文章来自《程序员》
英文原文可以在这里找到http://dev.csdn.net/develop/article/12/12657.shtm
关键字:WWW 搜索引擎 网络爬虫 PageRank Google
作为一种功能强大的搜索引擎,Googic的背后似乎隐藏着巨大的奥秘,本文是Googic的两位创始人在1998年国际互联网大会上发表的论文,通过对Google进行完整地剖析,帮助读者理解Google的实现过程.
1。为什么要用Google
Web结构的特殊性为信息收集工作带来了新的挑战。Web上的信息数量迅速增长的同时,对于Web毫无使用经验的新用户也在与日俱增。使用高质量的搜索引擎,无疑可以缩短Web同新用户之间的距离。大家关心的问题是,搜索质量和效率。
Yahoo曾一度是用户的最佳选择。Yahoo的人工维护方式可以有效涵盖最流行的主题。然而,维护人员的主观性、高昂的维护代价、较慢的更新速度都是Yahoo的缺陷。更重要的事,这种方式并不能覆盖所有用户所关心的话题。所有这些制约了Yahoo的进一步发展。基于关键字的搜索引擎随之出现,但新的问题接踵而来:搜索引擎制造出的大量“垃圾”结果遮住了用户的视线,也考验了更多人的耐心。一些广告商为了吸引用户的目光,采用一些手段欺骗搜索引擎,这使事情变得更糟。
Google为上述问题提供了新的解决方案。首先,Google是基于关键字的,这样突破了查询主题的限制;其次,Google利用网页超级连接的深度和独创的PageRank算法,为网页赋予了“级别(Rank)”含义:用户的检索结果,是按照网页的级别(Rank)进行排序的.级别高的网页链接排在前面.
Google这个名字的来历也很有意思:Google的创建者参考了单词googol(10100)的拼写,也许这和作者要建立大规模的搜索引擎的目标不谋而合.
2.设计目标
正如你想到的,GOOGLE的主要目标是提高搜索引擎的搜索质量和易用性.1997年11月的一项调查中,排名前四位的商业化搜索引擎,在执行以它自身的名字作为关键字的查询时,仅有一个搜索引擎在其搜索结果的前10条查询结果中找到自己.问题已经变得很明显:用户关心的不是搜索引擎所能提供的查询结果,而是在搜索引擎中所能提供的前数十条查询结果中,能否找到自己的满意答案.正因为如此,当Web文档成倍增长时,如何提供一个既易于操作,又能提供准确查询的新的搜索引擎技术.这成为了关注的焦点.
近几年的一些相关研究为Google打开了思路.这些研究的主要方向是:如何从页面的超链接文本中获取对开发人员有用的信息.正是通过对HTML文档中超文本链接的深度分析,Google为自己的精确度算法提供了理论依据.
Google希望通过自己的努力,把原本只属于商业领域的搜索引擎技术带到理论研究的范畴,并能让更多的人参与和完善.Google把自己的系统比喻为一个大的实验室环境,并欢迎其他领域的研究人员参与其中.正是在千千万万如Google这样的组织的带动下,Web获取了它前所未有的发展动力.
3.技术分析
Google之所以能获取高效率的查询结果,得益于其两相重要的技术特性:第一,Google分析整个Web的链接结构,然后计算出每一个网页的级别,并进行综合评分,这就是Google所采用的PageRank技术;第二,Google充分利用链接提供的信息以进一步改善查询质量.
3.1 PageRank:页面的排序技术
Google的核心技术称为PageRank,这是Google的创始人Larry Page和Sergey Brin在斯坦福大学开发出的一套用于网页评级的系统.作为组织管理工具,PageRank利用了互联网独特的明主特性及其巨大的链接结构.在浩瀚的链接资源中,Google提取出上亿个超级链接进行分析,制作出一个巨大的网络地图(Map).依据此地图,PageRank技术能够快速的计算出网页的级别(Rank).这个级别的依据是:当从网页A连接到网页B时,Google就认为"网页A投了网页B一票".Google根据网页的得票数评定其重要性.然而,除了考虑网页得票数(即链接)的纯数量之外,Google还要分析投票的网页。“重要”的网页所投出的票就会有更高的权重,并且有助于提高其他网页的“重要性”。
Google以其复杂而全面自动的搜索方法排除了人为因素对搜索结果的影响。所以说,PageRank相对是公平的。在这个意义上,对于基于关键字搜索的引擎技术来说,PageRank无疑是一项优秀的技术,Google可以方便、诚实、客观地帮您在网页上找到任何有价值的资料。
3.1.1 PageRank算法描述
近些年来,大量的学术研究成果被应用到Web中,主要被用来统计网页的引用或返回链接。这些数据为网页的重要性和价值分析提供了粗略的依据。基于此, PageRank还进一步统计链接在所有网页中出现的次数。PageRank定义如下所述:
假定页面A有很多指向他的链接,分别定义为页面T1...Tn。我们再定义阻尼系数d(0〈=d〈=1)。通常指定d=0.85(译者注:下一节给出实例分析)。函数C(A)表示页面A中指向其他页面的链接的个数。那么,页面A的PageRank(PR(A))可以通过下面的公式计算出:
PR(A)=(1-d)+d(PR(T1)/C(T1)+...PR(Tn)/c(Tn))
注意到PageRank的值是通过整个Web计算出来的,所以,所有页面的PageRank值的和必然为1。
通过简单的递归计算,并参照Web中规范型链接矩阵的主特征向量,我们就可以计算出一个页面的PageRank(PR(A))。假设计算大约26,000,000个页面的PageRank,使用一台中等规模的工作站,大约需要数个小时的时间。具体实现的细节已经超出文本的讨论范围,读者可以参考相关文档。
3.1.2 PageRank模型
为了更好地理解 PageRank,我们建立以下一个假想的模型。我们假定有一个Web用户正在随机浏览某个网页,随着兴趣的变化,他也可能随机点击页面中的另一个链接,跳转到其他页面(暂且假定该用户没有使用返回按钮)。在这个模型中,吸引用户点击指向某个页面的链接的概率就是页面的PageRank。而由于某些因素导致用户选择了其他链接的概率就是该页面的阻尼系数d。有一些极端的情况,如有些页面可能很少被人访问,这些页面就会积累起很高的阻尼系数。所以说,PageRank的技术可以公平有效到避免有些系统为了获取较高级别而采取一些欺骗搜索引擎的行为。
一般来说。网页的链接指向越多,PageRank的值就会越高。同样,被一些“重量级”的网站(例如yahoo)引用的次数越多,PageRank的值同样也会很高。相反,那些设计不佳,或者被链接破坏指向的网页,将逐渐被用户所遗忘。所有的这些因素都在PageRank技术的综合考虑之中。
3.2锚文本(anchor text)
在Google中,链接文本(text of link )被使用一种特殊的方式进行处理。大多数的搜索引擎都是把链接文本和它所在的页面相关联,而Google则把链接文本和它指向的文档联系到一起(想想的确应该如此)。这样做的优点很多:首先,锚(anchor )一般都会提供它所指向的文档的准确的描述,而这样信息,页面本身往往不能提供;第二,对于那些不能被基于文本的搜索引擎建立索引的文档,例如图象,程序以及数据库等,指向它们的链接却可能存在,这样就使得那些不能被引擎取回分析的文档也能作为查询结果返回。但是,这样做也可能会引起一些问题,因为这些文档在返回给用户之前并未经过搜索引擎的有效性检查。在这种情况下,搜索引擎就可以简单地返回查询结果,甚至不用考虑页面是否存在,而只管是否有指向它们的超级链接存在。也许你会问,这合适吗?不用担心,由于查询结果是经过级别排序输出的,这种特殊的情况也许根本看不到。
