 0xff22
-----------------------------------
UTF8: 0xe4 0xb8 0xad 0xe5 0x9b 0xbd 0x41 0x42 0xef 0xbc 0xa1 0xef 0xbc 0xa2
-----------------------------------
GBK: 0xd6 0xd0 0xb9 0xfa 0x41 0x42 0xa3 0xc1 0xa3 0xc2
-----------------------------------
UTF16: 0xfe 0xff 0x4e 0x2d 0x56 0xfd 0x0 0x41 0x0 0x42 0xff 0x21 0xff 0x22
2.4 BOM
文本文件头不同编码的标记,称为BOM,存储的时候可以指定为NO BOM,可以去掉此头。
UTF编码
BOM
UTF-8
EF BB BF
UTF-16LE
FF FE
UTF-16BE
FE FF
UTF-32LE
FF FE 00 00
UTF-32BE
00 00 FE FF
3 中文编码历史
在中文编码的历史上,在GB出现以前,已经存在一些汉字内码表示。所谓 内码即机内编码汉字的方法。为了便于不同内码系统之间的信息交换,国家定制了交换码。
在1980年,国家制定了GB2312,收集了约7K多个常用汉字。值得一提的是,GB2312使用了所谓的区位码的编码方法,但为了使得每个字节与ASCII编码区分,对每个字节(区码和位码)都增加了0xA0,即160。从这里可以看出,GB2312并没有编码ASCII字符及标点。
后续1995年又制定了GBK(CP939稍有差异)标准,为两字节编码 ,兼容GB2312,收集了2W多个汉字。同时也将ASCII字母及标点符号进行了编码,这样导致这些符号是两字节的,在显示的时候就是所谓的全角符号,直观看起来就是比较大。而英文模式下的字母和符号即为半角。
在unicode3.1标准出现之后,国家又制定了GB18030,其继续兼容 GBK ,并采用变长编码,将所有unicode字符均映射了一遍。和UFT8一样,采用了多字节编码。
4 中文显示原理
操作系统支持内码的字体集文件,内容为汉字的点阵信息,其可能按Unicode编码/内码进行索引。对于文件中的文字,首先转换成内码/unicode,按照查看字体文件,将点阵信息发送到显卡上。
操作系统提供了一个造字程序,可以选择一个编码,然后画出其字的点阵图,最后和字体文件进行链接。这样的特殊字符只能通过系统的特殊字符表来复制使用。
更进一步可以导入输入法表进行编辑,使得可以通过输入法来输出造的特殊字符。下图是随意造了一个三个羊组成的汉字,指定其Unicode编码为AAA1。
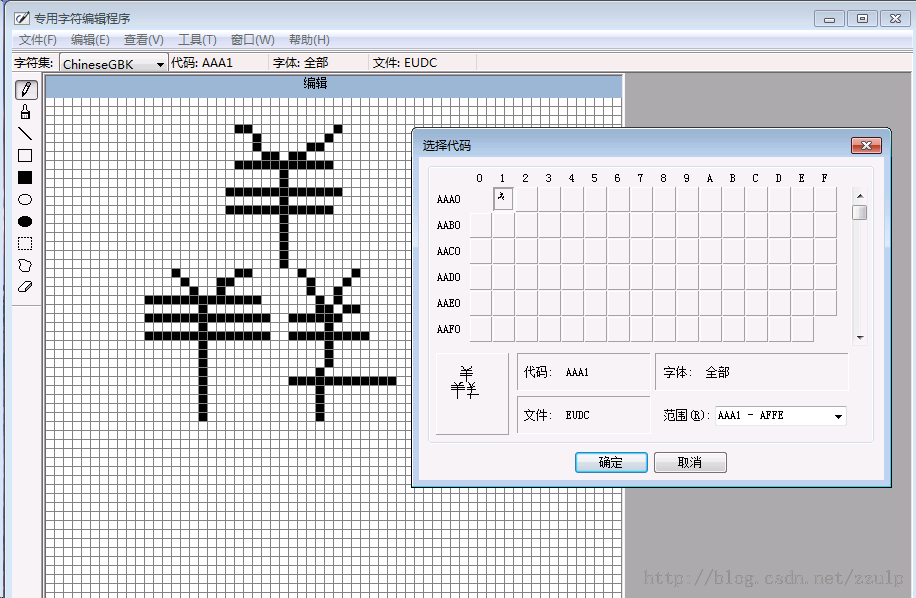
![]()
5 编码的探测
对于浏览器,在工具或查看中会有一个编码的选项,可以勾选为自动探测,这样当我们访问不同编码的网站时,浏览器会帮我们进行选择,而不用当出现乱码时,由我们去猜测并手工设定。下面介绍3个开源项目,可以实现检测一段输入的编码格式。
最早Mozilla开源了chardet项目,它用来对于输入进行分析,返回输入字节流的编码方式。其原理为
http://www-archive.mozilla.org/projects/intl/UniversalCharsetDetection.html
jchardet是一个基于chardet的java移植,cpdetector则是一个java探测框架,其中集成了jchardet的探测实现。
其他相应的移植还有python pchardet和C# nuniversalchardet项目。
下面介绍一下原理
5.1 编码方案法
当分析编码时,如果遇到了某种编码的非范围内的码点,则说明不是这种编码。
针对每种编码都设计一个检查状态机,对输入依次执行这些状态机。典型情况下,一个状态机将提供一个肯定的回答,而其他状态机返回一个否定的回答。
对于不同编码的重叠字符,则此方法无能为力。例如EUC-CN与EUC-KR之间有较多的重叠编码。
其特点是性能高,适合处理多字节编码,不适合处理单字节的,遇到重叠字符集时比较尴尬。
5.2 字符分布
