《linux 内核完全剖析》 chapter 3 内核编程语言和环境
内核编程语言和环境
汇编语言部分:
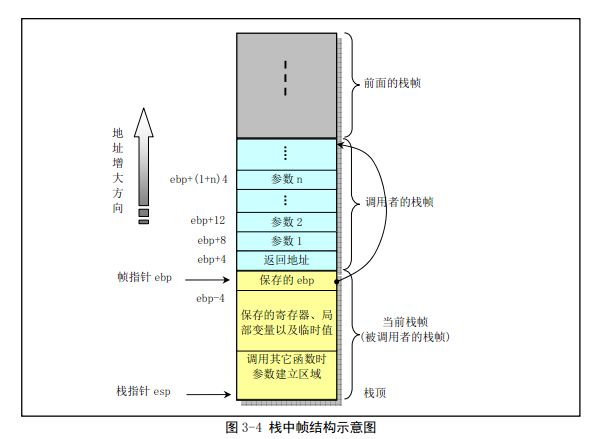
栈帧结构
单个函数调用操作所使用的栈部分被称作stack frame栈帧结构。如图。栈帧结构的两端用两个指针来指定(其实我觉得应该是一个栈顶固定,然后一个寻址移动。)寄存器ebp通常做帧指针frame pointer。而esp则做栈指针stack pointer。
1.前缀
在Intel的语法中,寄存器和和立即数都没有前缀。但是在AT&T中,寄存器前冠以“%”,而立即数前冠以“$”。在Intel的语法中,十六进制和二进制立即数后缀分别
冠以“h”和“b”,而在AT&T中,十六进制立即数前冠以“0x”,表2.2给出几个相应
的例子
Intel与AT&T前缀的区别
Intel语法 AT&T语法
mov eax,8 movl $8,%eax
mov ebx,0ffffh movl $0xffff,%ebx
int 80h int $0x80
2. 操作数的方向
Intel与AT&T操作数的方向正好相反。在Intel语法中,第一个操作数是目的操作数,第二个操作数源操作数。而在AT&T中,第一个数是源操作数,第二个数是目的操作数
在Intel中,mov eax,[ebx+5]
在AT&T,movl 5(%ebx),%eax
3.操作码的后缀
在上面的例子中你可能已注意到,在AT&T的操作码后面有一个后缀,其含义就是指出操作码的大小。“l”表示长整数(32位),“w”表示字(16位),“b”表示字节
(8位)。而在Intel的语法中,则要在内存单元操作数的前面加上byte ptr、 word ptr,
和dword ptr,“dword”对应“long”。表2.4给出几个相应的例子。
4. AT&T中的节(Section)
在AT&T的语法中,一个节由.section关键词来标识,当你编写汇编语言程序时,至少需要有以下三种节:
.section .data: 这种节包含程序已初始化的数据,也就是说,包含具有初值的那些变量,例如:
hello : .string "Hello world!\n"
hello_len : .long 13
.section .bss:这个节包含程序还未初始化的数据,也就是说,包含没有初值的那些变量。当操作系统装入这个程序 时将把这些变量都置为0,例如
name : .fill 30 # 用来请求用户输入名字
name_len : .long 0 # 名字的长度 (尚未定义)
当这个程序被装入时,name 和 name_len都被置为0。如果你在.bss节不小心给一个变量赋了初值,这个值也会丢失,并且变量的值仍为0。使用.bss比使用.data的优势在于,.bss节不占用磁盘的空间。在磁盘上,一个长整数
就足以存放.bss节。当程序被装入到内存时,操作系统也只分配给这个节4个字节的内存大小
注意:
编译程序把.data和.bss在4字节上对齐(align),例如,.data总共有34字节,那么编译程序把它对其在36字节上,也就是说,实际给它36字节的空间。
.section .text :这个节包含程序的代码,它是只读节,而.data 和.bss是读/写节。
汇编程序指令(Assembler Directive)
上面介绍的.section就是汇编程序指令的一种,GNU汇编程序提供了很多这样的指令(directiv),这种指令都是以句点(.)为开头,后跟指令名(小写字母),在此,我们只介绍在内核源代码中出现的几个指令(arch/i386/kernel/head.S中的代码为例)。(1)ascii "string"...