其实,这种使用锚文本技术的思想更早可以追溯到World Wide Web Worm搜索引擎。它使得WWWW可以检索到非文本信息,甚至扩展到一些可以下载的文档,Google继承了这种思路,因为它可以帮助提供更好的搜索结果。然而,使用这种技术需要克服很多的技术难题,首当其冲的就是如何处理如此庞大的数据量。我们来看看一组数据,在Google爬虫取回的24,000,000个网页数据中,需要处理的链接数高达259,000,000之多。
3.3其它功能
除了PageRank和锚文本技术之外,Google还有一些其它的技术。首先,对于所有命中(hits),Google都记录了单词在文档中的位置信息,这些信息在最终的查询中可以被用来进行单词的相似度分析。第二,Google还记录了页面中的字体大小、大小写等视觉信息。有的时候,大号字体和粗体的设置可以用来表示一些重要的信息。第三,在repository数据库中保存所有页面的HTML代码。
(译注:命中(hit)是Google定义的一个数据结构,有关命中和相似度的描述,详见下文。)
4.系统剖析
从上文中,我们已经了解Google的一些工作原理。在这一章节中,我们将一起深入探讨Google的体系框架,然后具体介绍Google用到的一些数据结构。最后,我们再一起分析Google用到的三个关键技术:网页抓取(crawling)、索引(indexing)以及基于关键字的搜索(searching)。
4.1 Google体系框架
本节中,我们共同探讨Google体系框架的运行流程,如图1所示。下面的几个章节将详细的介绍所用到的技术和数据结构。考虑到执行效率,Google 中的大部分代码都是用C/C++语言实现的,并且可以同时运行在Solaris和Linux系统中。
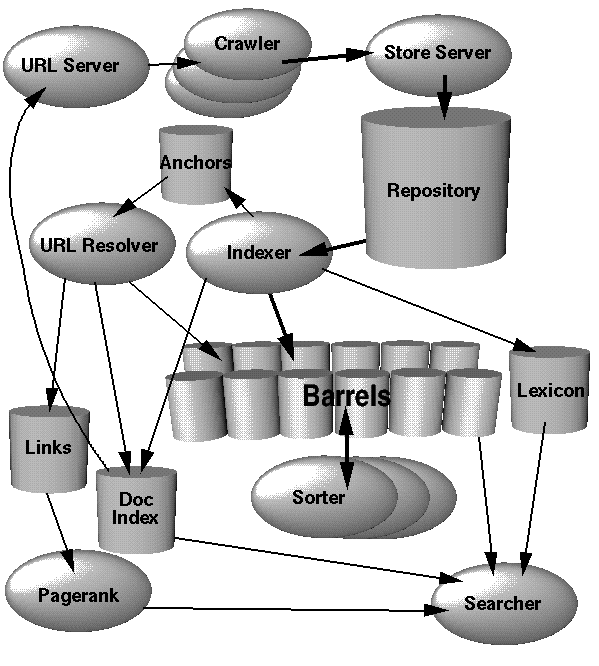 图1
图1
在Google的体系框架中,网页爬行技术(Crawling,指网页的下载过程)是由若干个分布式的网络爬虫(Crawler)软件实现的。其中,一个叫做URL Server的服务器负责把需要分析的URL地址列表分派给这些网络爬虫进行处理。网页数据如果被取回,将立即被送到Store Server中。Store Server对网页数据进行压缩,然后保存到Repository数据库中。每一个文档都拥有一个与之相关的唯一的ID编号,Google称它为docID。每当有一个新的链接从页面中被解析(parse)出来,它所指向的文档就将自动获得一个docID。建立索引的任务则交给索引器(Indexer)和排序器(Sorter)来完成。Indexer依次从Repository中取出文档,对文档解压缩,然后对文档进行解析。随后文档被解析为一组命中。在Google中,命中(hit)是一种数据结构,用来记录单词在文中每一次出现的信息。在命中结构中,记录了每个词(word)、词在页面中的位置、大小写、字体相对大小等信息。这样,每个词都有很多不同的命中,这些命中的组合又称为该词的命中列表(hit list)。索引器把这些命中再写入到一组桶(barrel) 中,并建立一个部分排序的前叙索引(foward index)。索引器还同时把网页中所有的链接的重要信息解析出来,并记录到一个叫做Anchors的文件中。该文件包含了足够多的信息,从中可以查询出每一个链接的来源、指向以及该链接的文本。
(译注:索引器还把解析出的词写入到一个词典(Lexicon中,这将在下文中提到。)