在不同的语言中,存在着使用最为广泛的字,通过检测这些最广泛使用字来猜测源的编码。对于CJK字符比较有用。对于中文来说,最常用的256个汉字的CDF为61%,而4096个常用汉字则为99%。对于日文,最常用的128个字的CDF为77%。对于韩文为79%。也就是说很小集合的字的码点覆盖了较大比例的文字。能较好的解决编码重叠字符的问题。
为了得到特定语言编码中字母的分布情况,需要进行一定的统计计算。
一个简化版本是:分布率 = 最常见的512个字的出现次数/其余字母的出现次数。
例如对于GBK编码,在level1的3775个汉字中,最常见的512个汉字覆盖了文本中的79%的出现,当处理一个样本时,理论上应该得到分布率为 0.79/0.21=3.8;对于随机产生的文本,则分布率为512/3243 = 0.16,如果加入LEVEL2的汉字,这个比例会更小。
对于日文这两个数字为12.58 / 0.19 ,韩文为73.24 / 0.28
置信度的计算:
对于输入文本进行统计,计算实际分布率/理论分布率。
其特点是非常适合多字节编码,高效,但只适应于典型的文本(文本内容小时难以有效)。
5.3 两字符序列分布
对于字母类的语言,如果只有很少的元素组成了大量的单词。则不能用上面第二种方法,使用2字母的顺序的分布情况来分析。对于探测单字节语言比较有用。
例如,对于俄语,对大量文本进行分析,对于所有的两字母序列出现计数为20134122,其中1961个序列出现率比其他的低3倍,称1961个序列为此语言的负序列。通过计算,也可以得到置信度。计算算法没看明白。
其特点是适合单字节编码,对多字节效率差
5.4 组合方法
结合以上三种方法,得到一种最可信的结果。伪码如下:
Charset AutoDetection (InputText)
{
if (all characters in InputText are ASCII)
{
if InputText contains ESC or ~{
{
call ISO-2022 and HZ detector with InputText;
if one of them succeed,
return that charset,
otherwise
return ASCII;
}
else
return ASCII;
}
else if (InputText start with BOM)
{
return UCS2;
}
else
{
Call all multi-byte detectors and single-byte detectors;
Return the one with best confidence;
}
}5.4 字符探测实践
1 关于多字节与宽字符的解释
非英语系的大部分语言,存在无法用有限的ascii字符表达的问题。由此产生了使用多字节字符来表示的办法,比如GB编码的汉字。
但多字节带来的一个显著不便就是多字节字符在处理的时候不太方便。比如文本编辑的时候,中英文混排,光标移动、汉字删除时会出现半个汉字的问题。
为了文本处理的方便,许多系统内部采用了将多字节字符和单字节字符都转换称宽字符的办法,将所有的字符都变成等宽,一切都方便了。
在中文windows中,内码为GBK,而在Linux中,内码为utf32 。这样VC在中文系统下的wchar_t为2字节,GCC在Linux系统下wchar_t为4字节。
2 代码中的中文字符编码
2.1 C++源码中的中文
如果是多字节字符串,则编译器按照源文件的编码,对文件中的字符串进行处理,将字符硬编码到可执行文件中,在执行时,输出也直接输出此编码。这样有一个缺点,不同的字符使用不同的长度,操作效率不高。优点是,字符串占用内存空间小。
如果是使用wchar_t类型宽字符串,在常量字符串前加L"中国",这样编译器会根据系统代码页的编码,对源码字符串转换为UTF16(Win)/UTF32(Linux)的宽字符,然后硬编码到可执行程序中。这样,所有字符串均为等长编码;但采用这种作法,VC只能处理GBK编码的源文件,而GCC只能处理UTF8的源文件件。
采用上面策略处理的程序,如果在另外一个编码环境下执行,就会以错误的Locale来解码,界面或输出出现乱码。一种比较笨拙的办法,就是根据不同的系统环境,执行源码中编码到目的系统的编码的编码转换。这通常会比较笨拙,难以较好的实现国际化。较好的办法是不依赖本地的Locale编码,只使用标准编码之间的转换。
