Python玩具总动员之爬虫篇(一):玩玩urllib,做个下载器吧
Base:
Created Monday 17 March 2014

什么是爬虫?
wiki解释: http://en.wikipedia.org/wiki/Web_spider
引用WIKI上的解释,爬虫说白就是首先就是一个程序(废话..),然后这个程序能做什么?他可以抓取网页,把数据保存下来。再网上一点说,光抓取网页没啥技术含量对吧?关键困难是从网页中分析提取和整理你想要的数据,正如弱水三千只取一Piao..百度Google搜索引擎什么的技术之一就是非常牛X的爬虫吧。
爬虫的原理?
这种原理性的东西小白我目前只能依靠大牛们的Blog学习了,这里推荐几个网站,大家和我一起慢慢参悟吧。
网络爬虫的基本原理
网络爬虫的基本原理
咱们来动动手吧
下面需要用Python实现一个简易的Web Crawler.万能的Python Standrad Lib救救我吧~
在标准库中,python给我们提供了 urllib 模块,然后借助urllib模块,我们一步一步来作一个下载器。
在标准库中,python给我们提供了 urllib 模块,然后借助urllib模块,我们一步一步来作一个下载器。
文中用的几个函数方法都可以在Python Standrad Documents 查看哦,但是先不用看在代码中看不懂在查阅Python Documents
urllib.urlopen
urllib.urlretrieve
sys.argv
sys.stdout
Version 1.0 : 把任意某个网址的网页抓取下来并且打印出来:
import urllib url = "http://www.csdn.net" print urllib.urlopen(url).read()
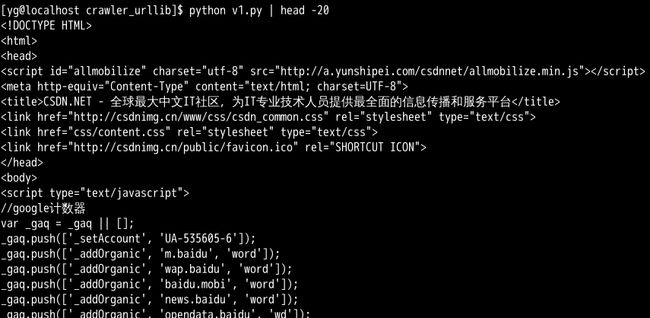
没有错,你木看错。你已经写了一个最简单的爬虫了,你成功的把CSDN首页抓下来并打印到terminal中了,当然你回来到terminal刷的一排下来,看不清是吧?
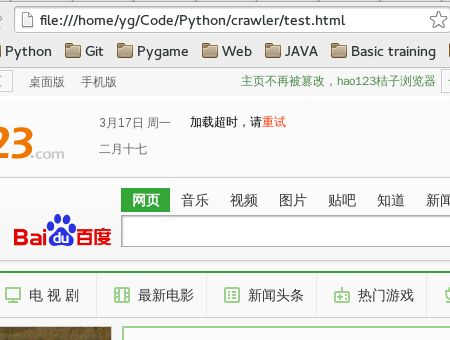
那么好我们需要更新程序了哈哈,把V1.0 升级到V1.1,增加功能为把抓到的网页输入到文件中,并且保存为HTML,然后浏览器打开
那么好我们需要更新程序了哈哈,把V1.0 升级到V1.1,增加功能为把抓到的网页输入到文件中,并且保存为HTML,然后浏览器打开
Version 1.1 : 保存到文件中
#-*-coding:utf-8
import urllib
#导入python标准库给我们提供的urllib
url = "http://www.hao123.com"
#这个是我们要抓取的网页地址,一定不要忘记有http://这个符号哦
tmp_file = open("/home/yg/Code/Python/tmp.html","w")
#打开文件,传过去的参数的是你路径连文件名一起
tmp_file.write(urllib.urlopen(url).read())
#urllib.urlopen()大家可以查文档,意思穿过去url,a file-like object is returned
tmp_file.close()
#上完厕所要冲水,打开文件要关闭
#然后用浏览器打开文件看看