URL Resolver服务器负责从 Anchors文件中读取这些链接,把相对路径改为绝对路径,再转换为相应的 docID。通过docID的关联,锚文本的信息也被加入到前序索引的anchor hit结构中。URL Resolver同时创建了一个Links数据库,用来存放两两对应的docID。Links数据库被用来计算所有文档的PagePank 。
接着排序器接管过这些桶。如前所述,这些桶已经按照 docID进行了排序。排序器的主要任务是按照WordID重新进行排序,从而为这些桶生成一个倒排索引(inverted index)。这个操作是在每个桶中执行的,所以只需要用到很少的临时空间。排序器还建立了一个WordID列表,列表中同时记录了该WordID在倒排索引中的偏移量大小。有一个叫做DumpLexicon的工具,用来把wordID和上文中提到的由索引器产生的词典(Lexicon)相结合,并产生一个新的词典。这个新的词典被用在最终的搜索程序中,连同PageRank和倒排序索引一起,为用户提供查询服务。
4.2 数据结构
Google对数据结构进行了很多优化,其目的主要是为了有效的减少在处理大文档的抓取、索引以及查询时所需要耗费的成本。虽然这些年来计算机的性能得到了很大的改善,但对于磁盘的检索仍然需要大约10ms的时间来完成。基于性能的考虑,Google尽可能地避免使用磁盘操作,而这个想法也很大的影响了数据结构的设计思路。
4.2.1 巨型文件(BigFile)
巨型文件(BigFile)被设计成为跨越多文件系统地、64位地址空间的虚拟文件,并能够在多文件系统中自动进行文件分配。因为操作系统不能为我们提供有用的支持,巨型文件包(BigFile package)被设计用来负责操作文件描述符的创建和销毁。另外,巨型文件也支持一些初步的压缩喧响。
4.2.2 数据仓库(Repository)
数据仓库(Repository)中保存了每一个网页完整的HTML代码。为了节省空间,页面在存储前使用zlib技术进行了压缩。压缩技术的选择综合考虑了速度和压缩比的因素。尽管bzip技术在压缩比方面技高一筹(压缩比达到了4:1),Google还是基于速度的考虑最终选择了zlib(压缩比只有3:1)。文档记录在数据仓库中顺序排列,并以docID、length、URL等作为文档记录的前缀,如图2所示。数据仓库的访问不需要使用任何其他的数据结构,这样有助于保持数据的完整性,并且使得开发变得更为容易。
 图2
图2
4.2.3 文档索引(Document Index)
文档索引(Document Index)用来跟踪每一个文档的信息。它是一种定宽的ISAM(Index sequential access mode)类型的索引,并按照文档的docID进行了排序。索引中的每一项存储了当前文档的状态、指向数据仓库的指针、文档校验和,以及一些统计信息。如果文档被爬虫取回,则该索引项还将包含一个指向docinfo文件的指针。docinfo文件包含该文档的URL和标题;否则,这个指针就被指向一个仅包含一种比较紧凑的数据结构,以及在一次搜索操作中查找一条磁盘记录的执行效率。
另外,在转换URLs到docIDs时需要用到一个文件。这个文件其实是一个包含URL校验和(checksum)和与它对应的docID的列表,并且按照checksum进行排序。通常,我们需要根据URL来查找文档的docID。这时,首先计算出该URL的校验和(checksum)进行二进制的检索,然后根据检索结果找到其所对应的docID。其实,URL Resolver正是使用这个办法把URL转换为docID的。在这里使用批处理模式很有必要,否则对于包含322,000,000各链接的数据集来说,要检索所有的链接至少得耗费数月之久。
4.2.4 词典 (Lexicon)
词典有好几种不同的格式.随着内存成本的下降,现在可以实现把词典嵌入到内存中运行,这将可以大大提高运行的效率.在一个256M电脑的内存中,可以运行一个包含14,000,000个词汇的词典。词典由两部分来实现:一个词列表(彼此之间以Null分隔)和一个包含指针的哈希表.
4.2.5 命中列表(Hit Lists)
命中列表(hit list)对应于某个特定的词在某个特定的文档中一次或多次的出现,它主要用来记录词在文中出现的位置、字体、大小写等信息。命中列表在前序索引和倒排索引中都占据了绝大部分的空间。因此,命中列表需要尽可能地以一种高效率的方式来实现。有几个可以用来参考的编码方案:一个是简单编码方式(三位整数法),第二是压缩编码方式(对位的分配进行手工优化),最后一种是有名的霍夫曼编码方式。Google在权衡了空间的占用量以及对于位操作的复杂性之后,选择了第二种压缩编码方案。命中的实现细节,参见图3
图3。
在这种压缩编码中,每个命中占用2个字节的空间。命中又可细分为两种类型:特殊命中(fancy hit)和普通命中(plain hit)。特殊命中(fancy hit)是指出现在URL、页面标题、锚文本或者meta标签中的命中,除此之外的全部命中都是普通命中(plain hit)。普通命中(plain hit)包含标识大小写的位(1位)、字体大小位、以及12位的为之心系(如果在文档中的位置大于4095,则一律以4096表示)。字体大小是字体在文档中的相对大小,用3位来表示。字体大小只使用从000到110这七个数,111被用来单独表示一个特殊命中(fancy hit)。特殊命中(fancy hit)也包含一个大小写的位(1位)、字体大小(设为7=111)、4位的类型编码、以及8位的位置信息。对于出现在锚文本的命中(anchor hit)来说,8位的位置信息又细分为锚中的位置信息(4位)以及锚所在的文档docID的hash值(4位)。这样,在针对某些特定的词进行查询时,如果找不到足够的链接匹配,就可以从这些anchor hit中找一些来补充。以后,考虑到对于位置信息和docID的哈希值哈还会有更多的解决方案,anchor hit的存储方式将会有所改变。另外,Google之所以使用字体的相对大小,主要是考虑到在对文档计算级别时,我们不能仅仅因为A文档使用了较大的字体就说A文档比B文档级别高。
命中列表的长度保存在命中列表的前面。为了节省空间,采用了一些特殊的技巧,从前序索引的worldID自段和后排索引的docID字段中分别压缩出8位和5位空间,用来存储该长度值。如果长度值出现溢出,这些位将使用一个溢出符表示,并在紧接着的下两个字节中包含实际的长度值。
4.2.6 前序索引 (Forward index)
前序索引实际已经经过部分排序。它由许多个桶组成,每个桶中保存一定范围的wordID。如果某篇文档中词对应到某个桶中的wordID,该文档的wordID也会被记录到该桶中。每个docID后面紧跟着一个属于它的wordID列表,而这些列表中每个wordID的后面又紧跟着该word的命中列表。
因为大量重复docID的存在,这种存储方案也许会带来更大的空间需求。但是由于索引被分散在许多个桶中,而且这种设计在最后由排序器执行的短语索引操作中可以合理地节省时间上的开销,并降低了编程的复杂度,所以,空间上的这点浪费是完全可以容忍的。而且,wordID中存储的实际上是WordID与其所在的桶中的WordID最小值之间计算出来的相对差。这样,WordID就只需要24位来存储,余下的8位恰好可以被用来存储命中列表中的长度(参见上文)。
4.2.7倒排索引(Inverted Index)
和前序索引一样,到排索引也是由同一组桶所组成,只是这些桶经过了排序器的进一步处理。对于每一个有效的WordID,词典中都会有一个指向包含该WordID的桶的指针。这个指针指向一个docID的列表(doclist),列表中的每一项都由docID和该WordID的命中列表组成。该WordID所在的所有的文档的docID都包含在该doclist中.