因此在Win平台下,淘汰多字节,只用宽字符。将所有字符串增加L宏,更好的办法是_T()宏。这样,如果是Unicode编译,就直接编码成UTF16。
在Linux下就不存在这个问题,由于在Linux版本均使用UTF8编码,编码转换均为UTF8到UTF32。
在Java和Python中,内码均Unicode。同时这些语言都有自己的解释器,解释器会将源代码中的字符都统一编码为Unicode在虚拟机内部统一使用。
2.2 Python源码中的中文
源代码文件可以是各种编码格式,如果不是UTF8,需要在源码的第一行指明:#-*-coding:gbk-*-;这样编译器会将源文件进行转换,从文件自身的编码转换为第一行指定的编码,然后再对源码文件进行解释执行。
#-*- coding:utf8 -*-
import sys
import os
print(sys.getdefaultencoding())
print(sys.stdout.encoding)
print(sys.stdin.encoding)
s = "中国ABAB"
print(s)
print(s.encode("utf8"))
print(s.encode("gbk"))
输出
utf-8 cp936 cp936 中国ABAB b'\xe4\xb8\xad\xe5\x9b\xbdAB\xef\xbc\xa1\xef\xbc\xa2' b'\xd6\xd0\xb9\xfaAB\xa3\xc1\xa3\xc2'
2.3 Java源码中的中文
类似于 Python
public static void testSrcCode()
{
String s = "中国ABAB";
int len = s.length();
for(int i=0; i<s.length();i++)
{
System.out.print(s.charAt(i));
System.out.printf(" code point: 0x%1$x\n",s.codePointAt(i));
}
System.out.println("-----------------------------------");
try
{
System.out.print("UTF8: ");
byte[] bt = s.getBytes("utf8");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
System.out.println("-----------------------------------");
try
{
System.out.print("GBK: ");
byte[] bt = s.getBytes("gbk");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
System.out.println("-----------------------------------");
try
{
System.out.print("UTF16: ");
byte[] bt = s.getBytes("utf16");
for(int j = 0;j < bt.length ;j++)
{
System.out.printf("0x%1$x ",bt[j]);
}
System.out.println();
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
输出
中 code point: 0x4e2d 国 code point: 0x56fd A code point: 0x41 B code point: 0x42 A code point: 0xff21 B code point: 0xff22 ----------------------------------- UTF8: 0xe4 0xb8 0xad 0xe5 0x9b 0xbd 0x41 0x42 0xef 0xbc 0xa1 0xef 0xbc 0xa2 ----------------------------------- GBK: 0xd6 0xd0 0xb9 0xfa 0x41 0x42 0xa3 0xc1 0xa3 0xc2 ----------------------------------- UTF16: 0xfe 0xff 0x4e 0x2d 0x56 0xfd 0x0 0x41 0x0 0x42 0xff 0x21 0xff 0x22