通过V1.1我们已经能把网页抓取下来并且保存在文件中了,可是每一次都需要open file close file 吗?那么有没有更快的方法呢?有。这次我们更新到V1.2版本
Version 1.2 : 用另一种方法也能保存在文件中
import urllib url = "http://www.hao123.com" filename = "./test.html" urllib.urlretrieve(url,filename) #urllib.urlretrieve()第一个参数为url 第二个参数为文件路径和文件名 #它直接把制定网页存储到本地文件中
通过v1.2我们已经知道有urllib.urlretrieve()的其中两个参数,让我们在update我们的版本,用urllib.urlretrieve()第三个参数
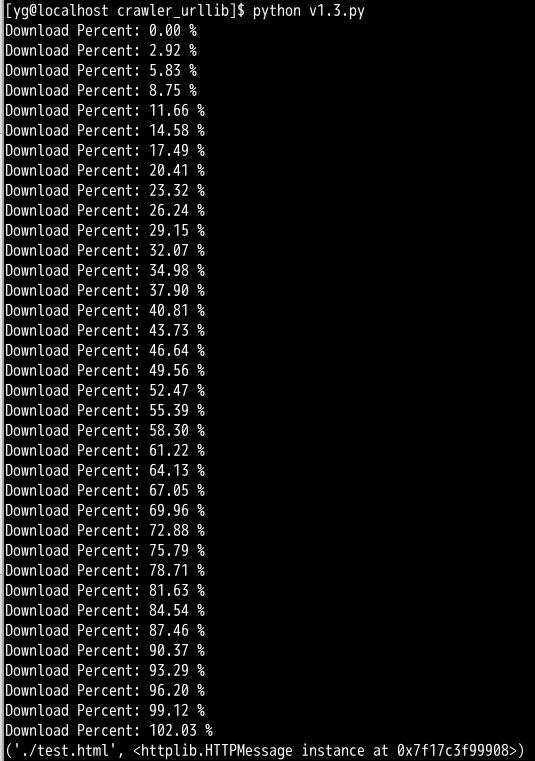
Version 1.3:这回我们增加网页下载进度显示哦
#-*-coding:utf-8-*- import urllib url = "http://www.hao123.com" filename = "./test.html" def reporthook(count,block_size,total_size): """ 回调函数 下载进度现实的函数 @count 已经下载的数据块的个数 是个数哦 @block_size 数据会的大小,一般都是多少多少字节哦 @totol_size 总的文件大小 有了这三个量我们就可以计算进度了哈 只要totol_size 等于 count * block_size 那就说明下载完毕了 """ per = (100.0 * count * block_size ) / total_size #per就是百分进度了 print "Download Percent: %.2f %%" % per down_log = urllib.urlretrieve(url,filename,reporthook) #reporthook是一个回调函数,就是你传函数名(其实是函数的指针,一个地址),然后它实现里面回调用你函数并传进去三个参数 print down_log
Version 1.4:是不是只能下载网页哈?能不能下载文件?咱们试一试
#-*-coding:utf-8-*-
import urllib
import os
from sys import argv,exit,stdout
"""
这回我们试一试下载一个其他文件例如rar看看能不能
这回我们增加交互,用过sys.argv来传入url 和 filename
"""
def url_decide(url):
"""
把url传进来判断rul是否正确
url 传进来的,url正确就返filname 用于判断文件类型
"""
#判断有没有http字符
if url.find("http://") == -1:
print "URL Error"
exit()
#判断是不是http开头字符
if url.split("://")[0] != "http":
print "Error URL:Are you forget the head of 'HTTP'?"
exit()
filename = url.split("/")[-1]
down_type = ["html","htm","zip","tar.gz","tar","msi","rar"]
#判断是不是其中的一种类型,是的话就直接返回结尾文件名,不是默认返回html
#例如 http://zim-wiki.org/downloads/zim-0.60.tar.gz 我们判断结尾就是tar.gz格式
for i in down_type:
if i in filename:
print "Tpye:" + i
return filename
#假如不再上面的类型 list中,我们就认为他是一个网站,例如www.baidu.com
return "tmp.html"
def path_exists(filename):
"""
判断路径是否正确,如果不存在没有就创建
"""
if os.path.exists(filename) == True:
print "path is ok"
elif os.path.exists(filename) == False:
print "no path"
os.mkdir(filename)
def reporthook(count,block_size,total_size):
"""
回调函数
下载进度现实的函数
@count 已经下载的数据块的个数 是个数哦
@block_size 数据会的大小,一般都是多少多少字节哦
@totol_size 总的文件大小
有了这三个量我们就可以计算进度了哈
只要totol_size 等于 count * block_size 那就说明下载完毕了
"""
per = (100.0 * count * block_size ) / total_size
#per就是百分进度了
print "Download Percent: %.2f %%" % per,
stdout.write("\r")
#输出进度,保留两个百分点,stdout。write("\r")是每次输出光标回到行首,这样目的为了一行输出进度,print xxx, 逗号在print后面表示不换行
def download(url,filename):
down_log = urllib.urlretrieve(url,filename,reporthook)
#reporthook是一个回调函数,就是你传函数名(其实是函数的指针,一个地址),然后它实现里面回调用你函数并传进去三个参数
print "Your file on : " + down_log[0]
script_name,url,path = argv
#argv是一个list 装了我们python xxx.py xx xxx 时候带的参数 argv[0]就是xxx.py argv[1]是xxx
print "you input argv is '%s' '%s' '%s' " % (script_name,url,path)
#看一看我们输入的参数
filename = url_decide(url)
#判断url对不对和文件类型
path_exists(path)
#判断路径存在否
download_filename = path + filename
#完整的路径链接文件名字,作为参数传过去
print download_filename
download(url,download_filename)
#开始下载吧
咱们看看效果吧!是不是已经可以下载文件了?一个简单的文件下载器就出来了。

![]()
作者:YangGan
出处:http://blog.csdn.net/incyanggan
本文基于署名 2.5 中国大陆许可协议发布,欢迎转载,演绎或用于商业目的,但是必须保留本文的署名Yanggan(包含链接).