linux 性能监控命令6——mpstat,vmstat,iostat
1、mpstat
mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。下面只介绍mpstat与CPU相关的参数,mpstat的语法如下:
mpstat [-P {|ALL}] [internal [count]]
参数的含义如下:
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。
从第二行开始,输出为前一个interval时间段的平均信息。与CPU有关的输出的含义如下:
参数 解释 从/proc/stat获得数据
CPU 处理器ID
user 在internal时间段里,用户态的CPU时间(%),不包含 nice值为负 进程 (usr/total)*100
nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
system 在internal时间段里,核心时间(%) (system/total)*100
iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
irq 在internal时间段里,硬中断时间(%) (irq/total)*100
soft 在internal时间段里,软中断时间(%) (softirq/total)*100
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)(idle/total)*100
intr/s 在internal时间段里,每秒CPU接收的中断的次数intr/total)*100
CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
范例1:average mode (粗略信息)
当mpstat不带参数时,输出为从系统启动以来的平均值。
CODE:
[work@builder linux-2.6.14]$mpstat
Linux 2.6.9-5.31AXsmp (builder.redflag-linux.com) 12/16/2005
09:38:46 AM CPU %user %nice %system %iowait %irq %soft %idle intr/s
09:38:48 AM all 23.28 0.00 1.75 0.50 0.00 0.00 74.47 1018.59
范例2: 每2秒产生了2个处理器的统计数据报告
下面的命令可以每2秒产生了2个处理器的统计数据报告,一共产生三个interval 的信息,然后再给出这三个interval的平均信息。默认时,输出是按照CPU 号排序。第一个行给出了从系统引导以来的所有活跃数据。接下来每行对应一个处理器的活跃状态。。
CODE:
[root@server yum_dir]#mpstat -P ALL 2 3
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
09:34:20 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:22 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.49
09:34:22 PM 0 0.00 0.00 0.50 0.00 0.00 0.00 0.00 99.50 1001.00
09:34:22 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
09:34:22 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:24 PM all 0.00 0.00 0.25 0.00 0.00 0.00 0.00 99.75 1005.00
09:34:24 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1005.50
09:34:24 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
09:34:24 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:26 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.49
09:34:26 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.00
09:34:26 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
Average: all 0.00 0.00 0.08 0.00 0.00 0.00 0.00 99.92 1002.66
Average: 0 0.00 0.00 0.17 0.00 0.00 0.00 0.00 99.83 1002.49
Average: 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
[root@server yum_dir]#
范例3:比较带参数和不带参数的mpstat的结果。
在后台开一个2G的文件
# cat 1.img &
然后在另一个终端运行mpstat命令
CODE:
[root@server ~]# cat 1.img &
[1] 6934
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:31 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:31 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.40 1004.57
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:35 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:35 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.39 1004.73
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:39 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:39 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.38 1004.96
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:44 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:44 PM all 0.07 0.02 0.26 0.21 0.01 0.05 0.00 99.37 1005.20
[root@server ~]# mpstat 3 10
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:55 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:58 PM all 13.12 0.00 20.93 0.00 1.83 9.80 0.00 54.32 2488.08
10:18:01 PM all 10.82 0.00 19.30 0.83 1.83 9.32 0.00 57.90 2449.83
10:18:04 PM all 10.95 0.00 20.40 0.17 1.99 8.62 0.00 57.88 2384.05
10:18:07 PM all 10.47 0.00 18.11 0.00 1.50 8.47 0.00 61.46 2416.00
10:18:10 PM all 11.81 0.00 22.63 0.00 1.83 11.98 0.00 51.75 2210.60
10:18:13 PM all 6.31 0.00 10.80 0.00 1.00 5.32 0.00 76.58 1795.33
10:18:19 PM all 1.75 0.00 3.16 0.75 0.25 1.25 0.00 92.85 1245.18
10:18:22 PM all 11.94 0.00 19.07 0.00 1.99 8.29 0.00 58.71 2630.46
10:18:25 PM all 11.65 0.00 19.30 0.50 2.00 9.15 0.00 57.40 2673.91
10:18:28 PM all 11.44 0.00 21.06 0.33 1.99 10.61 0.00 54.56 2369.87
Average: all 9.27 0.00 16.18 0.30 1.50 7.64 0.00 65.11 2173.54
[root@server ~]#
上两表显示出当要正确反映系统的情况,需要正确使用命令的参数。vmstat 和iostat 也需要注意这一问题。
2、vmstat
很显然从名字中我们就可以知道vmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具,但是怎样通过vmstat来发现系统中的瓶颈呢?在回答这个问题前,还是让我们回顾一下Linux中关于虚拟内存相关内容。
虚拟内存运行原理:
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
使用vmstat;
1.用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。引申閱讀: http://www.cnblogs.com/leoo2sk/archive/2009/12/11/talk-about-fork-in-linux.html
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
2.使用说明
例子1:每2秒输出一条结果
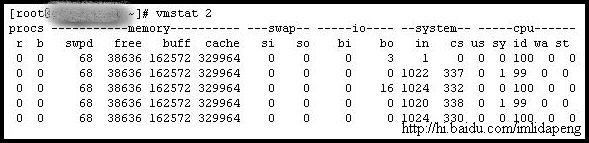
字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间)
wa: 等待IO时间
例子2:显示活跃和非活跃内存
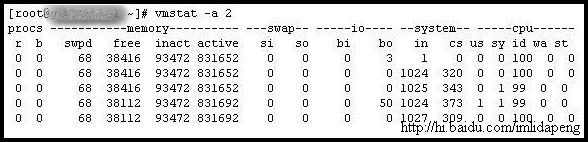
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
3、iostat
iostat [ -c ] [ -d ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ] [ device [...] | ALL ]
[ -p [ device [,...] | ALL ] ] [ interval [ count ] ]
-c为汇报CPU的使用情况;
-d为汇报磁盘的使用情况;
-k表示每秒按kilobytes字节显示数据;
-t为打印汇报的时间;
-v表示打印出版本信息和用法;
-x device指定要统计的设备名称,默认为所有的设备;
interval指每次统计间隔的时间;
count指按照这个时间间隔统计的次数。
常见用法:
iostat -d -k 1 5 查看磁盘吞吐量等信息。
iostat -d -x -k 1 5 查看磁盘使用率、响应时间等信息
iostat –x 1 5 查看cpu信息。
iostat -x 1(-x:显示扩展信息)
cpu:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
【注】
如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但
系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那
么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
【注】
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明
I/O 队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有当量io在等待。