目标跟踪学习系列五:Real-time visual tracking via online weighted multiple instance learning(WMIL)学习
文章:Real-time visual tracking via online weighted multiple instance learning
Kaihua Zhang, Huihui Song
Department of Computing, The Hong Kong Polytechnic University, Hong Kong, China
Department of Geography and Resource Management, Chinese University of Hong Kong, Hong Kong, China
目前大多的tracking-by-detection的方法基本思想是:在线的方式训练一个分类器;然后使用sliding window从前一个目标位置周围,提取一些样本;再由分类器从这些样本中选出响应值最大的位置作为目标在当前帧中的位置。MIL解决了在线训练过程中不准确的问题。但是,它并没有考虑多事件中样本的权值问题。而实际上,根据所取得的样本离前一帧目标的位置远近可以大致确定它的重要性。这也是这一篇文章的核心思想。
设计一个鲁棒的表观模型是tracking的关键问题。围绕表观模型的设计,提出了产生式和判别是的方法。产生式学习到一个表观模型来表示目标,并从每一帧中找出最相似的区域。稀疏表示在遮挡,光照变化等方面都取得了非常好的效果。但是产生式最大的问题是没有考虑到背景信息,丢掉了很多有用的信息。目前的判别式的方法主要还是tracking-by-detection的方法。传统的方法最大的问题是漂移的问题,主要是训练的正样本太少,而正样本的准确率也有待考虑。提出的扩展正样本的方法可能会使得分类器很迷惑。于是又产生了多事件学习的算法(MIL),他将这种可能产生迷惑的情况通过一个样本集解决掉(bag):就是说,将多个样本放到一个集合里面,给他们赋一个标签。当这个集合里面的样本存在一个正样本或以上这个标签就是正的,否则为负。解决了样本可能使得分类器产生迷惑的问题。但是,若是根据样本距离目标的位置相应的赋上权重,将产生更好的结果。
文章的创新点就是通过样本距离目标位置的远近设置相应的权重。除此以外,作者通过泰勒展开,近似计算的方法避免了每一次选择一个分类器都要做M次概率计算的问题。提高了计算的速率!
具体的操作步骤如下:
首先,由第一帧得到的信息,构造正负包,同时根据公式(11):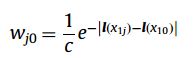 对每一个包里面的正负样本赋权重;
对每一个包里面的正负样本赋权重;
然后,计算各个包里面样本的harr-like特征向量。一般来说,样本的特征的概率分布满足高斯分布,再由贝叶斯法则得到它的概率;
然后,构造一组M个弱分类;通过公式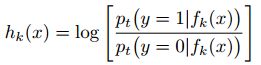 来构造;
来构造;
接下来,用motion model 根据上一帧目标的位置,扩展目标的搜索位置;根据公式:![]() ;
;
然后,通过计算目标的搜索位置的后验概率,得到最大的响应的样本,作为当前目标的位置(一直以为没有用到分类器,其实这里就是用到了的。公式(3)中:![]() 就要使用到,而后面计算多事例包的后验概率是在更新分类器);
就要使用到,而后面计算多事例包的后验概率是在更新分类器);
最后,由上面的目标的位置更新表观模型。通过![]() 扩展正样本;通过公式(18)
扩展正样本;通过公式(18)![]() 扩展负样本。计算
扩展负样本。计算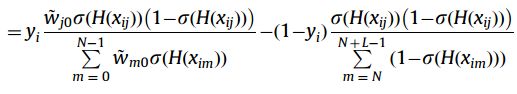 计算
计算![]() ;然后通过
;然后通过![]() 计算各个多事例包的后验概率的最大值,得到响应最大那个弱分类器,加入强分类器,如此再迭代上述过程。
计算各个多事例包的后验概率的最大值,得到响应最大那个弱分类器,加入强分类器,如此再迭代上述过程。