新浪微博如何找出专家和高质量的微博贴? ------spear ranking 算法
在微博上,我们可以看到各种转微博行为,有人转微博,有微博被转? 我们能不能通过这些转发行为来找出微博上权威专家用户和高质量微博贴? 我觉得是可以的。但是,这里有个问题,我们的算法必须能做到反作弊,对那些作弊的用户或者作弊的微博贴,我们能侦查出来,而不会给出高分。简单的说明:比如一个贴被一群水军疯狂转发,一个微博人疯狂转各种低质量的微博。
在web2.0 搜索时代,有两个出名的ranking算法: PageRank和HITS. 我现在要提到的算法就是基于HITS的。HITS是1999年social network mining领域大年kleinberg提出来的,我在之前的博客上也提到过。HTIS算法基于图的,网页链接可以看成一个有向图,每个节点分配两个属性:hub和authority。hub的值由这个节点出链节点的authority值共同决定,authority值由这个节点的入链hub值共同决定。
现在说下,我采用的方法:spear ranking(Spamming-resistant Expertise Analysis and Ranking):
方法的总体思路:一个人转发的高质量贴越多,他的权威性就越高。一个贴被越多的权威用户转发,帖子的质量就越高。专家更多倾向去发现帖子,然后很多人开始转发和follow,可以看图1:
图1:
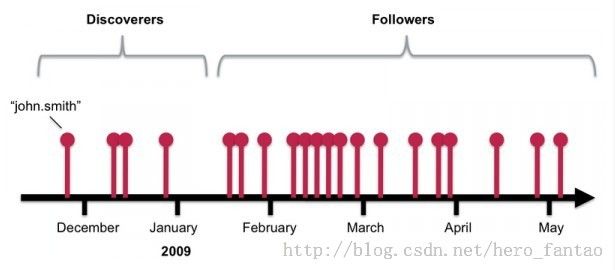
spear 算法会给那些内容发现者更好的信用评分,具体由credit-function来决定。
下面看下spear 算法的3个变量:
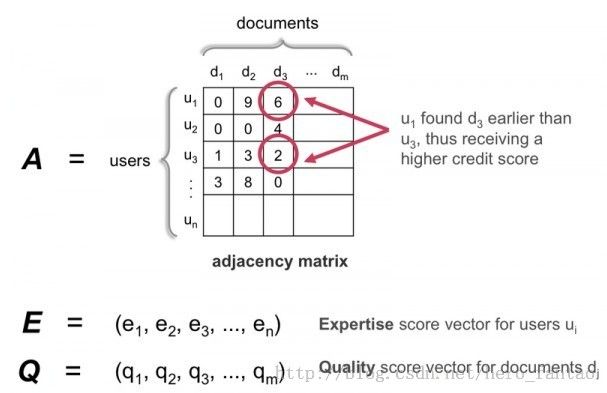
A是个邻接矩阵,E是用户得分向量,Q是文档质量得分向量。从A可以看出,每个用户对文档的信用得分是不一样的,这个由credit-function来决定,但是,得保证发现者比后来的follow者得分高。
迭代更新公式:
E(t) = A * Q(t-1)
Q(t) = E(t-1) *A
经过若干次迭代,可以得出算法收敛。收敛后的E,Q向量就是用户和文档的最终得分。
贴上算法的整个流程图:
算法的credit-function: c(x) = sqrt(x)
Rt(u,t,d,c),t 可以是时间戳。

下面,我来看下spear ranking 算法在delicious 数据集和新浪微博数据集上的表现:
1: delicious数据集
用户数:
1867, bookmark数目:
69223
用户行为的累积分布:
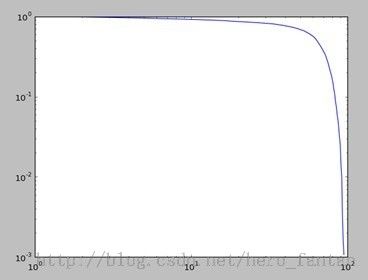
Bookmark被行为的累积分布:
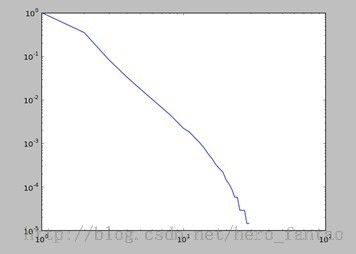
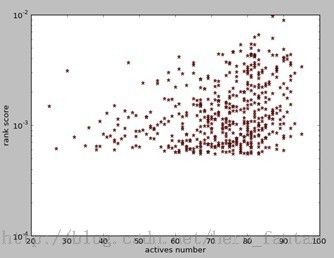
用户的rank得分和他添加的bookmark数量的分布(得分最高前500用户))(得分高,专家)
Bookmarks质量得分和bookmark被添加的数量分布(得分最高前5000 bookmark)(得分高,质量高)
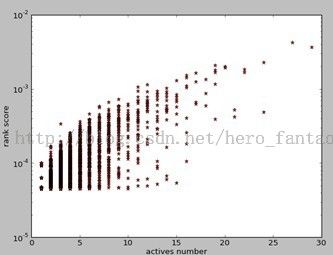
2. 新浪微博数据集:
用户的数量:
965304
转发的微博数量:
200860
用户转发有个时间戳,那些早转发,后面很多微博用户转发该微博,则用户credit评分越高。
用户转发数量的累计分布:
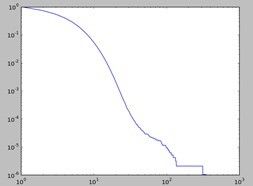
微博被转发数量的累积分布:
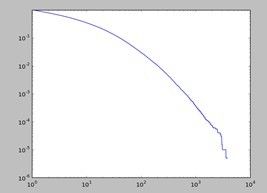
用户得分和他转发微博数量关系图(得分最高前5000用户):
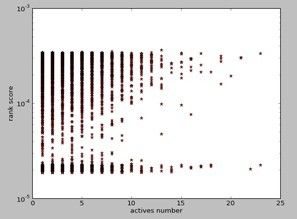
微博质量和它被转发数量的关系图(得分最高前5000微博):
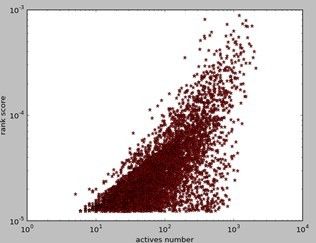
从时间结果看: 用户得分与他转发的数量其实并不表现正比关系,只有那些发现者才会得高分。微博帖子也表现一样。算法具有一定anti-spammer。
参考文献:
1:http://www.michael-noll.com/projects/spear-algorithm/:Telling Experts from Spammers: Expertise Ranking in Folksonomies
2: http://arnetminer.org/Influencelocality#b2352
3: grouplens: http://www.grouplens.org/