.ascii 表示零个或多个(用逗号隔开)字符串,并把每个字符串(结尾不自动加“0“字节)中的字符放在连续的地址单元。还有一个与.ascii类似的.asciz,z代表“0“,即每个字符串结尾自动加一个”0“字节,例如:
int_msg:
.asciz "Unknown interrupt\n"
(2).byte 表达式
.byte表示零或多个表达式(用逗号隔开),每个表达式被放在下一个字节单元。
(3).fill 表达式
形式:.fill repeat , size , value
其中,repeat、size 和value都是常量表达式。Fill的含义是反复拷贝size个字节。
Repeat可以大于等于0。size也可以大于等于0,但不能超过8,如果超过8,也只取8。把repeat个字节以8个为一组,每组的最高4个字节内容为0,最低4字节内容置为value。Size和 value为可选项。如果第二个逗号和value值不存在,则假定value为0。如果第一个逗号和size不存在,则假定size为1。
例如,在Linux初始化的过程中,对全局描述符表GDT进行设置的最后一句为:
.fill NR_CPUS*4,8,0 /* space for TSS's and LDT's */
因为每个描述符正好占8个字节,因此,.fill给每个CPU留有存放4个描述符的位置。
(4).globl symbol
.globl使得连接程序(ld)能够看到symbl。如果你的局部程序中定义了symbl,那么,与这个局部程序连接的其他局部程序也能存取symbl,例如:
.globl SYMBOL_NAME(idt)
.globl SYMBOL_NAME(gdt)
定义idt和gdt为全局符号。
(5)quad bignums
.quad表示零个或多个bignums(用逗号分隔),对于每个bignum,其缺省值是8字节整数。如果bignum超过8字节,则打印一个警告信息;并只取bignum最低8字节。
例如,对全局描述符表的填充就用到这个指令:
.quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */
.quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at 0x00000000 */
.quad 0x00cffa000000ffff /* 0x23 user 4GB code at 0x00000000 */
.quad 0x00cff2000000ffff /* 0x2b user 4GB data at 0x00000000 */
(6)rept count
把.rept指令与.endr指令之间的行重复count次,例如
.rept 3
.long 0
.endr
相当于
.long 0
.long 0
.long 0
(7)space size , fill
这个指令保留size个字节的空间,每个字节的值为fill。size 和fill都是常量表达式。如果逗号和fill被省略,则假定fill为0,例如在arch/i386/bootl/setup.S中有一句:
.space 1024
表示保留1024字节的空间,并且每个字节的值为0。
(8).word expressions
这个表达式表示任意一节中的一个或多个表达式(用逗号分开),表达式的值占两个字节,例如:
gdt_descr:
.word GDT_ENTRIES*8-1
表示变量gdt_descr的置为GDT_ENTRIES*8-1
(9).long expressions
这与.word类似
(10).org new-lc , fill
把当前节的位置计数器提前到new-lc(new location counter)。new-lc或者是一个常量表达式,或者是一个与当前子节处于同一节的表达式。也就是说,你不能用.org横跨节:如果new-lc是个错误的值,则.org被忽略。.org只能增加位置计数器的值,或者让其保持不变;但绝不能用.org来让位置计数器倒退。
注意:
位置计数器的起始值是相对于一个节的开始的,而不是子节的开始。当位置计数器被提升后,中间位置的字节被填充值fill(这也是一个常量表达式)。如果逗号和fill都省略,则fill的缺省值为0。
例如:.org 0x2000
ENTRY(pg0)
表示把位置计数器置为0x2000,这个位置存放的就是临时页表pg0。
Gcc嵌入式汇编(待更新)
这是我最感到无力的地方。。。待更新吧。。。很多指令看不懂。。。
光作笔记,没有demo怎么会欢乐。
自己写个简单的死的程序,然后反汇编一下
int main()
{
int a;
int b;
a = 10;
b = 20;
a = a+b;
return 0;
}
.file "hello.c"//文件“hello.c”
.text //test段为空
.globl main //把main定义为全局变量
.type main, @function //调用main函数
main:
.LFB0:
.cfi_startproc//这个应该是程序初始化,为main函数的运行做准备。和后面的.cfi_endproc对应
pushq %rbp //把rbp压栈保存
.cfi_def_cfa_offset 16 //这个应该是把当前栈顶偏移16个字节,为储存变量a,b做准备
.cfi_offset 6,-16 //布吉岛。。。。路过的高手求教一下
movq %rsp, %rbp //把栈顶指针寄存器rsp的值移送到rbp帧指针寄存器
.cfi_def_cfa_register 6 //布吉岛。。。
movl $10, -8(%rbp //把数值10赋值到rbp寄存器保存值减去八的地址中。也就是当前rbp保存地址的向低地址偏移8个
//字节的位置,变量a的地址
movl $20, -4(%rbp)
//把数值20赋值到rbp寄存器保存值减去四的地址中。也就是当前rbp保存地址的向低地址偏移4个
//字节的位置,变量b的地址
movl -4(%rbp), %eax //把rbp向低地址偏移4个字节偏移的地址处的值(就是b)移送给eax寄存器
addl %eax, -8(%rbp) //把eax寄存器的值加给rbp向下偏移8个字节的地址处的值(就是a)。此处a = a+b结束
movl $0, %eax //把0赋值给eax寄存器,对应最后那句return0;
popq %rbp //弹栈,把rbp的值销毁。
.cfi_def_cfa 7, 8
ret //返回
.cfi_endproc //对应前面的cfi_startproc,此处结束当前程序
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro4.7.3-1ubuntu1) 4.7.3"
.section .note.GNU-stack,"",@progbits
我昨天和今天能够happy一点的事情就是,我居然能大概看懂这家伙。。。以前我完全看不懂。。。
有个图更方便理解
linux 0.12 目标文件格式

Makefile:
之前看过一句很搞的话“Makefile is not make love”哈哈、、、、
我觉得这个部分书上写的好啰嗦。。。其实我觉得makefile说明起来还是挺简单的
“会不会写 makefile,从一个侧面说明了一个人是否具备完成大型工程的能力” 这个是陈东华说的,他写的《跟我一起写makefile》我就觉得写的很好。
Makefile 的规则。 也是makefile最核心的思想
target ... : prerequisites ... command
target:
也就是一个目标文件,可以是Object File,也可以是执行文件。还可以是一个标签(Label),对于标签 这种特性,在后续的“伪目标”章节中会有叙述。
prerequisites
就是,要生成那个 target 所需要的文件或是目标。
command
也就是 make 需要执行的命令。(任意的 Shell 命令)
这是一个文件的依赖关系,也就是说,target这一个或多个的目标文件依赖于prerequisites 中的文件,其生成规则定义在 command 中。说白一点就是说,prerequisites中如果有一个以上的文件比 target 文件要新的话,command 所定义的命令就会被执行。这就是 Makefile 的规则。也就是 Makefile 中最核心的内容。
我自己看这个的时候已经写过一点makefile了,所以看这个小节的时候觉得还挺“舒服”
下面是我自己写二叉树的时候自己写的一个很简单的Makefile
FILE_C = binary_search_tree.c free_tree.c insert_node.c print_tree.cdelete_node.c insert_for_delete.c
FILE_O = binary_search_tree.o free_tree.o insert_node.o print_tree.odelete_node.o insert_for_delete.o
compile:${FILE_C}
gcc -g -c ${FILE_C}
link:${FILE_O}
gcc ${FILE_O} -o ./tree.out
clean:
rm -f binary_search_tree.o free_tree.o insert_node.o print_tree.odelete_node.o insert_for_delete.o ./tree.out