msyql中文乱码问题
参考:http://hi.baidu.com/ayongs/item/30f784122c8d51a5ffded509
http://www.2cto.com/database/201108/101151.html
http://www.laruence.com/2008/01/05/12.html
mysql5.1参考手册
一.mysql字符集
MySQL 4.1及以上版本的字符集支持(Character Set Support)有两个方面:字符集(Character Set)和校对规则(Collation)。 字符集和校对规则有4个级别的默认设置:服务器(server),数据库(database),数据表(table)和连接(connection)。
MySQL 中是根据下面几个变量确定服务器端和客户端用的什么字符集:
character_set_client 客户端字符集
character_set_connection 客户端与服务器端连接采用的字符集
character_set_results SELECT查询返回数据的字符集
character_set_database 数据库采用的字符集
在服务器级别,确定方法很简单。当启动 mysqld时,根据使用的初始选项设置来确定服务器字符集和 校对规则。如:mysqld --default-character-set=utf8 ,如果启动mysql时没有指定 --default-character-set选项,那么默认的服务器级字符集为编译mysql时指定的字符集,由configure时的:--with-charset和--with-collation选项确实,默认的字符集为latin1.
每一个数据库有一个数据库字符集和一个数据库校对规则,它不能够为空。CREATE DATABASE和ALTER DATABASE语句有一个可选的子句来指定数据库字符集和校对规则:
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]如 create database ulogd default character set utf8;
如果创建数据库时没用指定字符集,那么该数据库默认的字符集为当前服务器所使用的字符集。
每一个表有一个表字符集和一个校对规则,它不能为空。为指定表字符集和校对规则,CREATE TABLE 和ALTER TABLE语句有一个可选的子句:
CREATE TABLE tbl_name (column_list)
[DEFAULT CHARACTER SET charset_name [COLLATE collation_name]]如果创建表时没有指定表的字符集,那么该表字符集为当前数据库所使用的字符集。
每一个“字符”列(即,CHAR、VARCHAR或TEXT类型的列)有一个列字符集和一个列 校对规则,它不能为空。列定义语法有一个可选子句来指定列字符集和校对规则:
col_name {CHAR | VARCHAR | TEXT} (col_length)
[CHARACTER SET charset_name [COLLATE collation_name]]如果没有指定列的字符集,那么该列的字符集为当前表的字符集
示例1:表和列定义
CREATE TABLE t1
(
c1 CHAR(10) CHARACTER SET latin1 COLLATE latin1_german1_ci
) DEFAULT CHARACTER SET latin2 COLLATE latin2_bin;
在这里我们有一个列使用latin1字符集和latin1_german1_ci校对规则。是显式的定义,因此简单明了。需要注意的是,在一个latin2表中存储一个latin1列不会存在问题。
示例2:表和列定义
CREATE TABLE t1
(
c1 CHAR(10) CHARACTER SET latin1
) DEFAULT CHARACTER SET latin1 COLLATE latin1_danish_ci;
这次我们有一个列使用latin1字符集和一个默认校对规则。尽管它显得自然,默认校对规则却不是表级。相反,因为latin1的默认校对规则总是latin1_swedish_ci,列c1有一个校对规则latin1_swedish_ci(而不是latin1_danish_ci)。
示例3:表和列定义
CREATE TABLE t1
(
c1 CHAR(10)
) DEFAULT CHARACTER SET latin1 COLLATE latin1_danish_ci;
我们有一个列使用一个默认字符集和一个默认校对规则。在这种情况下,MySQL查找表级别来确定列字符集和 校对规则。因此,列c1的字符集是latin1,它的 校对规则是latin1_danish_ci。
示例4:数据库、表和列定义
CREATE DATABASE d1
DEFAULT CHARACTER SET latin2 COLLATE latin2_czech_ci;
USE d1;
CREATE TABLE t1
(
c1 CHAR(10)
);
我们创建了一个没有指定字符集和校对规则的列。我们也没有指定表级字符集和校对规则。在这种情况下,MySQL查找数据库级的相关设置。(数据库的设置变为表的设置,其后变为列的设置。)因此,列c1的字符集为是latin2,它的 校对规则是latin2_czech_ci。
连接字符集和校对
考虑什么是一个“连接”:它是连接服务器时所作的事情。客户端发送SQL语句,例如查询,通过连接发送到服务器。服务器通过连接发送响应给客户端,例如结果集。对于客户端连接,这样会导致一些关于连接的字符集和 校对规则的问题,这些问题均能够通过系统变量来解决:
· 当查询离开客户端后,在查询中使用哪种字符集?
服务器使用character_set_client变量作为客户端发送的查询中使用的字符集。
· 服务器接收到查询后应该转换为哪种字符集?
转换时,服务器使用character_set_connection和collation_connection系统变量。它将客户端发送的查询从character_set_client系统变量转换到character_set_connection(除非字符串文字具有象_latin1或_utf8的引介词)。collation_connection对比较文字字符串是重要的。对于列值的字符串比较,它不重要,因为列具有更高的 校对规则优先级。
· 服务器发送结果集或返回错误信息到客户端之前应该转换为哪种字符集?
character_set_results变量指示服务器返回查询结果到客户端使用的字符集。包括结果数据,例如列值和结果元数据(如列名)。
总结如下:请求阶段:
1. 程序所使用的字符集转换为客户端字符集(character_set_client在连接数据库字符串中指定)。
2.客户端字符集(character_set_client)转换为character_set_connection字符集
3.然后服务器会检测存储区域(table,column)的字符集,然后把数据从连接字符集(character_set_connection)转为存储区域(table,column)的字符集,然后再存储或者查询。
返回阶段:
1.服务器将存储区域(table,column)的字符集转换为character_set_results字符集返回。
2.character_set_results字符集转换为程序所使用的字符集。
这里的程序可为自己写的应用程序,也可为mysql图形界面的访问工具或者终端。如果这些访问工具的字符集没有设置好,那么也会出现乱码。
根据以上原理,在上术字符集的转换过程中,如果任何一个转换字符集不兼容,那么就有可能出现乱码。
二.实战篇
查看各级别字符集当前默认的字符集,命令如下: (在登录msyql系统后,在选择某个数据库之前执行)
1. status
2. show variables like 'char%'
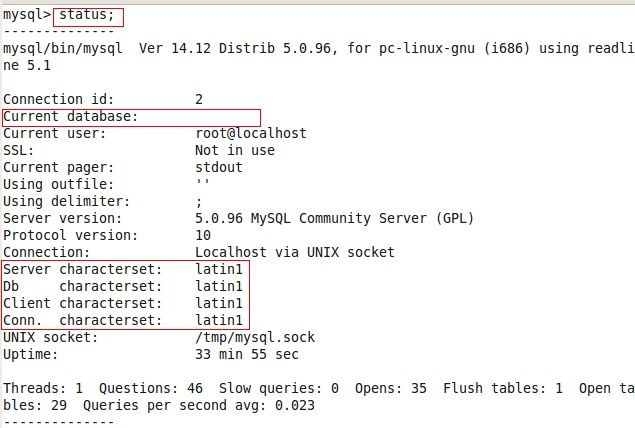
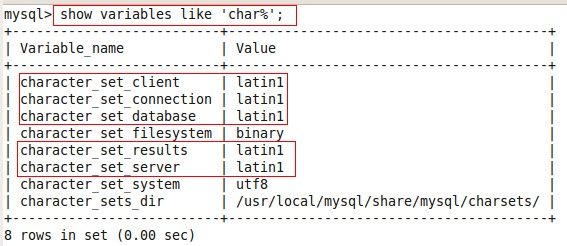
查看某个数据库,某个表,某一个字符列当前使用的字符集,命令如下:
1. status (选择某个数据库之后再执行)
2. show variables like 'char%' (选择某个数据库之后再执行)
3. show create database database_name
4. show create table table_name
5 show full columns from table_name
如果根据这些查看,每个阶段的转换字符集都兼容,但还是出现了乱码,那么请确定,你是否在插入数据之后再更改了数据库的字符集设置。
修改字符集的设置:
第一种:在/etc/my.cnf 文件中
[client] 下加入
#默认字符集为utf8
default-character-set = utf8
[mysqld] 下加入
# 默认字符集为utf8
default-character-set = utf8
第二种:在登录msyql后修改
mysql> SET character_set_client = utf8 ;
mysql> SET character_set_connection = utf8 ;
mysql> SET character_set_database = utf8 ;
mysql> SET character_set_results = utf8 ;
mysql> SET character_set_server = utf8 ;
mysql> SET collation_connection = utf8 ;
mysql> SET collation_database = utf8 ;
mysql> SET collation_server = utf8 ;
一般就算设置了表的默认字符集为utf8并且通过UTF-8编码发送查询,你会发现存入数据库的仍然是乱码。问题就出在这个connection连接层上。解决方法是在发送查询前执行一下下面这句:
SET NAMES 'utf8';
它相当于下面的三句指令:SET character_set_client = utf8;
SET character_set_results = utf8;
SET character_set_connection = utf8;
重要的有二两点:
1) 正确的设定数据库编码.MySQL4.0以下版本的字符集总是默认ISO8859-1,MySQL4.1在安装的时候会让你选择。如果你准备使用UTF- 8,那么在创建数据库的时候就要指定好UTF-8(创建好以后也可以改,4.1以上版本还可以单独指定表的字符集)
2) 正确的设定数据库connection编码.设置好数据库的编码后,在连接数据库时候,应该在连接字符串中指定客户端的编码,比如使用jdbc连接时,指定连接为utf8方式.
对于用C语言连接mysql如果没有在连接字符串中指定编码,那中文很有可能会出现乱码!!
C语言用 mysql_options 或者mysql_set_character_set指定字符集
另附常用的mysql命令:http://www.cppblog.com/zzg/archive/2009/05/29/86066.html
mysql -u ulogd -pulogd #登录数据库,用户名为ulogd,密码为ulogd
show databases; #查看有哪些数据库
use ulogd; #选择一个数据库ulogd
show tables; #查看当前数据库的数据表
describe ulog2; #查看数据表ulog2的结构
quit; #退出数据库
查看存储过程(用root用户执行)
show procedure status;
select `name` from mysql.proc where db = 'ulogd' and (type = 'function' or type = 'procedure');
注意,这里的name左右的是反引号,而不是单引号
查看存储过程或函数的创建代码
show create procedure proc_name;
show create function func_name;
创建数据库
echo "create database ulogd character set utf8;" | mysql -u root -proot
导入脚本
/usr/local/mysql/bin/mysql -u root -proot -D ulogd < ./doc/mysql-ulogd2.sql
添加一个用户,并设置权限
echo "grant create, insert, select, delete, update on ulogd.* to ulogd@localhost identified by 'ulogd'" | /usr/local/mysql/bin/mysql -u root -proot
查看当前状态:status