2.4 BOM
文本文件头不同编码的标记,称为BOM,存储的时候可以指定为NO BOM,可以去掉此头。
| UTF编码 |
BOM |
| UTF-8 |
EF BB BF |
| UTF-16LE |
FF FE |
| UTF-16BE |
FE FF |
| UTF-32LE |
FF FE 00 00 |
| UTF-32BE |
00 00 FE FF |
3 中文编码历史
在中文编码的历史上,在GB出现以前,已经存在一些汉字内码表示。所谓 内码即机内编码汉字的方法。为了便于不同内码系统之间的信息交换,国家定制了交换码。
在1980年,国家制定了GB2312,收集了约7K多个常用汉字。值得一提的是,GB2312使用了所谓的区位码的编码方法,但为了使得每个字节与ASCII编码区分,对每个字节(区码和位码)都增加了0xA0,即160。从这里可以看出,GB2312并没有编码ASCII字符及标点。
后续1995年又制定了GBK(CP939稍有差异)标准,为两字节编码 ,兼容GB2312,收集了2W多个汉字。同时也将ASCII字母及标点符号进行了编码,这样导致这些符号是两字节的,在显示的时候就是所谓的全角符号,直观看起来就是比较大。而英文模式下的字母和符号即为半角。
在unicode3.1标准出现之后,国家又制定了GB18030,其继续兼容 GBK ,并采用变长编码,将所有unicode字符均映射了一遍。和UFT8一样,采用了多字节编码。
4 中文显示原理
操作系统支持内码的字体集文件,内容为汉字的点阵信息,其可能按Unicode编码/内码进行索引。对于文件中的文字,首先转换成内码/unicode,按照查看字体文件,将点阵信息发送到显卡上。
操作系统提供了一个造字程序,可以选择一个编码,然后画出其字的点阵图,最后和字体文件进行链接。这样的特殊字符只能通过系统的特殊字符表来复制使用。
更进一步可以导入输入法表进行编辑,使得可以通过输入法来输出造的特殊字符。下图是随意造了一个三个羊组成的汉字,指定其Unicode编码为AAA1。
最早Mozilla开源了chardet项目,它用来对于输入进行分析,返回输入字节流的编码方式。其原理为
http://www-archive.mozilla.org/projects/intl/UniversalCharsetDetection.html
jchardet是一个基于chardet的java移植,cpdetector则是一个java探测框架,其中集成了jchardet的探测实现。
Charset AutoDetection (InputText)
{
if (all characters in InputText are ASCII)
{
if InputText contains ESC or ~{
{
call ISO-2022 and HZ detector with InputText;
if one of them succeed,
return that charset,
otherwise
return ASCII;
}
else
return ASCII;
}
else if (InputText start with BOM)
{
return UCS2;
}
else
{
Call all multi-byte detectors and single-byte detectors;
Return the one with best confidence;
}
}5.4 字符探测实践
下面介绍如何利用cpdector框架来进行编码探测。框架提供了一个CodepageDetertorProxy类,其为单例类。通过这个类的对象,为其添加各种解码实现对象,然后调用其提供的detectCodepage()方法即可。
import java.io.*;
import java.net.*;
import info.monitorenter.cpdetector.io.*;
class ChardetWrapper
{
// Create the proxy:
CodepageDetectorProxy detector = CodepageDetectorProxy.getInstance(); // A singleton.
