Java温故知新 - 集合类
一、常用集合类实现
1.ArrayDeque/LinkedList:双端队列的数组和链表实现
2.HashSet/Map:散列表
3.TreeSet/Map:红黑树
实际上,TreeSet在内部使用了TreeMap,当添加新元素时,会向TreeMap放入一个空Object作为值。
3.1 在实现Comparable和Comparator的compare方法时,正数表示:该对象或参数1对象大。
因此,用参数2对象的域值减去参数1的对于域将会产生倒序。
建议:compare()==0时equals()==true
3.2 向TreeSet放入未实现Comparable接口的类会在运行时产生ClassCaseException。
3.3 若构造TreeSet时,传入了自定义的Comparator,则比较时将会以Comparator的compare方法为准。
源码参见:TreeMap的put方法。
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Item> setById = new TreeSet<Item>();
// 1.Exception if Item not implement Comparable interface
// Exception in thread "main" java.lang.ClassCastException: Item cannot be cast to java.lang.Comparable
setById.add(new Item(1, "level 9"));
setById.add(new Item(2, "level 2"));
setById.add(new Item(3, "level 5"));
System.out.println(setById);
// 2.Use comparator
TreeSet<Item> setByDesc = new TreeSet<Item>(
new Comparator<Item>() {
@Override
public int compare(Item o1, Item o2) {
return o1.desc.compareTo(o2.desc);
}
});
setByDesc.addAll(setById);
System.out.println(setByDesc);
}
}
class Item implements Comparable<Item> {
int id;
String desc;
Item(int id, String desc) {
this.id = id;
this.desc = desc;
}
@Override
public int compareTo(Item o) {
return id - o.id;
}
@Override
public String toString() {
return "Item [id=" + id + ", desc=" + desc + "]";
}
}
4.ProrityQueue:优先级队列(堆)
5.LinkedHashSet/Map:记录插入顺序(LRU)
public class LRUTest {
public static void main(String[] args) {
Map<Item, Integer> lruMap = new LinkedHashMap<Item, Integer>() {
private static final long serialVersionUID = 1L;
@Override
protected boolean removeEldestEntry(Map.Entry<Item, Integer> eldest) {
return size() > 3;
}
};
lruMap.put(new Item(1, "111"), 1);
lruMap.put(new Item(2, "222"), 2);
lruMap.put(new Item(3, "333"), 3);
lruMap.put(new Item(4, "444"), 4);
System.out.println(lruMap);
lruMap.put(new Item(5, "555"), 5);
System.out.println(lruMap);
}
}
二、常用算法封装
1.排序算法
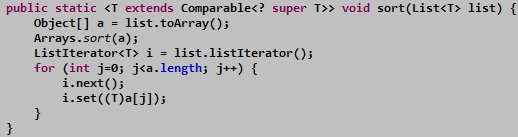
对集合类排序时,首先将其转成数组,然后通过Arrays.sort方法进行归并排序。
学过算法都知道快速排序是需要额外空间更少,执行更快,这里之所以选取归并
排序是因为它是稳定的,不会破坏相同元素之间的相对顺序。
源码如下:
2.查找算法
对于实现了RandomAccess的数据结构,也就是可以在O(1)时间内定位元素,
那么查找算法将采用直接下标定位的二分查找,在log(N)时间内找到要查找的元素。
否则将通过一个迭代器不断前后移动来定位二分后的位置,实现一种低效些的二分
查找。
源码如下:
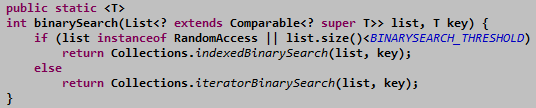
indexedBinarySearch和iteratorBinarySearch就是查找算法的两种策略。两个方法的
唯一差别就是定位元素的位置。在indexedBinarySearch方法中,直接通过list.get获得,
而iteratorBinarySearch是通过list上的迭代器不断移动来获得的。
RandomAccess接口的继承层次:
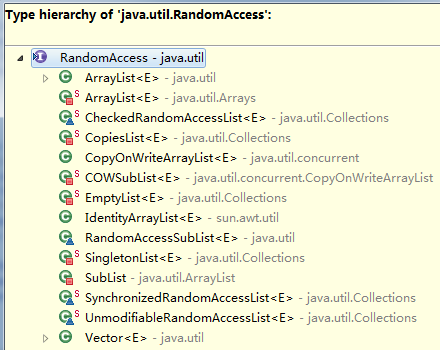
所以对于ArrayList就可以直接通过下标来定位元素,实现二分查找查找。
而对于LinkedList链表,就只能通过iterator不断移动来定位了,显然我们
是没法在O(1)时间内定位链表中的任意元素。
另外注意对于size小于BINARYSEARCH_THRESHOLD(5000)的非RandomAccess数据结构,
也是会采用indexedBinarySearch策略。也就是说当长度小于5000,不通过迭代器而是每次
都从头向后定位到中间的元素的效率是可以接受的。