一个重要的问题是,doclit列表中的docID应该如何排序?一个比较简单的解决方案是直接根据docID排序。这种方案在对多字词的复合查询时,可以实现多个doclist之间的快速归并(merge)操作。另外一个复杂一点的方案,是按照word在每篇文挡中出现的级别进行排序。
这种放案对于单字词的查询作用不大,但对于多字词的查询,可以实现把最近的查询结果排到前面。两种方案各有自己的不足。首先,归并操作具有一定的难度;而级别计算函数的每一次改变都可能需要对索引进行重建,着无疑会给开发工作增加新的难度。所以,有必要采取一种折中的方案。在这个方案中,保持两组排序的桶,其中一组用来包含在标题或锚文本中出现的命中列表,另一组则包含所有的命中列表。首先,查询第一组桶(short barrel)中进行;如果找不到足够的匹配,则转到另一组桶(full barrel)中继续查找。
4.3 Web爬行技术(Crawling the Web)
事实上,在Web上运行一个网络爬虫(crawler)的工作颇具挑战性。这不仅兼顾棘手的性能和可靠性因素之外,更重要的,还需要考虑一些社会因素。由于需要实时的和成千上万台状态不可控的Web服务器进行交互,Web爬行技术也极容易崩溃。
为了更好的适应Web上数以千亿的网页数量,Google采用了一种分布式的Web爬行系统,由于URL server负责把URL需求提交给若干个爬虫软件进行处理。需要说明的是,URLServer以及爬虫都是用Python语言实现的。每个爬虫一次可以同时打开大约300个连接线程,这样,网页爬行足以保持一个足够快的进度。假如使用4个crawler,系统就可以实现最快每秒抓取超过100个页面,也就是大约600k/秒的数据流。性能上的影响主要来自对于DNS(域名服务)的查询,因此,每个爬虫都配有一个单独的DNS高速cache,这样可以有效的避免影响效率的DNS查询。爬虫拥有的线程分为下列几种状态:DNS查询阶段,正在连接主机,发送请求阶段,以及处理服务器响应过程。依据状态的不同,线程被分别放在不同的队列中。当线程的状态发生改变时,异步IO的方式被用来发出事件通知,同时线程被转移到另一个相关队列中。
事实上,由于面对如此巨大的数据处理,总会有一些难以预料的事情发生。举个例子来说,如果爬虫试图处理的链接是一个在线游戏,那会出现什么情况?情况的确很糟,自作聪明的爬虫将取回大量的垃圾页面,而当你发现问题并试图处理时,你将面对的是数以千万计的已经被下载的网页。看来,有些导致错误的因素也许根本是无法预测的。系统必须经过认真的测试。然而,Internet如此之大,测试工作从何开始?这个时候,合理处理用户的反馈信息显得尤为重要。
4.4 Web索引技术(Indexing the Web)
解析技术(Parsing)--任何一种为Web设计的解析技术必须能够有效处理各种各样可能出现的错误,包括HTML标签的拼写错误,标签定义中缺少的空格,非ASCII字符,错误嵌套的HTML标签以及形形色色的其它错误类型。这些错误都在挑战着设计者的想象力,促使他们拿出创造性的设计方案。考虑到速度的最大化,Google没有采用由YACC来产生CFG解析器的做法,而使用Flex(一种快速的词典分析器制作工具)设计了一个具有自己堆栈的词典分析器。当然,分析器必须同时实现稳定性和高速度的要求。
文档的哈希索引(Indexing Documents into Barrels)--文档被解析之后,就会被编码并放入有许多桶组成的哈希表中。文档中的每一个词,通过检索在内存中运行的词典哈希表,被映射成其所对应的WordID。词典中没有的词被纪录到一个日志文件中。当一个word被映射成WordID时,它在当前文档中的出现信息将被同时构造成相应的命中列表,然后命中列表被纪录到前序索引相对应的桶中。在这个过程中,词典必须被共享,所以如何解决索引阶段的并发操作问题成为一个难题。有一个方案,可以避免词典的共享。在这个方案中,使用一个基词典,其中固定使用大约14,000,000个词。扩增的词都写入到日志中。这样,多感索引器就可以并发的执行,而把这个包含扩增词汇的日志文件交给最后剩下的一个索引器处理就够了。
排序技术(Sorting)--为了建立倒排索引,排序排序器接管过前叙索引中的桶,并按照WordID进行重新排序,从而产生了两组倒排序的桶:一组是对于标题和锚命中的倒排序索引(short barrle),一组是对于所有命中列表的倒排序索引(full barrle)。由于排序的过程每次仅再一个桶中进行,所以只需要很少的临时空间。另外,排序的阶段被尽可能多的分派到多台计算机上运行,这样,多个排序器就可以并行处理多个不同的bucket。因为捅不适合被放入内存中运行,排序器便把它细分为一系列适合放进内存中的bucket,这些bucket是基于WordID和docID的。然后,排序器把每一个bucket加载到内存中,并执行排序,最后把它的内容分别写入到short barrle和full barrle这两组倒排的桶中。
4.5 搜索技术(Searching)
能够高效地提供高质量的搜索结果,是每一个搜索技术的最终目标。很多大型的商业化搜索引擎已经在执行效率方面取得了很大的进步。所以Google就把更多的精力投放到搜索结果的质量研究上来。当然,Google的执行效率同商业化的搜索引擎相比同样毫不逊色。
Google的搜索过程如下。
1.解析查询字符串;
2.把word映射成wordID;
3.对每一个word,首先从short barrel中doclist的开头进行检索;
4.遍历整个doclist直到发现有一个文档能够匹配所有的搜索项目;
5.为此查询计算文档的级别;
6.如果到了short barrel中doclist的结尾,则从full barrel中doclist的开头继续进行检索,并跳转到步骤4;
7.如果没有到达doclist的结尾,跳转到步骤4;
8.对所有通过rank匹配的文档进行排序,并返回前K个查询结果。
为了控制响应时间,一旦匹配的文档数目达到某个指定的值(例如40,000),如图4所示,搜索器就直接跳转到第8步。这就意味着可能有一些没有完全优化的查询结果被返回。尽管如此,PageRank技术的存在有效地改善了这种状况。
4.5.1级别审定系统(The Panking System)
与其它的搜索引擎相比,Google利用了更多的Web文档所提供的信息。每一个命中列表纪录了词的位置、字体、大小写等信息。另外,包含在锚文本中的命中和文党的PageRank一样被Google所关注。要把所有这些信息都综合起来给出一个页面的级别有点难度,级别判定功能必定被设计成不会受到任何个别因素的影响。
首先考虑一种最简单的情况--单词查询。为了在单词汇查询中计算出一个文档的级别,Google首先分析该词汇在这个文档中的命中列表。Google为每一个命中定义了以下几种不同的类型:标题、锚、URL、普通的大字体文本、普通的小字体文本 ,每一种类型都有自己的类型权重(type-weight).Google把命中的类型权重组合到一起形成一个以类型为索引的向量,接着统计出命中列表中每一种类型的命中所占的数量。每一个计数值又被转换为一个计数权重(count-weight),计数权重随计数值呈线性增长,到达某个计数值之后就会趋于停止。最后,把类型权重组成向量和计数权重组成的向量进行点乘得到的矢量积作为该文档的IR分值。IR分值和PageRank再进行组合从而得出文档最终的级别。
对于多词汇的查询,情况变得更加复杂。多个命中列表需要被同步分析,在文档中出现位置比较靠近的命中就会比位置离的教远的命中具有较高的权重。多个命中列表中的命中被综合到一起一使得邻近的命中最终被分配到一起。对于每一组经过匹配的命中,他们之间的相似度(proximity)接着被计算出来。相似度基于命中的文档(或锚)中距离的远近,并且被划分为10个不同的值“bins”,这些bins的范围被定义为从短语匹配(phrase match)到根本不匹配(not even close).除了对每一种类型的命中进行计数之外,同时也对每一种类型和相似度进行计数。每一对类型和相似度的组合称作一个类型相似度权重(type-prox-weight),命中的计数则被转换为计数权重。最后,把计数权重组成的向量和类型相似度权重组成的向量进行点乘也得到一个IR分值。在Google的一种特殊的调试模式中,这些数字和矩阵可以随查询结果一同显示,这将为级别审定系统的开发工作带来很大的帮助。