// constructor:
public ChardetWrapper()
{
// Add the implementations of
// info.monitorenter.cpdetector.io.ICodepageDetector:
// This one is quick if we deal with unicode codepages:
detector.add(new ByteOrderMarkDetector());
// The first instance delegated to tries to detect the meta charset
// attribut in html pages.
detector.add(new ParsingDetector(false)); // be verbose about parsing.
// This one does the tricks of exclusion and frequency detection, if
// first implementation is
// unsuccessful:
detector.add(JChardetFacade.getInstance()); // Another singleton.
detector.add(ASCIIDetector.getInstance()); // Fallback, see javadoc.
}
public boolean parseUrl(String url) throws MalformedURLException, IOException
{
boolean ret = false;
// Work with the configured proxy:
java.nio.charset.Charset charset = null;
charset = detector.detectCodepage(new URL(url));
if(charset == null)
{
System.out.println("bogus document");
}
else
{
System.out.println(charset.toString());
// Open the document in the given code page:
// Read from it, do sth., whatever you desire. The character are now - hopefully - correct..
ret = true;
}
return ret;
}
public boolean parseFile(String file) throws MalformedURLException, IOException
{
boolean ret = false;
// Work with the configured proxy:
java.nio.charset.Charset charset = null;
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
charset = detector.detectCodepage(bis,10240000);
if(charset == null)
{
System.out.println("bogus document");
}
else
{
System.out.println(charset.toString());
// Open the document in the given code page:
// Read from it, do sth., whatever you desire. The character are now - hopefully - correct..
ret = true;
}
return ret;
}
}
public class CpdetTest
{
public static void main(String[] args)
{
ChardetWrapper u = new ChardetWrapper();
String url = "http://www.sina.com";
//String path = "C:/字幕/007:来自俄罗斯的爱情.ass";
try
{
//u.parseFile(path);
u.parseUrl(url);
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
也可以直接使用jchardec来进行探测,其要求继承ChardetObserver接口,并实现notify方法,库会在探测成功后通过notify方法将结果传出来。
import java.io.*;
import java.net.*;
import java.util.*;
import org.mozilla.intl.chardet.*;
class myChardecObserver implements nsICharsetDetectionObserver
{
public void Notify(String charset)
{
CharsetDetectorTest.found = true;
System.out.println("CHARSET = " + charset);
}
}
public class CharsetDetectorTest {
public static boolean found = false;
public static void main(String argv[]) throws Exception {
// Initalize the nsDetector() ;
int lang = (argv.length == 2) ? Integer.parseInt(argv[1]): nsPSMDetector.ALL;
nsDetector detector = new nsDetector(nsPSMDetector.ALL);
// Set an observer...
// The Notify() will be called when a matching charset is found.
detector.Init(new myChardecObserver());
URL url = new URL("http://www.sina.com//");
BufferedInputStream bis = new BufferedInputStream(url.openStream());
//FileInputStream fis = new FileInputStream("C:/字幕/007:来自俄罗斯的爱情.ass");
//BufferedInputStream bis = new BufferedInputStream(fis);
byte[] buf = new byte[512];
int len;
boolean done = false;
boolean isAscii = true;
while ((len = bis.read(buf, 0, buf.length)) != -1 )
{
//System.out.printf("Read byte %d\n",len);
// Check if the stream is only ascii.
if (isAscii)
isAscii = detector.isAscii(buf, len);
// DoIt if non-ascii and not done yet.
if (!isAscii && !done)
done = detector.DoIt(buf, len, false);
}
detector.DataEnd();
if (isAscii)
{
System.out.println("CHARSET = ASCII");
found = true;
}
if (!found)
{
String prob[] = detector.getProbableCharsets();
for (int i = 0; i < prob.length; i++)
{
System.out.println("Probable Charset = " + prob[i]);
}
}
}
}