通过前面几篇文章,相信大家已经对jafka的使用和其源码结构有了一定的了解,接下来笔者将尝试去向大家讲解jafka是如何实现其分布式特性的。所谓分布式,在jafka就是producer broker和consumer都是可以分布在多台机器上运行的。当然,producer的分布式是无需多言的,因为它就相当于一个客户端,多个producer之间不会协作或互相影响,所以也谈不上分布式。但broker和consumer就不同了,本文就从broker和consumer两个方面来讲。首先我们来看jafka实现分布式的基础zookeeper的基本特性。
zookeeper简介
zookeeper是一个开源分布式的服务,它提供了分布式协作,分布式同步,配置等功能。它实现了一个层次名字空间的数据模型,其上的文件称为znode,主要有3中类型:
- Persisten Node:永久存储,除非client主动要求删除
- Ephemeral Node:临时节点,client失去与zookeeper的连接时,数据丢失。
- Sequence Node:顺序节点,它是实现分布式锁等特殊功能的关键,在jafka中没有使用,不做过多介绍。
zookeeper还为client提供了watch功能,即client可以声明监控znode,当这些znode的数据发生变化时,zookeeper便会触发事件,交由client处理。
Jafka主要用到zookeeper的这些知识,至于其深入的知识就交由感兴趣的读者自行去挖掘了。
Broker分布式
Broker主要在zookeeper上负责两类数据的注册:broker和topic。
broker
在讲解broker使用时,配置文件中有broker.id项,该值在broker的集群中必须唯一。使用id的另一个目的是便于broker的迁移,即broker程序从机器A迁到机器B,只要broker id没有变,那么consumer producer不会受到影响。
broker在zookeeper的注册的znode为:/brokers/ids/[0...N]。[0...N]即为broker的id,其中的内容是host:port。另外该znode为ephemeral node,即当一个broker挂掉了,这个znode便会消失。原因是显而易见的,这样便可以实现监控broker运行状况的功能,提高系统的可用性。
举例:broker (id 为1)启动后,zookeeper中会有这样的znode:
/brokers/ids/1 ---> localhost:9001
topic
broker启动时,会把data.dir中的数据文件(jafka文件)以一定形式整理入内存,同时还会将topic及其partition数目写入zookeeper,其znode为/brokers/topics/[topic]/[0...N],另外它也是ephemeral node,原因是这个数据依赖于broker,而broker是ephemeral的。[topic]即为topic的名称,它是Persisten类型的,而[0...N]即为broker的id,其内容为partition的数目。
举例:broker 1的data.dir中有如下三个文件夹haha-0 haha-1 haha-2,表明haha这个topic的partition数目为3,则zookeeper中会有如下的znode
/brokers/topics/haha/1 --> 3
另外当有一个new topic出现时,broker也会负责将其注册到zk上。
源码
下面我们来看broker注册数据到zk上的源码,集中在LogManager.startup方法中。
public void startup() {
if (config.getEnableZookeeper()) {
//注册broker
serverRegister.registerBrokerInZk();
for (String topic : getAllTopics()) {
//注册topic和其partition数目
serverRegister.processTask(new TopicTask(TaskType.CREATE, topic));
}
startupLatch.countDown();
}
logger.info("Starting log flusher every " + config.getFlushSchedulerThreadRate() + " ms with the following overrides " + logFlushIntervalMap);
...
}在startup方法中首先注册broker的信息,即/brokers/ids/[broker_id],之后注册topic及其所在broker的partition数目。详细注册过程就交由读者自己去研读了。
producer与zookeeper的交互
我们来看下producer对于上述注册信息的使用,假设producer发送的topic为haha,该topic在两个broker(0,1)上存储,且partition数目为3。
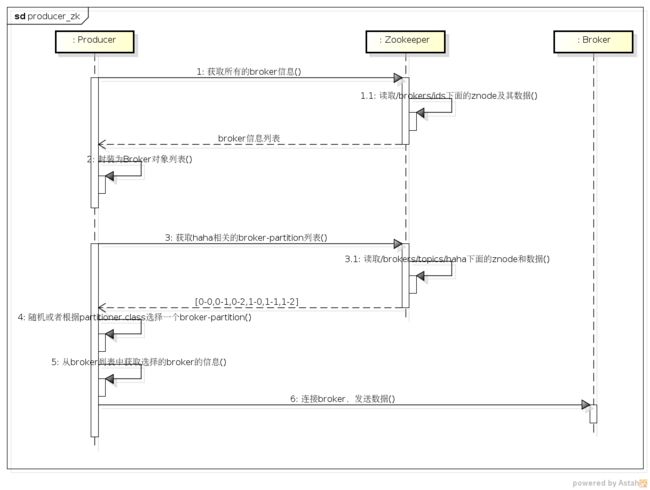
producer与zookeeper的交互是比较简单的,如下:
-
1.获取所有broker列表,这里是要读取broker的id和其hostname port的基本信息。
- 2.读取要传送topic所在的brokerid以及其上的partition数目,组成broker-partition列表。
broker将自身信息注册在zookeeper中,producer从zk上读取所有的broker,然后选择某一个broker来发送消息,这样所有的broker便组成了一个集群,虽然这个集群中的broker都是相互独立的。
Consumer分布式
Consumer的分布式相较Broker就来的复杂些。jafka在设计上,允许consumer多线程消费,以group的形式来组织consumer,所以其在zk上的注册也是以group为根文件夹的。
问题
consumer需要注册什么信息到zk上?
我们来分析一下:
- 一个consumer group中有多个consumer,它们共同来消费一个或者多个topic,而每个topic在每个broker上都有一个或者多个partition,所以consumer实际面对的是一个或者多个broker-partition。那么为了将这些broker-partition合理地分配给这些consumer,我们必定要知道topic相关的broker-partition列表和consumer列表,然后在这两者之间进行分配。由上文可知,前者可以从
/brokers/topics/[topic]/[0...N]中获得,后者还没有方式获取。那么consumer就需要在zk上注册该信息,其znode为/consumers/[group_id]/ids/[consumer_id],其内容为该consumer的消费的topic和消费的线程数目列表。
举例:group名为china,其上有2个consumer,假设其id分别为consumer0和consumer1。consumer0消费topic为haha和hehe,分配的线程数为2和3.consumer1消费haha,线程数为2。那么zookeeper上有以下的znode。
/consumers/china/ids/consumer0 --->{"haha":2,"hehe":3}
/consumer1 --->{"haha":2}到此,我们可以获取消费某个topic的所有consumer信息了。另外这些znode也都是ephemeral类型的。另外从这里也能获取某个consumer的所有消费的信息。
- consumer开始消费数据,但如果consumer遇到故障down掉了,当将其重启时如何继续之前的消费呢?办法简单,即时地记录其消费情况嘛,在jafka,其消费情况便是offset信息。那该数据存储在哪里?这个选择就多样了,jafka默认存储在zookeeper上,当然你也可以选择存储在文件或者数据库中。其在zookeeper上的znode为:
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id],其中存储着已经消费的offset信息。另外该znode为persistent类型,这样即便consumer重启也可以读取到该信息,而继续消费。
- 当一个group中有consumer新加入或者退出时,重新分配消费的broker-partition是必须的。那么分配之后某个consumer负责消费的broker-partition就可能改变,要知道这个rebalance的触发是在consumer消费过程中的,如果我们直接重新分配消费任务,可能会造成消息数据的重复消费。比如consumer0正在消费broker-partition 0-0和0-1,这是rebalance触发,重新分配后的结果是consumer0只消费0-0,0-1给另一个consumer1消费,这里便会有一个消费任务的交接工作:consumer0停止消费0-1,consumer1继续消费0-1。如果不交接任务的话,0-1就被重复消费了。可是consumer之间是不能直接通信的,那就通过一个中介zookeeper,在其上注册一个信息声明某个consumer占有某个broker-partition,在该consumer释放该broker-partition之前,该值一直存在。这样,消费任务的交接工作便可以以此信息作为一个依据来检测是否成功交接。该znode为:
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id],其中存储着consumer_node_id。
到这里,在一个group中的所有consumer就可以互相协作来完成任务了。
consumer与zookeeper的交互
我们来consumer与zookeeper交互的时序图。

从上面的图中,我们可以看到consumer和zookeeper是如何交互从而完成本身工作的。
Jafka在zookeeper上的监听和相关类
上面主要讲解了broker和consumer在zookeeper中维护相关数据,除此以外,jafka还使用了zookeeper提供的watch功能,用来监听broker的运行状况、consumer的新增等事件。
producer
Producer监听的相关类为ZKBrokerPartitionInfo,其注册监听事件的代码为
public ZKBrokerPartitionInfo(ZKConfig zkConfig, Callback callback) {
...
this.zkClient = new ZkClient(zkConfig.getZkConnect(), //
zkConfig.getZkSessionTimeoutMs(), //
zkConfig.getZkConnectionTimeoutMs(),//
ZKStringSerializer.getInstance());
this.brokerTopicsListener = new BrokerTopicsListener(this.topicBrokerPartitions, this.allBrokers);
//register listener for change of topics to keep topicsBrokerPartitions updated
//监听/brokers/topics
zkClient.subscribeChildChanges(ZkUtils.BrokerTopicsPath, brokerTopicsListener);
//监听/brokers/topics/[topic]
for (String topic : this.topicBrokerPartitions.keySet()) {
zkClient.subscribeChildChanges(ZkUtils.BrokerTopicsPath + "/" + topic, this.brokerTopicsListener);
}
//监听/brokers/ids
zkClient.subscribeChildChanges(ZkUtils.BrokerIdsPath, this.brokerTopicsListener);
//
// register listener for session expired event
zkClient.subscribeStateChanges(new ZKSessionExpirationListener());
}由上面代码可知,producer主要监听了/brokers/topics,/brokers/topics/[topic],/brokers/ids,当这三者发生变化时,调用brokerTopicsListener的方法进行处理,具体处理逻辑大家可以区看该对象的源码,这里就不罗列。说一下监控这三者的作用:
- /brokers/topics => 监听topic的变化,以更新topicsBrokerPartitions
- /brokers/topics/[topic] => 监听broker的变化,以更新topicsBrokerPartitions
- /brokers/ids => 监听broker的变化,以更新allBrokers信息。
Consumer
Consumer注册监听事件是在ZookeeperConsumerConnector.consume方法中,如下:
//listener to consumer and partition changes
ZKRebalancerListener<T> loadBalancerListener = new ZKRebalancerListener<T>(config.getGroupId(),
consumerIdString, ret);
this.rebalancerListeners.add(loadBalancerListener);
loadBalancerListener.start();
//监控consumer本身的变化,/consumers/[group_id]/ids/[consumer_id]
zkClient.subscribeStateChanges(new ZKSessionExpireListener<T>(dirs, consumerIdString, topicCount,
loadBalancerListener));
//监控consumer的变化 /consumers/[group_id]/ids
zkClient.subscribeChildChanges(dirs.consumerRegistryDir, loadBalancerListener);
//
//监控topic的partition变化, /brokers/topics/topic
for (String topic : ret.keySet()) {
//register on broker partition path changes
final String partitionPath = ZkUtils.BrokerTopicsPath + "/" + topic;
zkClient.subscribeChildChanges(partitionPath, loadBalancerListener);
}consumer主要监听下面三类znode:
- /consumers/[group_id/ids/[consumer_id] => 监控consumer消费的topic的变化
- /consumers/[group_id]/ids => 监控consumer变化,当有consumer增加或者减少时作出反应
- /brokers/topics/[topic] => 监控消费topic的partition变化
当consumer监控到上述三种变化时,调用loadBalancerListener处理方法,重新进行任务分配。
小结
本文主要讲解了Jafka中分布式特性的实现原理,重点介绍了broker与consumer,分别就其信息注册和事件监听进行了讲解,希望对大家有所帮助