【北大天网搜索引擎TSE学习笔记】第7节——中文分词
这一节将介绍搜索功能入口程序TSESearch.cpp的第三步——中文分词。
(一)引子
中文分词主要有基于字符串匹配的分词方法和基于统计的分词方法,基于字符串匹配的方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词),所以该方法是基于词典的,需要一个充分大的且准且的词典。TSE中就是用的基于字符串匹配的分词方法。基于统计的分词方法在这里不做介绍,感兴趣的读者可以查看相关资料。
机械分词方法根据不同的规则和策略有不同的中类,常用的机械分词方法有:正向最大匹配、逆向最大匹配、最少切分和双向最大匹配法。TSE中采用的就是正向最大匹配。关于该算法,这里也不再叙述,《搜索》一书中有很详细的介绍,网上也有非常多的资料,读者可以自己查阅。下面开始分析源代码。
(二)代码分析
看到第4节中main函数中中文分词部分,首先定义了一个CHzSeg类的对象,然后调用了该类的SegmentSentenceMM函数。中文分词的程序文件和数据文件都在./ChSeg目录中,看到./ChSeg/HzSeg.cpp文件,里面有两个关键的函数:SegmentSentenceMM和SegmentHzStrMM。原始的字符串中可能包含英文字符(ASCII字符)、中文特殊字符或者中文标点符号等,SegmentSentenceMM函数先过滤掉这些符号,将剩余的汉字字符串将交给SegmentHzStrMM函数进行中文分词。所以,SegmentSentenceMM是进行分词的调用接口,也可以说是中文分词预处理函数,而SegmentHzStrMM是中文分词算法的实现函数。下面看这两个函数的源代码,代码中加入了详细的注释(以“LB_C”开始的注释为我加入的)进行说明。
//LB_c: 中文分词预处理函数,过滤英文字符(ASCII字符)、特殊字符、中文标点符号等,将预处理后得到的汉字字符串交给 // SegmentHzStrMM函数进行中文分词。参数dict为词典对象,s1为待处理的字符串。 // process a sentence before segmentation string CHzSeg::SegmentSentenceMM (CDict &dict, string s1) const { //LB_c: s2保存处理过程中得到的已处理的串 string s2=""; unsigned int i,len; //LB_c: 循环读取s1中的某一个字节进行处理,直到s1为空 while (!s1.empty()) { //LB_c: 取s1的第一个字节,注意这里ch的类型限定符为unsigned,因为汉字的每个字节的值大于128 unsigned char ch=(unsigned char) s1[0]; //LB_c: ch<128说明ch是一个ASCII字符,这部分过滤ASCII字符 if(ch<128) { // deal with ASCII i=1; len = s1.size(); //LB_c: s1[i]为不是换行(LF)和回车(CR)的ASCII字符则i++,也就是i记录了连续的非LF和CR的ASCII字符的个数。 while (i<len && ((unsigned char)s1[i]<128) && (s1[i]!=10) && (s1[i]!=13)) { // LF, CR i++; } //LB_c: 如果ch不是LF、CR和SP(空格),则在第i个字节处插入以分割符SEPARATOR(源码中定义为"/ "),这里的处理应 // 该是有问题的,在后面我将进行分析。 if ((ch!=32) && (ch!=10) && (ch!=13)) {// SP, LF, CR s2 += s1.substr(0, i) + SEPARATOR; } else { //LB_c: 如果ch为LF或CR,则将s1[0]开始的i个字节数据拷贝倒已处理串s2,即这里不插入分割符进行切分,这里也 // 很明显存在问题,就是当ch=SP时什么也不处理,那么这段字符将丢弃,在后面进行分析。 if (ch==10 || ch==13){ s2+=s1.substr(0, i); } } //LB_c: 如果s1没有处理完,则将s1赋值为剩余的字符串 if (i <= s1.size()) // added by yhf s1=s1.substr(i); else break; // yhf continue; //LB_c: else中ch为非ASCII字符,即中文GBK字符。 //LB_c: 这里完全可以写成else if (ch < 176),费解! } else { //LB_c: ch<176说明是中文标点或其他中文符号,GBK汉字是从176往上开始编码的,也就是所有的首字节都是大于176。大 // 家可以查GBK的编码表。所以这部分是处理中文标点和中文特殊符号的。 if (ch<176) { i = 0; len = s1.length(); //LB_c: GBK中首字节值大于等于161且小于176,是中文标点符号和其他特殊符号。下面这个while循环就是过滤掉这 // 些特殊符号,如果遇到的是中文标点符号则停止,也就是特殊符号不需要切分,而中文标点符号需要切分。while // 条件中的取值就是这些标点符号的GBK编码值,可以查询GBK编码表对照。 while(i<len && ((unsigned char)s1[i]<176) && ((unsigned char)s1[i]>=161) //LB_c: ch不为中文标点符号:、 。 · ˉ ˇ ¨ 〃 && (!((unsigned char)s1[i]==161 && ((unsigned char)s1[i+1]>=162 && (unsigned char)s1[i+1]<=168))) //LB_c: ch不为中文标点符号:~ ‖ … ‘ ’“ ” 〔 〕 〈 〉 《 》 「 」 『 〗 && (!((unsigned char)s1[i]==161 && ((unsigned char)s1[i+1]>=171 && (unsigned char)s1[i+1]<=191))) //LB_c: ch不为中文标点符号:,!( ): ;? && (!((unsigned char)s1[i]==163 && ((unsigned char)s1[i+1]==172 || (unsigned char)s1[i+1]==161) || (unsigned char)s1[i+1]==168 || (unsigned char)s1[i+1]==169 || (unsigned char)s1[i+1]==186 || (unsigned char)s1[i+1]==187 || (unsigned char)s1[i+1]==191))) { i=i+2; // 假定没有半个汉字 } if (i==0) i=i+2; //LB_c: 如果ch不是中文空格,则在s1的第i个字节处插入分割符切分,如果是中文空格则部切分。这里显然也是存在 // 问题的,后面进行分析。 if (!(ch==161 && (unsigned char)s1[1]==161)) { if (i <= s1.size()) // yhf // 其他的非汉字双字节字符可能连续输出 s2 += s1.substr(0, i) + SEPARATOR; else break; // yhf } //LB_c: 如果s1没有处理完,则将s1赋值为剩余的字符串 if (i <= s1.size()) // yhf s1=s1.substr(i); else break; //yhf continue; } } //LB_c: ch的取值除了上面的情况就是汉字了,即ch>=176为汉字编码以下处理汉字串 i = 2; len = s1.length(); //LB_c: 查找连续的汉字串,while循环直到遇到某两个字节不是汉字停止 while(i<len && (unsigned char)s1[i]>=176) i+=2; //LB_c: 上一步找到了一个连续的汉字串s1(0,i),这里调用中文分词函数SegmentHzStrMM进行中文分词。 s2+=SegmentHzStrMM(dict, s1.substr(0,i)); //LB_c: 如果s1没有处理完,则将s1赋值为剩余的字符串 if (i <= len) // yhf s1=s1.substr(i); else break; // yhf } //LB_c: 处理结束以后,s2中存储的便是分割后的结果,中间以分割符("/ ")隔开。 return s2; } //LB_c: 正向最大匹配法的中文分词实现,dict是分词所查询的词典对象,s1是中文字符串。 //LB_c: using Max-matching-method to segment the string s1 with dictory dict. // Using Max Matching method to segment a character string. string CHzSeg::SegmentHzStrMM (CDict &dict, string s1) const { string s2=""; // store segment result while (!s1.empty()) { unsigned int len=s1.size(); //LB_c: MAX_WORD_LENGHT为设置的最大词长,TSE中设置为8个字节,即4个汉字 if (len>MAX_WORD_LENGTH) len=MAX_WORD_LENGTH; //LB_c: 从s1头部取最大词长的子串作为待匹配词(如果是逆序最大匹配法则从s1的尾部取) string w=s1.substr(0, len);// the candidate word //LB_c: 在词典中查询w是否存在,CDict::IsWord函数判断字符串是否在词典中。在一个庞大的词典中查找词的效率是很关键 // 的,这是影响该系统效率的一个因素之一,第5节中介绍过,TSE中的词典是用STL的map结构存储的,也就是红黑树的数据结 // 构存储,而有的分词系统也用hash表存储,都是为了提高查询效率。 bool isw=dict.IsWord(w); //LB_c: 如果在词典中没有找到则去掉最后一个字继续查询,直到w为一个单字为止。 while (len>2 && isw==false) { // if not a word len-=2; // cut a word w=w.substr(0, len); isw=dict.IsWord(w); } //LB_c: 在匹配词w后加入分割符SEPARATOR进行分割。 s2 += w + SEPARATOR; s1 = s1.substr(w.size()); } return s2; }
(三)问题分析
上面的代码中提到几处是有问题的,下面进行分析。
先说说29-34行的问题。在29行中如果ch不为LF、CR和SP则插入分隔符后拷贝到以处理串s2,34行中如果ch为LF、CR则不插入分隔符直接拷贝到s2,假如ch=SP(空格)的话怎样处理呢?显然什么也没做,也就把已分析的部分字(s[0]-s[i-1])符丢掉了。举个例子:s1=" love搜索“(注意love前面有一个空格字符),分词后的结果是s2=”搜索“,把前面的" love"丢掉了。
再说说78-83行的问题。这部分代码的意思是,如果s[0]s[1]不是中文空格,且s1没有分析结束,则在第i个字节处插入分隔符,如果s[0]s[1]是中文空格,则什么也不处理,也就是把已分析的部分字(s[0]-s[i-1])符丢掉了,举个例子:s1=" ㄝㄝㄝ搜索"(都是GBK编码的中文字符,"ㄝ"中文状态的特殊字符,最前面有一个中文空格),分词后的结果是s2="搜索";如果s1="ㄝㄝㄝ搜索",由于前两个字节不是中文空格,所以会插入分隔符,分词后的结果是s2="ㄝㄝㄝ/ 搜索"。
总的来说,就是当搜索字符串以空格开始时,空格后面跟着的同状态(即同是ASCII字符或同是GBK字符)的非汉子串会丢掉,如上面例子中的"love"和"ㄝㄝㄝ"。这显然不符合用户的需求,如用户想搜索“love清华大学”,而输入时前面有一个空格即“ love清华大学”,分词结果是“清华大学”,因此只对”清华大学“进行查询,而不对love进行查询。TSE搜索的结果如图1所示。
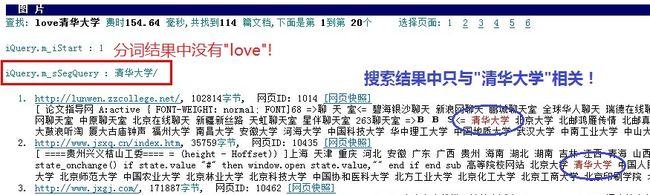
图1
文章http://www.52nlp.cn/maximum-matching-method-of-chinese-word-segmentation中指出29-34行的代码漏掉了ch==32(如图2所示)。

图2
这样其实也是不对的,而且问题会更加严重。代码的意思是:如果ch==32,则将s1[0]开始的i个字节数据拷贝倒已处理串s2,即不进行切分。例如s1=" love搜索“(注意love前面有一个空格字符),则这样分词后的结果是s2=”love搜索“,在倒排表中检索关键词时会去查找”abc搜索“,显然找到的几率是很低的,因为把"love"和"搜索"当成了一个词。TSE中搜索的结果就是0,如图3所示。
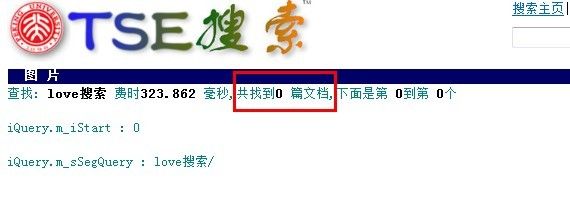
图3
这里的处理也是我的一个疑惑之处,分析到s1的第i个字节时是否要插入分隔符,为什么要看s1[0]的取值呢?例如分析s1=”love搜索“,分析到'e'时遇到汉字,此时为什么要看s1[0]是不是LF、CR和SP来决定是不是要出入分隔符呢?这里应该直接插入分隔符就可以吧!不明白作者的真实意图,希望有理解的读者请解释一下!
By:
