Mahout并行频繁集挖掘算法源码分析--读取最后结果
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
本来打算分析Parallel Frequent Pattern Mining算法的源码的,但是看到之前的blog感觉这个算法好像分析的比较详细了,所以这里就不再进行分析了,只写个最后读取结果频繁项集序列文件的代码好了:
下面的代码可以自己编写getRegex函数,来对输出的TopKStringPatterns进行解析,下面代码中使用了两种方式,其一是直接打印,其二是删除自相关的项目进行打印;当然还可以自己编写解析函数;
输出是在HDFS文件系统上面的,自己指定目录;
package mahout.fansy.fpg;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.common.HadoopUtil;
import org.apache.mahout.fpm.pfpgrowth.convertors.string.TopKStringPatterns;
import mahout.fansy.utils.read.ReadArbiKV;
public class ReadFrequentPatterns {
/**
* 读取fp算法最后的输出
* 由于其是序列文件,所以要设置为字符串才比较清晰看到
* 首先读取序列文件到一个map中,
* 然后读取map值,把key和value都设置成字符串的形式输出到HDFS文件
* @throws IOException
*/
public static void main(String[] args) throws IOException {
String path="hdfs://ubuntu:9000/fpg/output/frequentpatterns/part-r-00000";
String outpath="hdfs://ubuntu:9000/fpg/output/re/03";
String jobtracker ="ubuntu:9001";
Map<Writable, Writable> map=read(path);
boolean flag=write(regex(map),outpath,jobtracker);
System.out.println("job success ?..."+flag);
}
/*
* 读取序列文件到变量中
*/
public static Map<Writable, Writable> read(String path) throws IOException{
return ReadArbiKV.readFromFile(path);
}
/*
* 把解析后的key、value写入到文件
*/
public static boolean write(Map<Text, Text> map,String outpath,String jobtracker) throws IOException{
boolean flag=true;
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", jobtracker);
HadoopUtil.delete(conf, new Path(outpath));
FileSystem fs = FileSystem.get(URI.create(outpath), conf);
Path path = new Path(outpath);
FSDataOutputStream out = fs.create(path);
Iterator<Entry<Text, Text>> iter = map.entrySet().iterator();
try {
while (iter.hasNext()) {
Map.Entry<Text, Text> entry = iter.next();
Text key_ = (Text) entry.getKey();
Text val_ = (Text) entry.getValue();
//out.writeUTF(key_.toString()+"\t"+val_.toString()+"\n");
out.writeChars(key_.toString()+"\t"+val_.toString()+"\n");
}
}catch(Exception e){
flag=false;
e.printStackTrace();
}finally {
out.close();
}
return flag;
}
public static Map<Text, Text> regex(Map<Writable, Writable> map){
Iterator<Entry<Writable, Writable>> iter = map.entrySet().iterator();
Map<Text ,Text> out=new HashMap<Text,Text>();
while (iter.hasNext()) {
Map.Entry<Writable,Writable> entry = iter.next();
Text key = (Text) entry.getKey();
TopKStringPatterns val = (TopKStringPatterns) entry.getValue();
String value=getRegex_2(val);
if("".equals(value)||value==null){
}else{
out.put(key, new Text(value));
}
}
return out;
}
/*
* 解析 TopKStringPatterns
* 方式一:直接打印
*/
private static String getRegex(TopKStringPatterns val) {
return val.toString();
}
/*
* 解析 TopKStringPatterns
* 方式二:去掉自相关的项目
*/
private static String getRegex_2(TopKStringPatterns val) {
String temp=val.toString();
if(val.getPatterns().size()==1){
return "";
}else{
int b=temp.indexOf(")");
return temp.substring(b+2,temp.length());
}
}
}
其中写入到HDFS可以使用writeChars和wirteUTF函数,但是后者会出现乱码,如下图:
原始直接打印(使用writeUTF函数,有乱码有自相关项目):
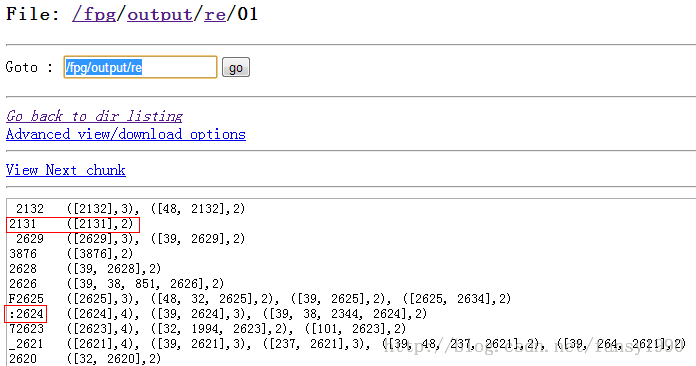
去掉自相关项目(使用writeUTF):
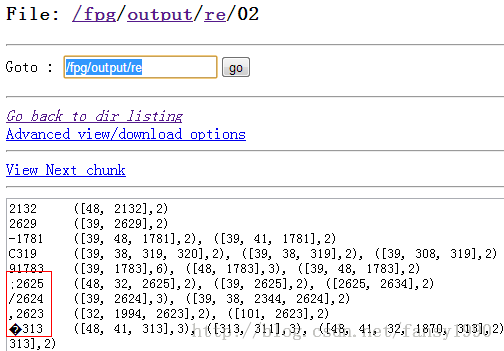
去掉自相关项目(使用writeChars函数):
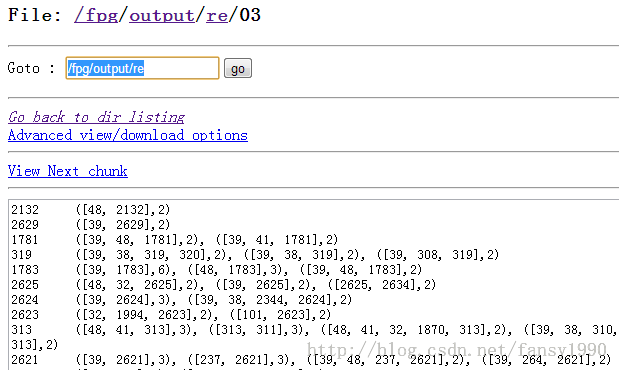
但是writeChars函数输出数据文件会比较大:

分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990