【北大天网搜索引擎TSE学习笔记】第6节——获取用户输入
这一节将介绍搜索功能入口程序TSESearch.cpp的第二步——获取用户输入。
(一)
获取用户在浏览器中输入的查询数据,需要跟web服务器进行数据交互,这就用到了前面提到的CGI方式。如果对CGI程序还是不太熟悉,请先阅读相关资料学习(推荐:http://blog.csdn.net/lewsn2008/article/details/8519908)。这里简单叙述一下,CGI程序怎样获取用户在浏览器中输入的数据。
首先,说明一下,index.html中的定义的form的method属性是“get”,也就是浏览器将以“get模式”向服务器发送数据,服务器的CGI程序也需要以“get模式”来获取数据。用户输入搜索字符串然后点击搜索按钮后,会想服务器发送一个合成的URL,在我的TSE中输入“清华大学”点击搜索按钮得到URL为:
服务器的CGI程序怎样获取URL中附加的数据信息呢?服务器收到用户的请求信息后会把数据设置到环境变量中,所以CGI可以从环境变量来读取数据。这里对环境变量不再赘述,只提提程序中用到的两个非常重要的环境变量:其一是REQUEST_METHOD,它是HTTM请求的模式,即“GET”和“POST”,TSE系统是用的GET模式,index.html定义<form>时里面有一个属性method为get;其二为QUERY_STRING,它就是URL中附加的数据字符串,对应上面的URL的QUERY_STRING为: word=%C7%E5%BB%AA%B4%F3%D1%A7&www=%CB%D1%CB%F7&cdtype=GB,CGI程序需解析这个字符串从中提取出需要的数据(键值对)。
(二)
看到第4节中main函数中获取用户输入部分,定义了一个CQuery类对象,该类为搜索功能的实现类,提供加载数据文件、获取用户输入、中文分词、检索关键词等接口。然后调用了CQuery类的GetInputs函数,该函数就是解析QUERY_STRING并提取出键值对。在看该函数的源代码之前,先看一下CQuery类的定义,主要是其中定义的数据成员。
//LB_c: 结构体HtmlInput_Struct就是用来记录一个键值对
typedef struct {
char Name[MaxNameLength]; //LB_c: 键名
charValue[MaxValueLength]; //LB_c: 键值
}HtmlInput_Struct;
class CQuery
{
public:
string m_sQuery; //LB_c: 存储用户输入的搜索字符串
string m_sSegQuery; //LB_c: 存储中文分词后的用” /”分割的搜索字符串
unsigned m_iStart; //LB_c: 记录用户选择的显示结果集的第几页,默认为第1页
…
}
下面是GetInputs函数的源代码,里面加入了详细的注释解释代码的含义,应该很好理解。
/*
* Get form informationthrought environment varible.
* return 0 if succeed,otherwise exit.
*/
int CQuery::GetInputs()
{
int i,j;
//LB_c: 获取环境变量REQUEST_METHOD, 得到浏览器向服务器提交Http请求是GET模式
// 还是POST模式, TSE系统采用的GET模式
char *mode =getenv("REQUEST_METHOD");
char *tempstr;
char *in_line;
int length;
//LB_c: 返回给浏览器输出的页面(标准输出的内容就会返回给浏览器)
//LB_c: 返回的页面第一行必须是这样,指定了显示的内容为文本类型
cout <<"Content-type: text/html\n\n";
//LB_c: 从这里开始就是页面的html语句了
cout <<"<html>\n";
cout <<"<head>\n";
cout <<"</head>\n";
cout.flush();
//LB_c: http模式为空则无法解析数据,直接返回
if (mode==NULL) return 1;
//LB_c: TSE系统采用"GET模式",这里对"POST模式"的代码不做解释
if (strcmp(mode,"POST") == 0) {
length =atoi(getenv("CONTENT_LENGTH"));
if (length==0 ||length>=256)
return 1;
in_line =(char*)malloc(length + 1);
read(STDIN_FILENO, in_line, length);
in_line[length]='\0';
//LB_c: 判断为"GET模式"
} else if (strcmp(mode,"GET") == 0) {
//LB_c: 通过环境变量QUERY_STRING获取浏览器请求的数据字符串
char* inputstr =getenv("QUERY_STRING");
//LB_c: 数据字符串的长度
length =strlen(inputstr);
if (inputstr==0 ||length>=256)
return 1;
//LB_c: 上面获取的数据存放在inputstr中,而inputstr是局部变量,
// 这里将数据拷贝到in_line中存储。
in_line =(char*)malloc(length + 1);
strcpy(in_line, inputstr);
}
tempstr =(char*)malloc(length + 1);
//LB_c: 这里是分配内存失败的处理: 就是在返回给浏览器的页面中显示提示信息。
//LB_c: 让我觉得奇怪的是,上面的malloc为什么没有分配内存失败的处理;还有前面标准输出用的是cout,
// 这里却用的printf,前后不一致。
if(tempstr == NULL){
printf("<title>Error Occurred</title>\n");
printf("</head><body>\n");
printf("<p>Major failure #1;please notify thewebmaster\n");
printf("</p></body></html>\n");
fflush(stdout);
exit(2);
}
j=0;
//LB_c: 处理数据in_line
for (i=0; i<length;i++)
{
//LB_c: 当前字符为'='则tempstr中的字符串为一个新的键名
if (in_line[i] == '=')
{
//LB_c: 注意字符串结束符
tempstr[j]='\0';
//LB_c: 还原URL形式的字符串到实际的字符串,因为汉字在URL中是用%*%*形式表示的。
CStrFun::Translate(tempstr);
//LB_c: 将新解析的键名存入键值对数组HtmlInputs中
strcpy(HtmlInputs[HtmlInputCount].Name,tempstr);
//LB_c: 如果已经是数据结尾,说明最后一个键值是空的,赋值为""
if (i == length -1)
{
strcpy(HtmlInputs[HtmlInputCount].Value,"");
//LB_c: 键值对计数加1
HtmlInputCount++;
}
j=0;
}
//LB_c: 当前字符为'='则tempstr中的字符串为一个新的键名
else if ((in_line[i]== '&') || (i==length-1))
{
if (i==length-1)
{
if(in_line[i]== '+')tempstr[j]=' ';
elsetempstr[j] = in_line[i];
j++;
}
tempstr[j]='\0';
CStrFun::Translate(tempstr);
//LB_c: 将新解析的键值存入键值对数组HtmlInputs中
strcpy(HtmlInputs[HtmlInputCount].Value,tempstr);
HtmlInputCount++;
j=0;
//LB_c: URL中用'+'表示原数据中的' ',这里进行还原
} else if (in_line[i] == '+') {
tempstr[j]=' ';
j++;
//LB_c: 其他情况将字符
} else {
tempstr[j]=in_line[i];
j++;
}
}
//LB_c: 释放临时变量的内存
if(in_line) free(in_line);
if(tempstr) free(tempstr);
return 0;
}
GetInputs函数解析完QUERY_STRING提取出键值对依次存入HtmlInputs数组中,以上面的QUERY_STRING内容为例,解析完后HtmlInputs的内容如下:
HtmlInputs[0].name = “word” HtmlInputs[0].value= “清华大学”
HtmlInputs[1].name = “www” HtmlInputs[0].value= “搜索”
HtmlInputs[2].name = “cdtype” HtmlInputs[0].value= “GB”
(三)
main函数中获取用户输入部分还调用了两个函数,SetQuery和SetStart,下面进行解释。
void CQuery::SetQuery()
{
string q =HtmlInputs[0].Value;
CStrFun::Str2Lower(q,q.size());
m_sQuery = q;
}
void CQuery::SetStart()
{
m_iStart =atoi(HtmlInputs[1].Value);
}
首先,SetQuery函数是从键值对数组HtmlInputs获得用户输入的搜索字符串(HtmlInputs[0].Value)存入数据成员m_sQuery。
第二,SetStart函数是设置显示搜索结果集的第几页(因为搜索的结果网页可能很多,一页无法全部显示,需要分页,用户可以选择显示结果的第几页,如图1所示),该函数将用户选择的页号设置到数据成员m_iStart,在显示搜索结果的时候将根据该页号进行显示。但是这里显然有问题,当用户从首页进行搜索时显示的搜索结果网页有问题,如图1所示,一共搜索到114条结果,但是线面显示的却是空的。因为HtmlInputs[1].Value根本就不是用户选择的页号,上面分析了HtmlInputs[1]对应搜索按钮,所以存储的是按钮的值“搜索”,所以将atoi("搜索")赋值给了m_iStart,导致m_iStart是个错误的值!如果用户从搜索结果页面中进行新的搜索或者选择显示搜索结果的第几页时,显示的结果是正常的,就是因为这个m_iStart的值的问题,后面介绍“显示搜索结果”一节时将继续分析。
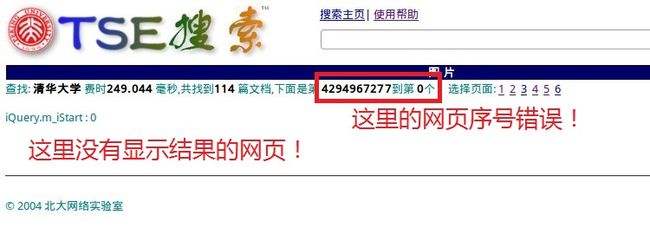
图1
为什么原作者会写这样的代码呢?也是有原因的。因为,当用户在搜索结果页面中进行新的搜索或者选择显示搜索结果的第几页时,提交的URL的第二个键值对确实是页号(后面分析“显示搜索结果”部分时还将详细说明),该键值对的键名为"start",这种情况下是可以获取HtmlInputs[1].Value赋值给m_iStart。所以设置m_iStart时需要判断键名是不是为"start"。这里我对该函数进行了如下的修改,判断HtmlInputs[1]中存储的是不是“start”的键值对,如果是则修改m_iStart,否则设置成默认值1。
void CQuery::SetStart()
{
if (strcmp(HtmlInputs[1].Name, "start") == 0) {
m_iStart =atoi(HtmlInputs[1].Value);
} else {
m_iStart = 1; //LB_c: 如果URL中没有页号值则设置默认值(默认显示结果的第一页)
}
}
By:
