win32结构化异常处理(SEH)探秘
Win32 结构化异常处理(SEH)探秘
原著:Matt Pietrek
编译:VCKBASE
转至:http://www.vckbase.com/document/viewdoc/?id=1867
原文出处:A Crash Course on the Depths of Win32? Structured Exception Handling
本文假设你熟悉 C++,Win32
摘要
Win32 结构化异常处理其核心是操作系统提供的服务,你能找到的关于 SEH 的所有文档都是描述一个特定的编译器运行时库,这个运行库包装着操作系统实现。在本文中,我将一层一层对 SEH 进行剥离,以便展现其最基本的概念。
在 Win32 操作系统提供的所有功能中,使用最广泛但最缺乏文档描述的也许就是结构化异常处理了(SEH),当你考虑 Win32 结构化异常处理时,你也许会想到诸如 _try,_finally 以及 _except 这些术语。你能在任何有关 Win32 的书中发现对 SEH 很好的描述(即使是 remedial)。即便是 Win32 SDK 也具备有相当完整的使用 _try,_finally 和 _except 进行结构化异常处理的概述。
有了这些文档,那为何还说 SEH 缺乏文档呢?其实,Win32 结构化异常处理是操作系统提供的一个服务。你能找到的关于 SEH 的所有文档都是描述特定编译器的运行时库,这个运行库对操作系统实现进行包装。_try,_finally 和 _except 这些关键字没有任何神奇的地方。微软的操作系统及其编译器系列定义这些关键字和用法。其他的编译器提供商则只是沿用这些语义。虽然借助编译器层的 SEH 可以挽回一些原始操作系统级 SEH 处理不良口碑,但在大众眼里对原始操作系统 SEH 细节的处理感觉依旧。
我收到人们大量的e-mail,都是想要实现编译器级的 SEH 处理,又无法找到操作系统功能提供的相关文档。通常我都是建议参考 Visual C++ 或者 Borland C++ 运行库源代码。唉,出于一些未知的原因,编译器级的 SEH 似乎是一个大的秘密,微软和 Borland 都不提供其对 SEH 支持的核心层源代码。
在本文中,我将一层一层对 SEH 进行解剖,以便展现其最基本的概念。我打算通过代码产生和运行时库支持将操作系统提供的功能和编译器提供的功能分开。当我深入代码考察关键的操作系统例程时,我将使用 Intel 平台上的 Windows NT4.0 作为基础。但我将要描述的大多数内容同样适用于其它处理器上运行的应用。
我打算避免涉及到真正的 C++ 异常处理,它们使用 catch(),而不是 _except。其实,真正的 C++ 异常处理实现非常类似于本文中描述的内容。但是 C++ 异常处理有一些额外的复杂性会影响我想要涉及的概念。
通过深入研究晦涩的 .H 和 .INC 文件来归纳 Win32 SEH 构成,我发现有一个信息源之一就是 IBM OS/2 头文件(尤其是 BSEXCPT.H)。为此你不要觉得大惊小怪。。此处描述的 SEH 机制在其源头被定义时,微软仍然开发 OS/2 平台(译注: OS/2 平台起初是IBM 和 微软共同研发的,后来由于种种原因两个公司没有再继续下去)。所以你会发现Win32 下的 SEH 和 OS/2 下的 SEH 极其相似。
SEH 浅析
从整体来看,SEH 的可谓不可一世,绝对压倒一切,我将从细微之处开始,用我自己的方式一层一层研究。如果你是一张白纸,以前从没接触过结构化异常处理,那就最好不过了。如果你以前使用过 SEH。那就尝试清理你头脑中的 _try,GetExceptionCode 和 EXCEPTION_EXECUTE_HANDLER 等诸如此类的词,权当自己是个新手。做一个深呼吸,准备好了吗?好,我们开始。
想象一下,我告诉你某个线程出错了,操作系统给你一个机会通知了这个线程错误,或者再具体一点,当线程出错后,操作系统调用某个用户定义的回调函数。这个回调函数可以所任何它想做的事情。例如,它可以修复任何原因导致的错误,或者播放一个 .wav 文件。不管回调函数做什么,其最后总是返回一个值,这个值告诉系统下一步做什么。(这里描述的情况不一定完全一样,但足够接近。)
假定当你的代码出现了混乱,你不得不回来,想看看回调函数是什么样子的?换句话说,你想知道什么样的异常信息呢?其实这无关紧要,因为 Win32 已经帮你决定了。一个异常回调函数就象下面这样:
- EXCEPTION_DISPOSITION
- __cdecl _except_handler(
- struct _EXCEPTION_RECORD *ExceptionRecord,
- void * EstablisherFrame,
- struct _CONTEXT *ContextRecord,
- void * DispatcherContext
- );
该原型出自标准的 Win32 头文件 EXCPT.H,初看就有那么一点不同凡响。如果你慢慢研究,其实并没有那么糟。例如,忽略返回类型(EXCEPTION_DISPOSITION)。基本上你看到的就是一个叫做 _except_handler 的函数,这个函数带有四个参数。
第一个参数是指向 EXCEPTION_RECORD 结构指针,该结构在 WINNT.H 中定义如下:
- typedef struct _EXCEPTION_RECORD {
- DWORD ExceptionCode;
- DWORD ExceptionFlags;
- struct _EXCEPTION_RECORD *ExceptionRecord;
- PVOID ExceptionAddress;
- DWORD NumberParameters;
- DWORD ExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS];
- } EXCEPTION_RECORD;
ExceptionCode 参数是由操作系统赋值给异常的一个数。你可以在 WINNT.H 文件中搜一下“STATUS_”开始的 #defines 内容便可以得到一系列不同的异常编码。例如 STATUS_ACCESS_VIOLATION 是大家再熟悉不过的异常编码了,其值是 0xC0000005。更复杂的异常编码可以从 Windows NT DDK 的 NTSTATUS.H 文件中找到。EXCEPTION_RECORD 结构中的第四个元素是异常发生的地址。剩下的 EXCEPTION_RECORD 域现在可以忽略,不用管它。
_except_handler 回调函数的第二个参数是指向建立者框架(establisher frame)结构的指针,在 SEH 中它是一个至关重要的参数,但现在可以不用关心它。
_except_handler 回调函数的第三个参数是 CONTEXT 结构的指针。CONTEXT 结构在 WINNT.H 中定义,它表示特定线程异常发生时寄存器的值:
- typedef struct _CONTEXT
- {
- DWORD ContextFlags;
- DWORD Dr0;
- DWORD Dr1;
- DWORD Dr2;
- DWORD Dr3;
- DWORD Dr6;
- DWORD Dr7;
- FLOATING_SAVE_AREA FloatSave;
- DWORD SegGs;
- DWORD SegFs;
- DWORD SegEs;
- DWORD SegDs;
- DWORD Edi;
- DWORD Esi;
- DWORD Ebx;
- DWORD Edx;
- DWORD Ecx;
- DWORD Eax;
- DWORD Ebp;
- DWORD Eip;
- DWORD SegCs;
- DWORD EFlags;
- DWORD Esp;
- DWORD SegSs;
- } CONTEXT;
此外,这个 CONTEXT 结构与 GetThreadContext 和 SetThreadContext API 函数使用的结构是相同的。
_except_handler 回调函数的第四个参数是 DispatcherContext。现在也可以忽略它。
为了简化起见,当异常发生时,你有一个回调函数被调用。此回调函数带四个参数,其中三个是结构指针。在这些结构中,某些域是很重要的,其余的不是那么重要。关键是 _except_handler 回调函数接收
很多信息,比如发生了什么类型的异常,在哪里发生的。利用这些信息,异常回调机制需要确定要做什么。
虽然我迫不急但地想抛出例子程序示范 _except_handler 回调的运行,但还有一些事情不能漏掉,需要说明。特别是当错误发生时,操作系统如何知道到哪里调用?答案仍然涉及另外一个结构 EXCEPTION_REGISTRATION。你将自始自终在本文中看到这个结构,所以不要掠过这部分内容。我能找到正式定义 EXCEPTION_REGISTRATION 结构的唯一地方是 EXSUP.INC 文件,该文件来自 Visual C++ 运行库的源:
- _EXCEPTION_REGISTRATION struc
- prev dd ?
- handler dd ?
- _EXCEPTION_REGISTRATION ends
你还将看到该结构在 WINNT.H 文件中定义的 NT_TIB 结构中被引用为 _EXCEPTION_REGISTRATION_RECORD。唉,除此之外,没有什么地方能找到 _EXCEPTION_REGISTRATION_RECORD 的定义,所以我只能使用 EXSUP.INC 文件中定义的汇编语言结构。这也是我为什么在本文前述内容中说过的 SEH 缺乏文档的一个例证。
不管怎样,让我们回到手头的问题,当某个异常发生时,OS 如何知道到哪里调用回调函数?EXCEPTION_REGISTRATION 由两个域构成,第一个你现在可以忽略。第二个域是句柄,它包含 _except_handler 回调函数的指针。这让你更接近一点了,但目前问题来了,OS 在哪里查找并发现 EXCEPTION_REGISTRATION 结构?
为了回答这个问题,回想一下结构化异常处理是以线程为基础,并作用在每个线程上,明白这一点是有助于理解的。也就是说,每个线程具备其自己的异常处理回调函数。在我1996年5月的专栏文章中,我描述了一个关键的 Win32 数据结构——线程信息块(即 TEB 和 TIB)。该数据结构的某些域在 Windows NT、Windows 95、Win32s 和 OS/2 平台上是一样的。TIB 中的第一个 DWORD 是指向线程 EXCEPTION_REGISTRATION 结构的指针。在 Intel Win32 平台上,FS 寄存器总是指向当前的 TIB。因此,在 FS:[0]位置,你能找到 EXCEPTION_REGISTRATION 结构的指针。
现在我们知道了,当异常发生时,系统检查出错线程的 TIB 并获取 EXCEPTION_REGISTRATION 结构的指针。这个结构中就有一个 _except_handler 回调函数的指针。这些信息足以让操作系统知道在哪里以及如何调用 _except_handler 函数,如图二所示:

图二 _except_handler 函数
通过前面的描述,我写了一个小程序来对操作系统层的结构化异常进行示范。程序代码如下:
- //==================================================
- // MYSEH - Matt Pietrek 1997
- // Microsoft Systems Journal, January 1997
- // FILE: MYSEH.CPP
- // To compile: CL MYSEH.CPP
- //==================================================
- #define WIN32_LEAN_AND_MEAN
- #include <windows.h>
- #include <stdio.h>
- DWORD scratch;
- EXCEPTION_DISPOSITION
- __cdecl
- _except_handler(
- struct _EXCEPTION_RECORD *ExceptionRecord,
- void * EstablisherFrame,
- struct _CONTEXT *ContextRecord,
- void * DispatcherContext )
- {
- unsigned i;
- // Indicate that we made it to our exception handler
- printf( "Hello from an exception handler/n" );
- // Change EAX in the context record so that it points to someplace
- // where we can successfully write
- ContextRecord->Eax = (DWORD)&scratch;
- // Tell the OS to restart the faulting instruction
- return ExceptionContinueExecution;
- }
- int main()
- {
- DWORD handler = (DWORD)_except_handler;
- __asm
- {
- // 创建 EXCEPTION_REGISTRATION 结构:
- push handler // handler函数的地址
- push FS:[0] // 前一个handler函数的地址
- mov FS:[0],ESP // 装入新的EXECEPTION_REGISTRATION结构
- }
- __asm
- {
- mov eax,0 // EAX清零
- mov [eax], 1 // 写EAX指向的内存从而故意引发一个错误
- }
- printf( "After writing!/n" );
- __asm
- {
- // 移去我们的 EXECEPTION_REGISTRATION 结构记录
- mov eax,[ESP] // 获取前一个结构
- mov FS:[0], EAX // 装入前一个结构
- add esp, 8 // 将 EXECEPTION_REGISTRATION 弹出堆栈
- }
- return 0;
- }
代码中只有两个函数,main 函数使用了三部分内联汇编块 ASM。第一个 ASM 块通过两个 PUSH 指令(即:“PUSH handler”和“PUSH FS:[0]”)在堆栈上建立一个 EXCEPTION_REGISTRATION 结构。PUSH FS:[0] 保存以前 FS:[0] 的值,它是结构的一部分,但目前这个值对我们不重要。重要的是在堆栈上有一个 8-byte 的 EXCEPTION_REGISTRATION 结构。紧接着的指令(MOV FS:[0],ESP)是让线程信息块中的第一个 DWORD 指到新的 EXCEPTION_REGISTRATION 指令。
如果你想知道为什么我要在堆栈上建立这个 EXCEPTION_REGISTRATION 结构,而不是使用全局变量,有一个很好的理由。当你使用编译器的 _try/_except 时,编译器也会在堆栈上建立 EXCEPTION_REGISTRATION 结构。我只是向你简要地揭示你使用 _try/_except 时编译器所做的事情。让我们回到 main 函数,下一个 __asm 块是通过把 EAX 寄存器清零(MOV EAX,0),然后把此寄存器的值作为内存地址让下一条指令(MOV [EAX],1)向此地址写入数据而故意引发一个错误。最后一个 __asm 块是清除这个简单的异常处理例程:首先它恢复以前的 FS:[0] 内容,然后它将 EXCEPTION_REGISTRATION 结构记录从堆栈中弹出(ADD ESP,8)。
现在,假设你正在运行 MYSEH.EXE 并会看到所发生的事情。当 MOV [EAX],1 指令执行时,它导致一个数据访问违例。系统察看 TIB 中的 FS:[0] 并找到 EXCEPTION_REGISTRATION 结构指针。此结构中则有一个指向 MYSEH.CPP 中 _except_handler 函数的指针。系统则将四个必须的参数(我在前面描述过这四个参数)压入堆栈并调用 _except_handler 函数。
一旦进入 _except_handler,代码首先通过 printf 指示“哈!这里是我干的!”。接着,_except_handler 修复导致出错的问题。即 EAX 寄存器指向某个不能写入的内存地址(地址 0)。修复方法是在改变 CONTEXT 结构中的 EAX 的值,以便它指向某个允许进行写入操作的位置。在这个简单的程序中,DWORD 变量(scratch)是故意为此而设计的。_except_handler 函数最后一个动作时返回 ExceptionContinueExecution 值,它在标准的 EXCPT.H 文件中定义。
当操作系统看到返回值为 ExceptionContinueExecution。它就认为你已经修复了问题,并且引起错误的指令应该被重新执行。因为我的 _except_handler 函数强制 EAX 寄存器指向合法内存,MOV EAX,1 指令再次执行,函数 main 一切正常。看,这并不复杂,不是吗?
进一步深入
有了前面的最简单的例子,让我们再回过头去填补一些空白。虽然这个异常回调机制很棒,但它并不是一个完美的解决方案。对于稍微复杂一些的应用程序来说,仅用一个函数就能处理程序中任何地方都可能发生的异常是相当困难的。一个更实用的方案应该是有多个异常处理例程,每个例程针对程序的特定部分。不知你是否知道,实际上,操作系统提供的正是这个功能。
还记得系统用来查找异常回调函数的 EXCEPTION_REGISTRATION 结构吗?这个结构的第一个成员,称为 prev,前面我们曾把它忽略掉了。它实际上是一个指向另外一个 EXCEPTION_REGISTRATION 结构的指针。这第二个 EXCEPTION_REGISTRATION 结构可以有一个完全不同的处理函数。然后呢,它的 prev 域可以指向第三个 EXCEPTION_REGISTRATION 结构,依次类推。简单地说,就是有一个 EXCEPTION_REGISTRATION 结构链表。线程信息块的第一个 DWORD(在基于 Intel CPU 的机器上是 FS:[0])总是指向这个链表的头部。
操作系统要这个 EXCEPTION_REGISTRATION 结构链表做什么呢?原来,当异常发生时,系统遍历这个链表以便查找其中的一个EXCEPTION_REGISTRATION 结构,其例程回调(异常处理程序)同意处理该异常。在 MYSEH.CPP 的例子中,异常处理程序通过返回ExceptionContinueExecution 表示它同意处理这个异常。异常回调函数也可以拒绝处理这个异常。在这种情况下,系统移向链表的下一个EXCEPTION_REGISTRATION 结构并询问它的异常回调函数,看它是否愿意处理这个异常。图四显示了这个过程:
图四 查找处理异常的 EXCEPTION_REGISTRATION 结构
一旦系统找到一个处理该异常的某个回调函数,它就停止遍历结构链表。
下面的代码 MYSEH2.CPP 就是一个异常处理函数不处理某个异常的例子。为了使代码尽量简单,我使用了编译器层面的异常处理。main 函数只设置了一个 __try/__except块。在__try 块内部调用了 HomeGrownFrame 函数。这个函数与前面的 MYSEH 程序非常相似。它也是在堆栈上创建一个 EXCEPTION_REGISTRATION 结构,并且让 FS:[0] 指向此结构。在建立了新的异常处理程序之后,这个函数通过向一个 NULL 指针所指向的内存处写入数据而故意引发一个错误:
- *(PDWORD)0 = 0;
这个异常处理回调函数,同样被称为_except_handler,却与前面的那个截然不同。它首先打印出 ExceptionRecord 结构中的异常代码和标志,这个结构的地址是作为一个指针参数被这个函数接收的。打印出异常标志的原因稍后就会明白。因为_except_handler 函数并没有打算修复出错的代码,因此它返回 ExceptionContinueSearch。这导致操作系统继续在 EXCEPTION_REGISTRATION 结构链表中搜索下一个 EXCEPTION_REGISTRATION结构。接下来安装的异常回调函数是针对 main 函数中的__try/__except块的。__except 块简单地打印出“Caught the exception in main()”。此时我们只是简单地忽略这个异常来表明我们已经处理了它。 以下是 MYSEH2.CPP:
- //=================================================
- // MYSEH2 - Matt Pietrek 1997
- // Microsoft Systems Journal, January 1997
- // FILE: MYSEH2.CPP
- // 使用命令行CL MYSEH2.CPP编译
- //=================================================
- #define WIN32_LEAN_AND_MEAN
- #include <windows.h>
- #include <stdio.h>
- EXCEPTION_DISPOSITION
- __cdecl _except_handler(
- struct _EXCEPTION_RECORD *ExceptionRecord,
- void * EstablisherFrame,
- struct _CONTEXT *ContextRecord,
- void * DispatcherContext )
- {
- printf( "Home Grown handler: Exception Code: %08X Exception Flags %X",
- ExceptionRecord->ExceptionCode, ExceptionRecord->ExceptionFlags );
- if ( ExceptionRecord->ExceptionFlags & 1 )
- printf( " EH_NONCONTINUABLE" );
- if ( ExceptionRecord->ExceptionFlags & 2 )
- printf( " EH_UNWINDING" );
- if ( ExceptionRecord->ExceptionFlags & 4 )
- printf( " EH_EXIT_UNWIND" );
- if ( ExceptionRecord->ExceptionFlags & 8 ) // 注意这个标志
- printf( " EH_STACK_INVALID" );
- if ( ExceptionRecord->ExceptionFlags & 0x10 ) // 注意这个标志
- printf( " EH_NESTED_CALL" );
- printf( "/n" );
- // 我们不想处理这个异常,让其它函数处理吧
- return ExceptionContinueSearch;
- }
- void HomeGrownFrame( void )
- {
- DWORD handler = (DWORD)_except_handler;
- __asm
- {
- // 创建EXCEPTION_REGISTRATION结构:
- push handler // handler函数的地址
- push FS:[0] // 前一个handler函数的地址
- mov FS:[0],ESP // 安装新的EXECEPTION_REGISTRATION结构
- }
- *(PDWORD)0 = 0; // 写入地址0,从而引发一个错误
- printf( "I should never get here!/n" );
- __asm
- {
- // 移去我们的EXECEPTION_REGISTRATION结构
- mov eax,[ESP] // 获取前一个结构
- mov FS:[0], EAX // 安装前一个结构
- add esp, 8 // 把我们EXECEPTION_REGISTRATION结构弹出堆栈
- }
- }
- int main()
- {
- __try
- {
- HomeGrownFrame();
- }
- __except( EXCEPTION_EXECUTE_HANDLER )
- {
- printf( "Caught the exception in main()/n" );
- }
- return 0;
- }
这里的关键是执行流程。当一个异常处理程序拒绝处理某个异常时,它实际上也就拒绝决定流程最终将从何处恢复。只有接受某个异常的异常处理程序才能决定待所有异常处理代码执行完毕之后流程将从何处继续执行。这个规则暗含的意义非常重大,虽然现在还不是显而易见。
当使用结构化异常处理时,如果一个函数有一个异常处理程序但它却不处理某个异常,这个函数就有可能非正常退出。例如在 MYSEH2中 HomeGrownFrame 函数就不处理异常。由于在链表中后面的某个异常处理程序(这里是 main 函数中的)处理了这个异常,因此出错指令后面的 printf 就永远不会执行。从某种程度上说,使用结构化异常处理与使用 setjmp 和 longjmp 运行时库函数有些类似。
如果你运行 MYSEH2,会发现其输出有些奇怪。看起来好像调用了两次 _except_handler 函数。根据你现有的知识,第一次调用当然可以完全理解。但是为什么会有第二次呢?
- Home Grown handler: Exception Code: C0000005 Exception Flags 0
- Home Grown handler: Exception Code: C0000027 Exception Flags 2 EH_UNWINDING
- Caught the Exception in main()
比较一下以“Home Grown Handler”开头的两行,就会看出它们之间有明显的区别。第一次异常标志是0,而第二次是2。这个问题说来话就长了。实际上,当一个异常处理回调函数拒绝处理某个异常时,它会被再一次调用。但是这次回调并不是立即发生的。这有点复杂。我需要把异常发生时的情形好好梳理一下。
当异常发生时,系统遍历 EXCEPTION_REGISTRATION 结构链表,直到它找到一个处理这个异常的处理程序。一旦找到,系统就再次遍历这个链表,直到处理这个异常的结点为止。在这第二次遍历中,系统将再次调用每个异常处理函数。关键的区别是,在第二次调用中,异常标志被设置为2。这个值被定义为 EH_UNWINDING。(EH_UNWINDING 的定义在 Visual C++ 运行时库源代码文件 EXCEPT.INC 中,但 Win32 SDK 中并没有与之等价的定义。)
EH_UNWINDING 表示什么意思呢?原来,当一个异常处理回调函数被第二次调用时(带 EH_UNWINDING 标志),操作系统给这个函数一个最后清理的机会。什么样的清理呢?一个绝好的例子是 C++ 类的析构函数。当一个函数的异常处理程序拒绝处理某个异常时,通常执行流程并不会正常地从那个函数退出。现在,想像一下定义了一个C++类的实例作为局部变量的函数。C++规范规定析构函数必须被调用。这带 EH_UNWINDING 标志的第二次回调就给这个函数一个机会去做一些类似于调用析构函数和__finally 块之类的清理工作。
在异常已经被处理完毕,并且所有前面的异常帧都已经被展开之后,流程从处理异常的那个回调函数决定的地方开始继续执行。一定要记住,仅仅把指令指针设置到所需的代码处就开始执行是不行的。流程恢复执行处的代码的堆栈指针和栈帧指针(在Intel CPU上是 ESP 和EBP)也必须被恢复成它们在处理这个异常的函数的栈帧上的值。因此,这个处理异常的回调函数必须负责把堆栈指针和栈帧指针恢复成它们在包含处理这个异常的 SEH 代码的函数的堆栈上的值。
通常,展开操作导致堆栈上处理异常的帧以下的堆栈区域上的所有内容都被移除了,就好像我们从来没有调用过这些函数一样。展开的另外一个效果就是 EXCEPTION_REGISTRATION 结构链表上处理异常的那个结构之前的所有 EXCEPTION_REGISTRATION 结构都被移除了。这很好理解,因为这些 EXCEPTION_REGISTRATION 结构通常都被创建在堆栈上。在异常被处理后,堆栈指针和栈帧指针在内存中比那些从 EXCEPTION_REGISTRATION 结构链表上移除的 EXCEPTION_REGISTRATION 结构高。图六显示了我说的情况。

图六 从异常展开
帮帮我!没有人处理它!
迄今为止,我实际上一直在假设操作系统总是能在 EXCEPTION_REGISTRATION 结构链表中 的某个地方找到一个异常处理程序。如果找不到怎么办呢?实际上,这几乎不可能发生。因为操作系统暗中已经为每个线程都提供了一个默认的异常处理程序。这个默认的异常处理程序总是链表的最后一个结点,并且它总是选择处理异常。它进行的操作与其它正常的异常处理回调函数有些不同,下面我会说明。
让我们来看一下系统是在什么时候插入了这个默认的、最后一个异常处理程序。很明显它需要在线程执行的早期,在任何用户代码开始执行之前。
下面是我为 BaseProcessStart 函数写的伪代码。它是 Windows NT KERNEL32.DLL 的一个内部例程。这个函数带一个参数——线程入口点函数的地址。BaseProcessStart 运行在新进程的上下文环境中,并且从该进程的第一个线程的入口点函数开始执行。
- BaseProcessStart 伪码
- BaseProcessStart( PVOID lpfnEntryPoint )
- {
- DWORD retValue
- DWORD currentESP;
- DWORD exceptionCode;
- currentESP = ESP;
- _try
- {
- NtSetInformationThread( GetCurrentThread(),
- ThreadQuerySetWin32StartAddress,
- &lpfnEntryPoint, sizeof(lpfnEntryPoint) );
- retValue = lpfnEntryPoint();
- ExitThread( retValue );
- }
- _except(// 过滤器-表达式代码
- exceptionCode = GetExceptionInformation(),
- UnhandledExceptionFilter( GetExceptionInformation() ) )
- {
- ESP = currentESP;
- if ( !_BaseRunningInServerProcess ) // 常规进程
- ExitProcess( exceptionCode );
- else // 服务
- ExitThread( exceptionCode );
- }
- }
在这段伪码中,注意对 lpfnEntryPoint 的调用被封装在一个__try 和 __except 块中。正是此__try 块安装了默认的、异常处理程序链表上的最后一个异常处理程序。所有后来注册的异常处理程序都被安装在此链表中这个结点的前面。如果 lpfnEntryPoint 函数返回,那么表明线程一直运行到完成并且没有引发异常。这时 BaseProcessStart 调用 ExitThread 使线程退出。
另一方面,如果线程引发了一个异常但是没有异常处理程序来处理它时,该怎么办呢?这时,执行流程转到 __except 关键字后面的括号中。在 BaseProcessStart 中,这段代码调用 UnhandledExceptionFilter 这个 API,稍后我会讲到它。现在对于我们来说,重要的是 UnhandledExceptionFilter 这个API包含了默认的异常处理程序。
如果 UnhandledExceptionFilter 返回 EXCEPTION_EXECUTE_HANDLER,这时 BaseProcessStart 中的__except 块开始执行。而__except块所做的只是调用 ExitProcess 函数去终止当前进程。稍微想一下你就会理解了。常识告诉我们,如果一个进程引发了一个错误而没有异常处理程序去处理它,这个进程就会被系统终止。你在伪代码中看到的正是这些。
对于上述内容我还有一点要补充。如果引发错误的线程是作为服务来运行的,并且是基于线程的服务,那么__except 块并不调用 ExitProcess,而是调用 ExitThread。不能仅仅因为一个服务出错就终止整个服务进程。
UnhandledExceptionFilter 中的默认异常处理程序都做了什么呢?当我在一个技术讲座上问起这个问题时,响应者寥寥无几。几乎没有人知道当未处理异常发生时,到底操作系统的默认行为是什么。简单地演示一下这个默认的行为也许会让很多人豁然开朗。我运行一个故意引发错误的程序,其结果如下(如图八)。
图八 未处理异常对话框
表面上看,UnhandledExceptionFilter 显示了一个对话框告诉你发生了一个错误。这时,你被给予了一个机会要么终止出错进程,要么调试它。但是幕后发生了许多事情,我会在文章最后详细讲述它。
正如我让你看到的那样,当异常发生时,用户写的代码可以(并且通常是这样)获得机会执行。同样,在操作过程中,用户写的代码可以执行。此用户编写的代码也可能有缺陷并可能引发另一个异常。由于这个原因,异常处理回调函数也可以返回另外两个值: ExceptionNestedException 和 ExceptionCollidedUnwind。很明显,它们很重要。但这是非常复杂的问题,我并不打算在这里详细讲述它们。要想理解其基本概念真的太困难了。
编译器级的SEH
虽然我在前面偶尔也使用了__try 和__except,但迄今为止几乎我写的所有内容都是关于操作系统方面对 SEH 的实现。然而看一下我那两个使用操作系统的原始 SEH 的小程序别扭的样子,编译器对这个功能进行封装实在是非常有必要的。现在让我们来看一下 Visual C++ 是如何在操作系统对 SEH 功能实现的基础上来创建它自己的结构化异常处理支持的。
在继续往下讨论之前,记住其它编译器可以使用原始的系统 SEH 来做一些完全不同的事情这一点是非常重要的。没有谁规定编译器必须实现 Win32 SDK 文档中描述的__try/__except 模型。例如 Visual Basic 5.0 在它的运行时代码中使用了结构化异常处理,但是那里的数据结构和算法与我这里要讲的完全不同。
如果你把 Win32 SDK 文档中关于结构化异常处理方面的内容从头到尾读一遍,一定会遇到下面所谓的“基于帧”的异常处理程序模型:
- __try {
- // 这里是被保护的代码
- }
- __except (过滤器表达式) {
- // 这里是异常处理程序代码
- }
简单地说,某个函数__try 块中的所有代码是由 EXCEPTION_REGISTRATION 结构来保护的,该结构建立在此函数的堆栈帧上。在函数的入口处,这个新的 EXCEPTION_REGISTRATION 结构被放在异常处理程序链表的头部。在__try 块结束后,相应的 EXCEPTION_REGISTRATION 结构从这个链表的头部被移除。正如我前面所说,异常处理程序链表的头部被保存在 FS:[0] 处。因此,如果你在调试器中单步跟踪时能看到类似下面的指令
- MOV DWORD PTR FS:[00000000],ESP
- 或者
- MOV DWORD PTR FS:[00000000],ECX
就能非常确定这段代码正在进入或退出一个__try/__except块。
既然一个__try 块对应着堆栈上的一个 EXCEPTION_REGISTRATION 结构,那么 EXCEPTION_REGISTRATION 结构中的回调函数又如何呢?使用 Win32 的术语来说,异常处理回调函数对应的是过滤器表达式(filter-expression)代码。事实上,过滤器表达式就是__except 关键字后面的小括号中的代码。就是这个过滤器表达式代码决定了后面的大括号中的代码是否执行。
由于过滤器表达式代码是你自己写的,你当然可以决定在你的代码中的某个地方是否处理某个特定的异常。它可以简单的只是一句 “EXCEPTION_EXECUTE_HANDLER”,也可以先调用一个把p计算到20,000,000位的函数,然后再返回一个值来告诉操作系统下一步做什么。随你的便。关键是你的过滤器表达式代码必须是我前面讲的有效的异常处理回调函数。
我刚才讲的虽然相当简单,但那只不过是隔着有色玻璃看世界罢了。现实是非常复杂的。首先,你的过滤器表达式代码并不是被操作系统直接调用的。事实上,各个 EXCEPTION_REGISTRATION 结构的 handler 域都指向了同一个函数。这个函数在 Visual C++ 的运行时库中,它被称为__except_handler3。正是这个__except_handler3 调用了你的过滤器表达式代码,我一会儿再接着说它。
对我前面的简单描述需要修正的另一个地方是,并不是每次进入或退出一个__try 块时就创建或撤销一个 EXCEPTION_REGISTRATION 结构。相反,在使用 SEH 的任何函数中只创建一个 EXCEPTION_REGISTRATION 结构。换句话说,你可以在一个函数中使用多个 __try/__except 块,但是在堆栈上只创建一个 EXCEPTION_REGISTRATION 结构。同样,你可以在一个函数中嵌套使用 __try 块,但 Visual C++ 仍旧只是创建一个 EXCEPTION_REGISTRATION 结构。
如果整个 EXE 或 DLL 只需要单个的异常处理程序(__except_handler3),同时,如果单个的 EXCEPTION_REGISTRATION 结构就能处理多个__try 块的话,很明显,这里面还有很多东西我们不知道。这个技巧是通过一个通常情况下看不到的表中的数据来完成的。由于本文的目的就是要深入探索结构化异常处理,那就让我们来看一看这些数据结构吧。
扩展的异常处理帧
Visual C++ 的 SEH 实现并没有使用原始的 EXCEPTION_REGISTRATION 结构。它在这个结构的末尾添加了一些附加数据。这些附加数据正是允许单个函数(__except_handler3)处理所有异常并将执行流程传递到相应的过滤器表达式和__except 块的关键。我在 Visual C++ 运行时库源代码中的 EXSUP.INC 文件中找到了有关 Visual C++ 扩展的 EXCEPTION_REGISTRATION 结构格式的线索。在这个文件中,你会看到以下定义(已经被注释掉了):
- ;struct _EXCEPTION_REGISTRATION{
- ; struct _EXCEPTION_REGISTRATION *prev;
- ; void (*handler)( PEXCEPTION_RECORD,
- ; PEXCEPTION_REGISTRATION,
- ; PCONTEXT,
- ; PEXCEPTION_RECORD);
- ; struct scopetable_entry *scopetable;
- ; int trylevel;
- ; int _ebp;
- ; PEXCEPTION_POINTERS xpointers;
- ;};
在前面你已经见过前两个域:prev 和 handler。它们组成了基本的 EXCEPTION_REGISTRATION 结构。后面三个域:scopetable(作用域表)、trylevel 和_ebp 是新增加的。scopetable 域指向一个 scopetable_entry 结构数组,而 trylevel 域实际上是这个数组的索引。最后一个域_ebp,是 EXCEPTION_REGISTRATION 结构创建之前栈帧指针(EBP)的值。
_ebp 域成为扩展的 EXCEPTION_REGISTRATION 结构的一部分并非偶然。它是通过 PUSH EBP 这条指令被包含进这个结构中的,而大多数函数开头都是这条指令(通常编译器并不为使用FPO优化的函数生成标准的堆栈帧,这样其第一条指令可能不是 PUSH EBP。但是如果使用了SEH的话,那么无论你是否使用了FPO优化,编译器一定生成标准的堆栈帧)。这条指令可以使 EXCEPTION_REGISTRATION 结构中所有其它的域都可以用一个相对于栈帧指针(EBP)的负偏移来访问。例如 trylevel 域在 [EBP-04]处,scopetable 指针在[EBP-08]处,等等。(也就是说,这个结构是从[EBP-10H]处开始的。)
紧跟着扩展的 EXCEPTION_REGISTRATION 结构下面,Visual C++ 压入了另外两个值。紧跟着(即[EBP-14H]处)的一个DWORD,是为一个指向 EXCEPTION_POINTERS 结构(一个标准的Win32 结构)的指针所保留的空间。这个指针就是你调用 GetExceptionInformation 这个API时返回的指针。尽管SDK文档暗示 GetExceptionInformation 是一个标准的 Win32 API,但事实上它是一个编译器内联函数。当你调用这个函数时,Visual C++ 生成以下代码:
- MOV EAX,DWORD PTR [EBP-14]
GetExceptionInformation 是一个编译器内联函数,与它相关的 GetExceptionCode 函数也是如此。此函数实际上只是返回 GetExceptionInformation 返回的数据结构(EXCEPTION_POINTERS)中的一个结构(EXCEPTION_RECORD)中的一个域(ExceptionCode)的值。当 Visual C++ 为 GetExceptionCode 函数生成下面的指令时,它到底是想干什么?我把这个问题留给读者。(现在就能理解为什么SDK文档提醒我们要注意这两个函数的使用范围了。)
- MOV EAX,DWORD PTR [EBP-14] ; 执行完毕,EAX指向EXCEPTION_POINTERS结构
- MOV EAX,DWORD PTR [EAX] ; 执行完毕,EAX指向EXCEPTION_RECORD结构
- MOV EAX,DWORD PTR [EAX] ; 执行完毕,EAX中是ExceptionCode的值
现在回到扩展的 EXCEPTION_REGISTRATION 结构上来。在这个结构开始前的8个字节处(即[EBP-18H]处),Visual C++ 保留了一个DWORD来保存所有prolog代码执行完毕之后的堆栈指针(ESP)的值(实际生成的指令为MOV DWORD PTR [EBP-18H],ESP)。这个DWORD中保存的值是函数执行时ESP寄存器的正常值(除了在准备调用其它函数时把参数压入堆栈这个过程会改变 ESP寄存器的值并在函数返回时恢复它的值外,函数在执行过程中一般不改变ESP寄存器的值)。
看起来好像我一下子给你灌输了太多的信息,我承认。在继续下去之前,让我们先暂停,来回顾一下 Visual C++ 为使用结构化异常处理的函数生成的标准异常堆栈帧,它看起来像下面这个样子:
- EBP-00 _ebp
- EBP-04 trylevel
- EBP-08 scopetable数组指针
- EBP-0C handler函数地址
- EBP-10指向前一个EXCEPTION_REGISTRATION结构
- EBP-14 GetExceptionInformation
- EBP-18 栈帧中的标准ESP
在操作系统看来,只存在组成原始 EXCEPTION_REGISTRATION 结构的两个域:即[EBP-10h]处的prev指针和[EBP-0Ch]处的handler函数指针。栈帧中的其它所有内容是针对于Visual C++的。把这个Visual C++生成的标准异常堆栈帧记到脑子里之后,让我们来看一下真正实现编译器层面SEH的这个Visual C++运行时库例程——__except_handler3。
__except_handler3 和 scopetable
我真的很希望让你看一看Visual C++运行时库源代码,让你自己好好研究一下__except_handler3函数,但是我办不到。因为 Microsoft并没有提供。在这里你就将就着看一下我为__except_handler3函数写的伪代码吧:。
图九 __except_handler3函数的伪代码:
- int __except_handler3(
- struct _EXCEPTION_RECORD * pExceptionRecord,
- struct EXCEPTION_REGISTRATION * pRegistrationFrame,
- struct _CONTEXT *pContextRecord,
- void * pDispatcherContext )
- {
- LONG filterFuncRet;
- LONG trylevel;
- EXCEPTION_POINTERS exceptPtrs;
- PSCOPETABLE pScopeTable;
- CLD // 将方向标志复位(不测试任何条件!)
- // 如果没有设置EXCEPTION_UNWINDING标志或EXCEPTION_EXIT_UNWIND标志
- // 表明这是第一次调用这个处理程序(也就是说,并非处于异常展开阶段)
- if ( ! (pExceptionRecord->ExceptionFlags
- & (EXCEPTION_UNWINDING | EXCEPTION_EXIT_UNWIND)) )
- {
- // 在堆栈上创建一个EXCEPTION_POINTERS结构
- exceptPtrs.ExceptionRecord = pExceptionRecord;
- exceptPtrs.ContextRecord = pContextRecord;
- // 把前面定义的EXCEPTION_POINTERS结构的地址放在比
- // establisher栈帧低4个字节的位置上。参考前面我讲
- // 的编译器为GetExceptionInformation生成的汇编代
- // 码*(PDWORD)((PBYTE)pRegistrationFrame - 4) = &exceptPtrs;
- // 获取初始的“trylevel”值
- trylevel = pRegistrationFrame->trylevel;
- // 获取指向scopetable数组的指针
- scopeTable = pRegistrationFrame->scopetable;
- search_for_handler:
- if ( pRegistrationFrame->trylevel != TRYLEVEL_NONE )
- {
- if ( pRegistrationFrame->scopetable[trylevel].lpfnFilter )
- {
- PUSH EBP // 保存这个栈帧指针
- // !!!非常重要!!!切换回原来的EBP。正是这个操作才使得
- // 栈帧上的所有局部变量能够在异常发生后仍然保持它的值不变。
- EBP = &pRegistrationFrame->_ebp;
- // 调用过滤器函数
- filterFuncRet = scopetable[trylevel].lpfnFilter();
- POP EBP // 恢复异常处理程序的栈帧指针
- if ( filterFuncRet != EXCEPTION_CONTINUE_SEARCH )
- {
- if ( filterFuncRet < 0 ) // EXCEPTION_CONTINUE_EXECUTION
- return ExceptionContinueExecution;
- // 如果能够执行到这里,说明返回值为EXCEPTION_EXECUTE_HANDLER
- scopetable = pRegistrationFrame->scopetable;
- // 让操作系统清理已经注册的栈帧,这会使本函数被递归调用
- __global_unwind2( pRegistrationFrame );
- // 一旦执行到这里,除最后一个栈帧外,所有的栈帧已经
- // 被清理完毕,流程要从最后一个栈帧继续执行
- EBP = &pRegistrationFrame->_ebp;
- __local_unwind2( pRegistrationFrame, trylevel );
- // NLG = "non-local-goto" (setjmp/longjmp stuff)
- __NLG_Notify( 1 ); // EAX = scopetable->lpfnHandler
- // 把当前的trylevel设置成当找到一个异常处理程序时
- // SCOPETABLE中当前正在被使用的那一个元素的内容
- pRegistrationFrame->trylevel = scopetable->previousTryLevel;
- // 调用__except {}块,这个调用并不会返回
- pRegistrationFrame->scopetable[trylevel].lpfnHandler();
- }
- }
- scopeTable = pRegistrationFrame->scopetable;
- trylevel = scopeTable->previousTryLevel;
- goto search_for_handler;
- }
- else // trylevel == TRYLEVEL_NONE
- {
- return ExceptionContinueSearch;
- }
- }
- else // 设置了EXCEPTION_UNWINDING标志或EXCEPTION_EXIT_UNWIND标志
- {
- PUSH EBP // 保存EBP
- EBP = &pRegistrationFrame->_ebp; // 为调用__local_unwind2设置EBP
- __local_unwind2( pRegistrationFrame, TRYLEVEL_NONE )
- POP EBP // 恢复EBP
- return ExceptionContinueSearch;
- }
- }
虽然__except_handler3的代码看起来很多,但是记住一点:它只是一个我在文章开头讲过的异常处理回调函数。它同MYSEH.EXE和 MYSEH2.EXE中的异常回调函数都带有同样的四个参数。__except_handler3大体上可以由第一个if语句分为两部分。这是由于这个函数可以在两种情况下被调用,一次是正常调用,另一次是在展开阶段。其中大部分是在非展开阶段的回调。
__except_handler3一开始就在堆栈上创建了一个EXCEPTION_POINTERS结构,并用它的两个参数来对这个结构进行初始化。我在伪代码中把这个结构称为 exceptPrts,它的地址被放在[EBP-14h]处。你回忆一下前面我讲的编译器为 GetExceptionInformation和 GetExceptionCode 函数生成的汇编代码就会意识到,这实际上初始化了这两个函数使用的指针。
接着,__except_handler3从EXCEPTION_REGISTRATION帧中获取当前的trylevel(在[EBP-04h]处)。 trylevel变量实际是scopetable数组的索引,而正是这个数组才使得一个函数中的多个__try块和嵌套的__try块能够仅使用一个 EXCEPTION_REGISTRATION结构。每个scopetable元素结构如下:
- typedef struct _SCOPETABLE
- {
- DWORD previousTryLevel;
- DWORD lpfnFilter;
- DWORD lpfnHandler;
- } SCOPETABLE, *PSCOPETABLE;
SCOPETABLE结构中的第二个成员和第三个成员比较容易理解。它们分别是过滤器表达式代码的地址和相应的__except块的地址。但是prviousTryLevel成员有点复杂。总之一句话,它用于嵌套的__try块。这里的关键是函数中的每个__try块都有一个相应的SCOPETABLE结构。
正如我前面所说,当前的 trylevel 指定了要使用的scopetable数组的哪一个元素,最终也就是指定了过滤器表达式和__except块的地址。现在想像一下两个__try块嵌套的情形。如果内层__try块的过滤器表达式不处理某个异常,那外层__try块的过滤器表达式就必须处理它。那现在要问,__except_handler3是如何知道SCOPETABLE数组的哪个元素相应于外层的__try块的呢?答案是:外层__try块的索引由 SCOPETABLE结构的previousTryLevel域给出。利用这种机制,你可以嵌套任意层的__try块。previousTryLevel 域就好像是一个函数中所有可能的异常处理程序构成的线性链表中的结点一样。如果trylevel的值为0xFFFFFFFF(实际上就是-1,这个值在 EXSUP.INC中被定义为TRYLEVEL_NONE),标志着这个链表结束。
回到__except_handler3的代码中。在获取了当前的trylevel之后,它就调用相应的SCOPETABLE结构中的过滤器表达式代码。如果过滤器表达式返回EXCEPTION_CONTINUE_SEARCH,__exception_handler3 移向SCOPETABLE数组中的下一个元素,这个元素的索引由previousTryLevel域给出。如果遍历完整个线性链表(还记得吗?这个链表是由于在一个函数内部嵌套使用__try块而形成的)都没有找到处理这个异常的代码,__except_handler3返回DISPOSITION_CONTINUE_SEARCH(原文如此,但根据_except_handler函数的定义,这个返回值应该为ExceptionContinueSearch。实际上这两个常量的值是一样的。我在伪代码中已经将其改正过来了),这导致系统移向下一个EXCEPTION_REGISTRATION帧(这个链表是由于函数嵌套调用而形成的)。
如果过滤器表达式返回EXCEPTION_EXECUTE_HANDLER,这意味着异常应该由相应的__except块处理。它同时也意味着所有前面的EXCEPTION_REGISTRATION帧都应该从链表中移除,并且相应的__except块都应该被执行。第一个任务通过调用__global_unwind2来完成的,后面我会讲到这个函数。跳过这中间的一些清理代码,流程离开__except_handler3转向__except块。令人奇怪的是,流程并不从__except块中返回,虽然是 __except_handler3使用CALL指令调用了它。
当前的trylevel值是如何被设置的呢?它实际上是由编译器隐含处理的。编译器非常机灵地修改这个扩展的EXCEPTION_REGISTRATION 结构中的trylevel域的值(实际上是生成修改这个域的值的代码)。如果你检查编译器为使用SEH的函数生成的汇编代码,就会在不同的地方都看到修改这个位于[EBP-04h]处的trylevel域的值的代码。
__except_handler3是如何做到既通过CALL指令调用__except块而又不让执行流程返回呢?由于CALL指令要向堆栈中压入了一个返回地址,你可以想象这有可能破坏堆栈。如果你检查一下编译器为__except块生成的代码,你会发现它做的第一件事就是将EXCEPTION_REGISTRATION结构下面8个字节处(即[EBP-18H]处)的一个DWORD值加载到ESP寄存器中(实际代码为MOV ESP,DWORD PTR [EBP-18H]),这个值是在函数的 prolog 代码中被保存在这个位置的(实际代码为MOV DWORD PTR [EBP-18H],ESP)。
ShowSEHFrames 程序
如果你现在觉得已经被EXCEPTION_REGISTRATION、scopetable、trylevel、过滤器表达式以及展开等等之类的词搞得晕头转向的话,那和我最初的感觉一样。但是编译器层面的结构化异常处理方面的知识并不适合一点一点的学。除非你从整体上理解它,否则有很多内容单独看并没有什么意义。当面对大堆的理论时,我最自然的做法就是写一些应用我学到的理论方面的程序。如果它能够按照预料的那样工作,我就知道我的理解(通常)是正确的。
下面是ShowSEHFrame.EXE的源代码。它使用__try/__except块设置了好几个 Visual C++ SEH 帧。然后它显示每一个帧以及Visual C++为每个帧创建的scopetable的相关信息。这个程序本身并不生成也不依赖任何异常。相反,我使用了多个__try块以强制Visual C++生成多个 EXCEPTION_REGISTRATION 帧以及相应的 scopetable。
- //ShowSEHFrames.CPP
- //=========================================================
- // ShowSEHFrames - Matt Pietrek 1997
- // Microsoft Systems Journal, February 1997
- // FILE: ShowSEHFrames.CPP
- // 使用命令行CL ShowSehFrames.CPP进行编译
- //=========================================================
- #define WIN32_LEAN_AND_MEAN
- #include <windows.h>
- #include <stdio.h>
- #pragma hdrstop
- //-------------------------------------------------------------------
- // 本程序仅适用于Visual C++,它使用的数据结构是特定于Visual C++的
- //-------------------------------------------------------------------
- #ifndef _MSC_VER
- #error Visual C++ Required (Visual C++ specific information is displayed)
- #endif
- //-------------------------------------------------------------------
- // 结构定义
- //-------------------------------------------------------------------
- // 操作系统定义的基本异常帧
- struct EXCEPTION_REGISTRATION
- {
- EXCEPTION_REGISTRATION* prev;
- FARPROC handler;
- };
- // Visual C++扩展异常帧指向的数据结构
- struct scopetable_entry
- {
- DWORD previousTryLevel;
- FARPROC lpfnFilter;
- FARPROC lpfnHandler;
- };
- // Visual C++使用的扩展异常帧
- struct VC_EXCEPTION_REGISTRATION : EXCEPTION_REGISTRATION
- {
- scopetable_entry * scopetable;
- int trylevel;
- int _ebp;
- };
- //----------------------------------------------------------------
- // 原型声明
- //----------------------------------------------------------------
- // __except_handler3是Visual C++运行时库函数,我们想打印出它的地址
- // 但是它的原型并没有出现在任何头文件中,所以我们需要自己声明它。
- extern "C" int _except_handler3(PEXCEPTION_RECORD,
- EXCEPTION_REGISTRATION *,
- PCONTEXT,
- PEXCEPTION_RECORD);
- //-------------------------------------------------------------
- // 代码
- //-------------------------------------------------------------
- //
- // 显示一个异常帧及其相应的scopetable的信息
- //
- void ShowSEHFrame( VC_EXCEPTION_REGISTRATION * pVCExcRec )
- {
- printf( "Frame: %08X Handler: %08X Prev: %08X Scopetable: %08X/n",
- pVCExcRec, pVCExcRec->handler, pVCExcRec->prev,
- pVCExcRec->scopetable );
- scopetable_entry * pScopeTableEntry = pVCExcRec->scopetable;
- for ( unsigned i = 0; i <= pVCExcRec->trylevel; i++ )
- {
- printf( " scopetable[%u] PrevTryLevel: %08X "
- "filter: %08X __except: %08X/n", i,
- pScopeTableEntry->previousTryLevel,
- pScopeTableEntry->lpfnFilter,
- pScopeTableEntry->lpfnHandler );
- pScopeTableEntry++;
- }
- printf( "/n" );
- }
- //
- // 遍历异常帧的链表,按顺序显示它们的信息
- //
- void WalkSEHFrames( void )
- {
- VC_EXCEPTION_REGISTRATION * pVCExcRec;
- // 打印出__except_handler3函数的位置
- printf( "_except_handler3 is at address: %08X/n", _except_handler3 );
- printf( "/n" );
- // 从FS:[0]处获取指向链表头的指针
- __asm mov eax, FS:[0]
- __asm mov [pVCExcRec], EAX
- // 遍历异常帧的链表。0xFFFFFFFF标志着链表的结尾
- while ( 0xFFFFFFFF != (unsigned)pVCExcRec )
- {
- ShowSEHFrame( pVCExcRec );
- pVCExcRec = (VC_EXCEPTION_REGISTRATION *)(pVCExcRec->prev);
- }
- }
- void Function1( void )
- {
- // 嵌套3层__try块以便强制为scopetable数组产生3个元素
- __try
- {
- __try
- {
- __try
- {
- WalkSEHFrames(); // 现在显示所有的异常帧的信息
- } __except( EXCEPTION_CONTINUE_SEARCH )
- {}
- } __except( EXCEPTION_CONTINUE_SEARCH )
- {}
- } __except( EXCEPTION_CONTINUE_SEARCH )
- {}
- }
- int main()
- {
- int i;
- // 使用两个__try块(并不嵌套),这导致为scopetable数组生成两个元素
- __try
- {
- i = 0x1234;
- } __except( EXCEPTION_CONTINUE_SEARCH )
- {
- i = 0x4321;
- }
- __try
- {
- Function1(); // 调用一个设置更多异常帧的函数
- } __except( EXCEPTION_EXECUTE_HANDLER )
- {
- // 应该永远不会执行到这里,因为我们并没有打算产生任何异常
- printf( "Caught Exception in main/n" );
- }
- return 0;
- }
ShowSEHFrames程序中比较重要的函数是WalkSEHFrames和ShowSEHFrame。WalkSEHFrames函数首选打印出 __except_handler3的地址,打印它的原因很快就清楚了。接着,它从FS:[0]处获取异常链表的头指针,然后遍历该链表。此链表中每个结点都是一个VC_EXCEPTION_REGISTRATION类型的结构,它是我自己定义的,用于描述Visual C++的异常处理帧。对于这个链表中的每个结点,WalkSEHFrames都把指向这个结点的指针传递给ShowSEHFrame函数。
ShowSEHFrame函数一开始就打印出异常处理帧的地址、异常处理回调函数的地址、前一个异常处理帧的地址以及scopetable的地址。接着,对于每个 scopetable数组中的元素,它都打印出其priviousTryLevel、过滤器表达式的地址以及相应的__except块的地址。我是如何知道scopetable数组中有多少个元素的呢?其实我并不知道。但是我假定VC_EXCEPTION_REGISTRATION结构中的当前trylevel域的值比scopetable数组中的元素总数少1。
图十一是 ShowSEHFrames 的运行结果。首先检查以“Frame:”开头的每一行,你会发现它们显示的异常处理帧在堆栈上的地址呈递增趋势,并且在前三个帧中,它们的异常处理程序的地址是一样的(都是004012A8)。再看输出的开始部分,你会发现这个004012A8不是别的,它正是 Visual C++运行时库函数__except_handler3的地址。这证明了我前面所说的单个回调函数处理所有异常这一点。
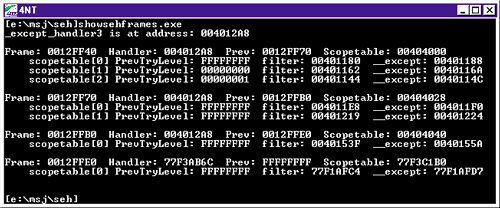
图十一 ShowSEHFrames运行结果
你可能想知道为什么明明 ShowSEHFrames 程序只有两个函数使用SEH,但是却有三个异常处理帧使用__except_handler3作为它们的异常回调函数。实际上第三个帧来自 Visual C++ 运行时库。Visual C++ 运行时库源代码中的 CRT0.C 文件清楚地表明了对 main 或 WinMain 的调用也被一个__try/__except 块封装着。这个__try 块的过滤器表达式代码可以在 WINXFLTR.C文 件中找到。
回到 ShowSEHFrames 程序,注意到最后一个帧的异常处理程序的地址是 77F3AB6C,这与其它三个不同。仔细观察一下,你会发现这个地址在 KERNEL32.DLL 中。这个特别的帧就是由 KERNEL32.DLL 中的 BaseProcessStart 函数安装的,这在前面我已经说过。
展开
在挖掘展开(Unwinding)的实现代码之前让我们先来搞清楚它的意思。我在前面已经讲过所有可能的异常处理程序是如何被组织在一个由线程信息块的第一个DWORD(FS:[0])所指向的链表中的。由于针对某个特定异常的处理程序可能不在这个链表的开头,因此就需要从链表中依次移除实际处理异常的那个异常处理程序之前的所有异常处理程序。
正如你在Visual C++的__except_handler3函数中看到的那样,展开是由__global_unwind2这个运行时库(RTL)函数来完成的。这个函数只是对RtlUnwind这个未公开的API进行了非常简单的封装。(现在这个API已经被公开了,但给出的信息极其简单,详细信息可以参考最新的Platform SDK文档。)
- __global_unwind2(void * pRegistFrame)
- {
- _RtlUnwind( pRegistFrame, &__ret_label, 0, 0 );
- __ret_label:
- }
虽然从技术上讲RtlUnwind是一个KERNEL32函数,但它只是转发到了NTDLL.DLL中的同名函数上。下面是我为此函数写的伪代码。
RtlUnwind 函数的伪代码:
- void _RtlUnwind( PEXCEPTION_REGISTRATION pRegistrationFrame,
- PVOID returnAddr, // 并未使用!(至少是在i386机器上)
- PEXCEPTION_RECORD pExcptRec,
- DWORD _eax_value)
- {
- DWORD stackUserBase;
- DWORD stackUserTop;
- PEXCEPTION_RECORD pExcptRec;
- EXCEPTION_RECORD exceptRec;
- CONTEXT context;
- // 从FS:[4]和FS:[8]处获取堆栈的界限
- RtlpGetStackLimits( &stackUserBase, &stackUserTop );
- if ( 0 == pExcptRec ) // 正常情况
- {
- pExcptRec = &excptRec;
- pExcptRec->ExceptionFlags = 0;
- pExcptRec->ExceptionCode = STATUS_UNWIND;
- pExcptRec->ExceptionRecord = 0;
- pExcptRec->ExceptionAddress = [ebp+4]; // RtlpGetReturnAddress()—获取返回地址
- pExcptRec->ExceptionInformation[0] = 0;
- }
- if ( pRegistrationFrame )
- pExcptRec->ExceptionFlags |= EXCEPTION_UNWINDING;
- else // 这两个标志合起来被定义为EXCEPTION_UNWIND_CONTEXT
- pExcptRec->ExceptionFlags|=(EXCEPTION_UNWINDING|EXCEPTION_EXIT_UNWIND);
- context.ContextFlags =( CONTEXT_i486 | CONTEXT_CONTROL |
- CONTEXT_INTEGER | CONTEXT_SEGMENTS);
- RtlpCaptureContext( &context );
- context.Esp += 0x10;
- context.Eax = _eax_value;
- PEXCEPTION_REGISTRATION pExcptRegHead;
- pExcptRegHead = RtlpGetRegistrationHead(); // 返回FS:[0]的值
- // 开始遍历EXCEPTION_REGISTRATION结构链表
- while ( -1 != pExcptRegHead )
- {
- EXCEPTION_RECORD excptRec2;
- if ( pExcptRegHead == pRegistrationFrame )
- {
- NtContinue( &context, 0 );
- }
- else
- {
- // 如果存在某个异常帧在堆栈上的位置比异常链表的头部还低
- // 说明一定出现了错误
- if ( pRegistrationFrame && (pRegistrationFrame <= pExcptRegHead) )
- {
- // 生成一个异常
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.NumberParameters = 0;
- excptRec2.ExceptionCode = STATUS_INVALID_UNWIND_TARGET;
- excptRec2.ExceptionFlags = EXCEPTION_NONCONTINUABLE;
- RtlRaiseException( &exceptRec2 );
- }
- }
- PVOID pStack = pExcptRegHead + 8; // 8 = sizeof(EXCEPTION_REGISTRATION)
- // 确保pExcptRegHead在堆栈范围内,并且是4的倍数
- if ( (stackUserBase <= pExcptRegHead )
- && (stackUserTop >= pStack )
- && (0 == (pExcptRegHead & 3)) )
- {
- DWORD pNewRegistHead;
- DWORD retValue;
- retValue = RtlpExecutehandlerForUnwind(pExcptRec, pExcptRegHead, &context,
- &pNewRegistHead, pExceptRegHead->handler );
- if ( retValue != DISPOSITION_CONTINUE_SEARCH )
- {
- if ( retValue != DISPOSITION_COLLIDED_UNWIND )
- {
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.NumberParameters = 0;
- excptRec2.ExceptionCode = STATUS_INVALID_DISPOSITION;
- excptRec2.ExceptionFlags = EXCEPTION_NONCONTINUABLE;
- RtlRaiseException( &excptRec2 );
- }
- else
- pExcptRegHead = pNewRegistHead;
- }
- PEXCEPTION_REGISTRATION pCurrExcptReg = pExcptRegHead;
- pExcptRegHead = pExcptRegHead->prev;
- RtlpUnlinkHandler( pCurrExcptReg );
- }
- else // 堆栈已经被破坏!生成一个异常
- {
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.NumberParameters = 0;
- excptRec2.ExceptionCode = STATUS_BAD_STACK;
- excptRec2.ExceptionFlags = EXCEPTION_NONCONTINUABLE;
- RtlRaiseException( &excptRec2 );
- }
- }
- // 如果执行到这里,说明已经到了EXCEPTION_REGISTRATION
- // 结构链表的末尾,正常情况下不应该发生这种情况。
- //(因为正常情况下异常应该被处理,这样就不会到链表末尾)
- if ( -1 == pRegistrationFrame )
- NtContinue( &context, 0 );
- else
- NtRaiseException( pExcptRec, &context, 0 );
- }
- RtlUnwind函数的伪代码到这里就结束了,以下是它调用的几个函数的伪代码:
- PEXCEPTION_REGISTRATION RtlpGetRegistrationHead( void )
- {
- return FS:[0];
- }
- RtlpUnlinkHandler( PEXCEPTION_REGISTRATION pRegistrationFrame )
- {
- S:[0] = pRegistrationFrame->prev;
- }
- void RtlpCaptureContext( CONTEXT * pContext )
- {
- pContext->Eax = 0;
- pContext->Ecx = 0;
- pContext->Edx = 0;
- pContext->Ebx = 0;
- pContext->Esi = 0;
- pContext->Edi = 0;
- pContext->SegCs = CS;
- pContext->SegDs = DS;
- pContext->SegEs = ES;
- pContext->SegFs = FS;
- pContext->SegGs = GS;
- pContext->SegSs = SS;
- pContext->EFlags = flags; // 它对应的汇编代码为__asm{ PUSHFD / pop [xxxxxxxx] }
- pContext->Eip = 此函数的调用者的调用者的返回地址 // 读者看一下这个函数的
- pContext->Ebp = 此函数的调用者的调用者的EBP // 汇编代码就会清楚这一点
- pContext->Esp = pContext->Ebp + 8;
- }
虽然 RtlUnwind 函数的规模看起来很大,但是如果你按一定方法把它分开,其实并不难理解。它首先从FS:[4]和FS:[8]处获取当前线程堆栈的界限。它们对于后面要进行的合法性检查非常重要,以确保所有将要被展开的异常帧都在堆栈范围内。
RtlUnwind 接着在堆栈上创建了一个空的EXCEPTION_RECORD结构并把STATUS_UNWIND赋给它的ExceptionCode域,同时把 EXCEPTION_UNWINDING标志赋给它的 ExceptionFlags 域。指向这个结构的指针作为其中一个参数被传递给每个异常回调函数。然后,这个函数调用RtlCaptureContext函数来创建一个空的CONTEXT结构,这个结构也变成了在展开阶段调用每个异常回调函数时传递给它们的一个参数。
RtlUnwind函数的其余部分遍历EXCEPTION_REGISTRATION结构链表。对于其中的每个帧,它都调用 RtlpExecuteHandlerForUnwind 函数,后面我会讲到这个函数。正是这个函数带 EXCEPTION_UNWINDING 标志调用了异常处理回调函数。每次回调之后,它调用RtlpUnlinkHandler 移除相应的异常帧。
RtlUnwind 函数的第一个参数是一个帧的地址,当它遍历到这个帧时就停止展开异常帧。上面所说的这些代码之间还有一些安全性检查代码,它们用来确保不出问题。如果出现任何问题,RtlUnwind 就引发一个异常,指示出了什么问题,并且这个异常带有EXCEPTION_NONCONTINUABLE 标志。当一个进程被设置了这个标志时,它就不允许再运行,必须终止。
未处理异常
在文章的前面,我并没有全面描述 UnhandledExceptionFilter 这个 API。通常情况下你并不直接调用它(尽管你可以这么做)。大多数情况下它都是由 KERNEL32 中进行默认异常处理的过滤器表达式代码调用。前面 BaseProcessStart 函数的伪代码已经表明了这一点。
图十三是我为 UnhandledExceptionFilter 函数写的伪代码。这个API有点奇怪(至少在我看来是这样)。如果异常的类型是 EXCEPTION_ACCESS_VIOLATION,它就调用_BasepCheckForReadOnlyResource。虽然我没有提供这个函数的伪代码,但可以简要描述一下。如果是因为要对 EXE 或 DLL 的资源节(.rsrc)进行写操作而导致的异常,_BasepCurrentTopLevelFilter 就改变出错页面正常的只读属性,以便允许进行写操作。如果是这种特殊的情况,UnhandledExceptionFilter 返回 EXCEPTION_CONTINUE_EXECUTION,使系统重新执行出错指令。
图十三 UnHandledExceptionFilter 函数的伪代码
- UnhandledExceptionFilter( STRUCT _EXCEPTION_POINTERS *pExceptionPtrs )
- {
- PEXCEPTION_RECORD pExcptRec;
- DWORD currentESP;
- DWORD retValue;
- DWORD DEBUGPORT;
- DWORD dwTemp2;
- DWORD dwUseJustInTimeDebugger;
- CHAR szDbgCmdFmt[256]; // 从AeDebug这个注册表键值返回的字符串
- CHAR szDbgCmdLine[256]; // 实际的调试器命令行参数(已填入进程ID和事件ID)
- STARTUPINFO startupinfo;
- PROCESS_INFORMATION pi;
- HARDERR_STRUCT harderr; // ???
- BOOL fAeDebugAuto;
- TIB * pTib; // 线程信息块
- pExcptRec = pExceptionPtrs->ExceptionRecord;
- if ( (pExcptRec->ExceptionCode == EXCEPTION_ACCESS_VIOLATION)
- && (pExcptRec->ExceptionInformation[0]) )
- {
- retValue=BasepCheckForReadOnlyResource(pExcptRec->ExceptionInformation[1]);
- if ( EXCEPTION_CONTINUE_EXECUTION == retValue )
- return EXCEPTION_CONTINUE_EXECUTION;
- }
- // 查看这个进程是否运行于调试器下
- retValue = NtQueryInformationProcess(GetCurrentProcess(), ProcessDebugPort,
- &debugPort, sizeof(debugPort), 0 );
- if ( (retValue >= 0) && debugPort ) // 通知调试器
- return EXCEPTION_CONTINUE_SEARCH;
- // 用户调用SetUnhandledExceptionFilter了吗?
- // 如果调用了,那现在就调用他安装的异常处理程序
- if ( _BasepCurrentTopLevelFilter )
- {
- retValue = _BasepCurrentTopLevelFilter( pExceptionPtrs );
- if ( EXCEPTION_EXECUTE_HANDLER == retValue )
- return EXCEPTION_EXECUTE_HANDLER;
- if ( EXCEPTION_CONTINUE_EXECUTION == retValue )
- return EXCEPTION_CONTINUE_EXECUTION;
- // 只有返回值为EXCEPTION_CONTINUE_SEARCH时才会继续执行下去
- }
- // 调用过SetErrorMode(SEM_NOGPFAULTERRORBOX)吗?
- {
- harderr.elem0 = pExcptRec->ExceptionCode;
- harderr.elem1 = pExcptRec->ExceptionAddress;
- if ( EXCEPTION_IN_PAGE_ERROR == pExcptRec->ExceptionCode )
- harderr.elem2 = pExcptRec->ExceptionInformation[2];
- else
- harderr.elem2 = pExcptRec->ExceptionInformation[0];
- dwTemp2 = 1;
- fAeDebugAuto = FALSE;
- harderr.elem3 = pExcptRec->ExceptionInformation[1];
- pTib = FS:[18h];
- DWORD someVal = pTib->pProcess->0xC;
- if ( pTib->threadID != someVal )
- {
- __try
- {
- char szDbgCmdFmt[256];
- retValue = GetProfileStringA( "AeDebug", "Debugger", 0,
- szDbgCmdFmt, sizeof(szDbgCmdFmt)-1 );
- if ( retValue )
- dwTemp2 = 2;
- char szAuto[8];
- retValue = GetProfileStringA( "AeDebug", "Auto", "0",
- szAuto, sizeof(szAuto)-1 );
- if ( retValue )
- if ( 0 == strcmp( szAuto, "1" ) )
- if ( 2 == dwTemp2 )
- fAeDebugAuto = TRUE;
- }
- __except( EXCEPTION_EXECUTE_HANDLER )
- {
- ESP = currentESP;
- dwTemp2 = 1;
- fAeDebugAuto = FALSE;
- }
- }
- if ( FALSE == fAeDebugAuto )
- {
- retValue=NtRaiseHardError(STATUS_UNHANDLED_EXCEPTION | 0x10000000,
- 4, 0, &harderr,_BasepAlreadyHadHardError ? 1 : dwTemp2,
- &dwUseJustInTimeDebugger );
- }
- else
- {
- dwUseJustInTimeDebugger = 3;
- retValue = 0;
- }
- if (retValue >= 0 && (dwUseJustInTimeDebugger == 3)
- && (!_BasepAlreadyHadHardError)&&(!_BaseRunningInServerProcess))
- {
- _BasepAlreadyHadHardError = 1;
- SECURITY_ATTRIBUTES secAttr = { sizeof(secAttr), 0, TRUE };
- HANDLE hEvent = CreateEventA( &secAttr, TRUE, 0, 0 );
- memset( &startupinfo, 0, sizeof(startupinfo) );
- sprintf(szDbgCmdLine, szDbgCmdFmt, GetCurrentProcessId(), hEvent);
- startupinfo.cb = sizeof(startupinfo);
- startupinfo.lpDesktop = "Winsta0/Default"
- CsrIdentifyAlertableThread(); // ???
- retValue = CreateProcessA( 0, // 应用程序名称
- szDbgCmdLine, // 命令行
- 0, 0, // 进程和线程安全属性
- 1, // bInheritHandles
- 0, 0, // 创建标志、环境
- 0, // 当前目录
- &statupinfo, // STARTUPINFO
- &pi); // PROCESS_INFORMATION
- if ( retValue && hEvent )
- {
- NtWaitForSingleObject( hEvent, 1, 0 );
- return EXCEPTION_CONTINUE_SEARCH;
- }
- }
- if ( _BasepAlreadyHadHardError )
- NtTerminateProcess(GetCurrentProcess(), pExcptRec->ExceptionCode);
- }
- return EXCEPTION_EXECUTE_HANDLER;
- }
- LPTOP_LEVEL_EXCEPTION_FILTER
- SetUnhandledExceptionFilter(
- LPTOP_LEVEL_EXCEPTION_FILTER lpTopLevelExceptionFilter )
- {
- // _BasepCurrentTopLevelFilter是KERNEL32.DLL中的一个全局变量
- LPTOP_LEVEL_EXCEPTION_FILTER previous= _BasepCurrentTopLevelFilter;
- // 设置为新值
- _BasepCurrentTopLevelFilter = lpTopLevelExceptionFilter;
- return previous; // 返回以前的值
- }
UnhandledExceptionFilter接下来的任务是确定进程是否运行于Win32调试器下。也就是进程的创建标志中是否带有标志DEBUG_PROCESS或DEBUG_ONLY_THIS_PROCESS。它使用NtQueryInformationProcess函数来确定进程是否正在被调试,我在本月的Under the Hood专栏中讲解了这个函数。如果正在被调试,UnhandledExceptionFilter就返回 EXCEPTION_CONTINUE_SEARCH,这告诉系统去唤醒调试器并告诉它在被调试程序(debuggee)中产生了一个异常。
UnhandledExceptionFilter接下来调用用户安装的未处理异常过滤器(如果存在的话)。通常情况下,用户并没有安装回调函数,但是用户可以调用 SetUnhandledExceptionFilter这个API来安装。上面我也提供了这个API的伪代码。这个函数只是简单地用用户安装的回调函数的地址来替换一个全局变量,并返回替换前的值。
有了初步的准备之后,UnhandledExceptionFilter就开始做它的主要工作:用一个时髦的应用程序错误对话框来通知你犯了低级的编程错误。有两种方法可以避免出现这个对话框。第一种方法是调用SetErrorMode函数并指定SEM_NOGPFAULTERRORBOX标志。另一种方法是将AeDebug子键下的Auto的值设为1。此时UnhandledExceptionFilter跳过应用程序错误对话框直接启动AeDebug 子键下的Debugger的值所指定的调试器。如果你熟悉“即时调试(Just In Time Debugging,JIT)”的话,这就是操作系统支持它的地方。接下来我会详细讲。
大多数情况下,上面的两个条件都为假。这样UnhandledExceptionFilter就调用NTDLL.DLL中的 NtRaiseHardError函数。正是这个函数产生了应用程序错误对话框。这个对话框等待你单击“确定”按钮来终止进程,或者单击“取消”按钮来调试它。(单击“取消”按钮而不是“确定”按钮来加载调试器好像有点颠倒了,可能这只是我个人的感觉吧。)
如果你单击“确定”,UnhandledExceptionFilter就返回EXCEPTION_EXECUTE_HANDLER。调用UnhandledExceptionFilter 的进程通常通过终止自身来作为响应(正像你在BaseProcessStart的伪代码中看到的那样)。这就产生了一个有趣的问题——大多数人都认为是系统终止了产生未处理异常的进程,而实际上更准确的说法应该是,系统进行了一些设置使得产生未处理异常的进程将自身终止掉了。
UnhandledExceptionFilter执行时真正有意思的部分是当你单击应用程序错误对话框中的“取消”按钮,此时系统将调试器附加(attach)到出错进程上。这段代码首先调用 CreateEvent来创建一个事件内核对象,调试器成功附加到出错进程之后会将此事件对象变成有信号状态。这个事件句柄以及出错进程的ID都被传到 sprintf函数,由它将其格式化成一个命令行,用来启动调试器。一切就绪之后,UnhandledExceptionFilter就调用 CreateProcess来启动调试器。如果CreateProcess成功,它就调用NtWaitForSingleObject来等待前面创建的那个事件对象。此时这个调用被阻塞,直到调试器进程将此事件变成有信号状态,以表明它已经成功附加到出错进程上。UnhandledExceptionFilter函数中还有一些其它的代码,我在这里只讲重要的。
进入地狱
如果你已经走了这么远,不把整个过程讲完对你有点不公平。我已经讲了当异常发生时操作系统是如何调用用户定义的回调函数的。我也讲了这些回调的内部情况,以及编译器是如何使用它们来实现__try和__except的。我甚至还讲了当某个异常没有被处理时所发生的情况以及系统所做的扫尾工作。剩下的就只有异常回调过程最初是从哪里开始的这个问题了。好吧,让我们深入系统内部来看一下结构化异常处理的开始阶段吧。
图十四是我为 KiUserExceptionDispatcher 函数和一些相关函数写的伪代码。这个函数在NTDLL.DLL中,它是异常处理执行的起点。为了绝对准确起见,我必须指出:刚才说的并不是绝对准确。例如在Intel平台上,一个异常导致CPU将控制权转到ring 0(0特权级,即内核模式)的一个处理程序上。这个处理程序由中断描述符表(Interrupt Descriptor Table,IDT)中的一个元素定义,它是专门用来处理相应异常的。我跳过所有的内核模式代码,假设当异常发生时CPU直接将控制权转到了 KiUserExceptionDispatcher 函数。
图十四 KiUserExceptionDispatcher 的伪代码:
- KiUserExceptionDispatcher( PEXCEPTION_RECORD pExcptRec, CONTEXT * pContext )
- {
- DWORD retValue;
- // 注意:如果异常被处理,那么 RtlDispatchException 函数就不会返回
- if ( RtlDispatchException( pExceptRec, pContext ) )
- retValue = NtContinue( pContext, 0 );
- else
- retValue = NtRaiseException( pExceptRec, pContext, 0 );
- EXCEPTION_RECORD excptRec2;
- excptRec2.ExceptionCode = retValue;
- excptRec2.ExceptionFlags = EXCEPTION_NONCONTINUABLE;
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.NumberParameters = 0;
- RtlRaiseException( &excptRec2 );
- }
- int RtlDispatchException( PEXCEPTION_RECORD pExcptRec, CONTEXT * pContext )
- {
- DWORD stackUserBase;
- DWORD stackUserTop;
- PEXCEPTION_REGISTRATION pRegistrationFrame;
- DWORD hLog;
- // 从FS:[4]和FS:[8]处获取堆栈的界限
- RtlpGetStackLimits( &stackUserBase, &stackUserTop );
- pRegistrationFrame = RtlpGetRegistrationHead();
- while ( -1 != pRegistrationFrame )
- {
- PVOID justPastRegistrationFrame = &pRegistrationFrame + 8;
- if ( stackUserBase > justPastRegistrationFrame )
- {
- pExcptRec->ExceptionFlags |= EH_STACK_INVALID;
- return DISPOSITION_DISMISS; // 0
- }
- if ( stackUsertop < justPastRegistrationFrame )
- {
- pExcptRec->ExceptionFlags |= EH_STACK_INVALID;
- return DISPOSITION_DISMISS; // 0
- }
- if ( pRegistrationFrame & 3 ) // 确保堆栈按DWORD对齐
- {
- pExcptRec->ExceptionFlags |= EH_STACK_INVALID;
- return DISPOSITION_DISMISS; // 0
- }
- if ( someProcessFlag )
- {
- hLog = RtlpLogExceptionHandler( pExcptRec, pContext, 0,
- pRegistrationFrame, 0x10 );
- }
- DWORD retValue, dispatcherContext;
- retValue= RtlpExecuteHandlerForException(pExcptRec, pRegistrationFrame,
- pContext, &dispatcherContext,
- pRegistrationFrame->handler );
- if ( someProcessFlag )
- RtlpLogLastExceptionDisposition( hLog, retValue );
- if ( 0 == pRegistrationFrame )
- {
- pExcptRec->ExceptionFlags &= ~EH_NESTED_CALL; // 关闭标志
- }
- EXCEPTION_RECORD excptRec2;
- DWORD yetAnotherValue = 0;
- if ( DISPOSITION_DISMISS == retValue )
- {
- if ( pExcptRec->ExceptionFlags & EH_NONCONTINUABLE )
- {
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.ExceptionNumber = STATUS_NONCONTINUABLE_EXCEPTION;
- excptRec2.ExceptionFlags = EH_NONCONTINUABLE;
- excptRec2.NumberParameters = 0;
- RtlRaiseException( &excptRec2 );
- }
- else
- return DISPOSITION_CONTINUE_SEARCH;
- }
- else if ( DISPOSITION_CONTINUE_SEARCH == retValue )
- {}
- else if ( DISPOSITION_NESTED_EXCEPTION == retValue )
- {
- pExcptRec->ExceptionFlags |= EH_EXIT_UNWIND;
- if ( dispatcherContext > yetAnotherValue )
- yetAnotherValue = dispatcherContext;
- }
- else // DISPOSITION_COLLIDED_UNWIND
- {
- excptRec2.ExceptionRecord = pExcptRec;
- excptRec2.ExceptionNumber = STATUS_INVALID_DISPOSITION;
- excptRec2.ExceptionFlags = EH_NONCONTINUABLE;
- excptRec2.NumberParameters = 0;
- RtlRaiseException( &excptRec2 );
- }
- pRegistrationFrame = pRegistrationFrame->prev; // 转到前一个帧
- }
- return DISPOSITION_DISMISS;
- }
- _RtlpExecuteHandlerForException: // 处理异常(第一次)
- MOV EDX,XXXXXXXX
- JMP ExecuteHandler
- RtlpExecutehandlerForUnwind: // 处理展开(第二次)
- MOV EDX,XXXXXXXX
- int ExecuteHandler( PEXCEPTION_RECORD pExcptRec,
- PEXCEPTION_REGISTRATION pExcptReg,
- CONTEXT * pContext,
- PVOID pDispatcherContext,
- FARPROC handler ) // 实际上是指向_except_handler()的指针
- {
- // 安装一个EXCEPTION_REGISTRATION帧,EDX指向相应的handler代码
- PUSH EDX
- PUSH FS:[0]
- MOV FS:[0],ESP
- // 调用异常处理回调函数
- EAX = handler( pExcptRec, pExcptReg, pContext, pDispatcherContext );
- // 移除EXCEPTION_REGISTRATION帧
- MOV ESP,DWORD PTR FS:[00000000]
- POP DWORD PTR FS:[00000000]
- return EAX;
- }
- _RtlpExecuteHandlerForException使用的异常处理程序:
- {
- // 如果设置了展开标志,返回DISPOSITION_CONTINUE_SEARCH
- // 否则,给pDispatcherContext赋值并返回DISPOSITION_NESTED_EXCEPTION
- return pExcptRec->ExceptionFlags & EXCEPTION_UNWIND_CONTEXT ?
- DISPOSITION_CONTINUE_SEARC : ( *pDispatcherContext =
- pRegistrationFrame->scopetable,
- DISPOSITION_NESTED_EXCEPTION );
- }
- _RtlpExecuteHandlerForUnwind使用的异常处理程序:
- {
- // 如果设置了展开标志,返回DISPOSITION_CONTINUE_SEARCH
- // 否则,给pDispatcherContext赋值并返回DISPOSITION_COLLIDED_UNWIND
- return pExcptRec->ExceptionFlags & EXCEPTION_UNWIND_CONTEXT ?
- DISPOSITION_CONTINUE_SEARCH : ( *pDispatcherContext =
- pRegistrationFrame->scopetable,
- DISPOSITION_COLLIDED_UNWIND );
- }
KiUserExceptionDispatcher 的核心是对 RtlDispatchException 的调用。这拉开了搜索已注册的异常处理程序的序幕。如果某个处理程序处理这个异常并继续执行,那么对 RtlDispatchException 的调用就不会返回。如果它返回了,只有两种可能:或者调用了NtContinue以便让进程继续执行,或者产生了新的异常。如果是这样,那异常就不能再继续处理了,必须终止进程。
现在把目光对准 RtlDispatchException 函数的代码,这就是我通篇提到的遍历异常帧的代码。这个函数获取一个指向EXCEPTION_REGISTRATION 结构链表的指针,然后遍历此链表以寻找一个异常处理程序。由于堆栈可能已经被破坏了,所以这个例程非常谨慎。在调用每个EXCEPTION_REGISTRATION结构中指定的异常处理程序之前,它确保这个结构是按DWORD对齐的,并且是在线程的堆栈之中,同时在堆栈中比前一个EXCEPTION_REGISTRATION结构高。
RtlDispatchException并不直接调用EXCEPTION_REGISTRATION结构中指定的异常处理程序。相反,它调用 RtlpExecuteHandlerForException来完成这个工作。根据RtlpExecuteHandlerForException的执行情况,RtlDispatchException或者继续遍历异常帧,或者引发另一个异常。这第二次的异常表明异常处理程序内部出现了错误,这样就不能继续执行下去了。
RtlpExecuteHandlerForException的代码与RtlpExecuteHandlerForUnwind的代码极其相似。你可能会回忆起来在前面讨论展开时我提到过它。这两个“函数”都只是简单地给EDX寄存器加载一个不同的值然后就调用ExecuteHandler函数。也就是说,RtlpExecuteHandlerForException和RtlpExecuteHandlerForUnwind都是 ExecuteHanlder这个公共函数的前端。
ExecuteHandler查找EXCEPTION_REGISTRATION结构的handler域的值并调用它。令人奇怪的是,对异常处理回调函数的调用本身也被一个结构化异常处理程序封装着。在SEH自身中使用SEH看起来有点奇怪,但你思索一会儿就会理解其中的含义。如果在异常回调过程中引发了另外一个异常,操作系统需要知道这个情况。根据异常发生在最初的回调阶段还是展开回调阶段,ExecuteHandler或者返回DISPOSITION_NESTED_EXCEPTION,或者返回DISPOSITION_COLLIDED_UNWIND。这两者都是“红色警报!现在把一切都关掉!”类型的代码。
如果你像我一样,那不仅理解所有与SEH有关的函数非常困难,而且记住它们之间的调用关系也非常困难。为了帮助我自己记忆,我画了一个调用关系图(图十五)。
图十五 在SEH中是谁调用了谁
- KiUserExceptionDispatcher()
- RtlDispatchException()
- RtlpExecuteHandlerForException()
- ExecuteHandler() // 通常到 __except_handler3
- __except_handler3()
- scopetable filter-expression()
- __global_unwind2()
- RtlUnwind()
- RtlpExecuteHandlerForUnwind()
- scopetable __except block()
现在要问:在调用ExecuteHandler之前设置EDX寄存器的值有什么用呢?这非常简单。如果ExecuteHandler在调用用户安装的异常处理程序的过程中出现了什么错误,它就把EDX指向的代码作为原始的异常处理程序。它把EDX寄存器的值压入堆栈作为原始的 EXCEPTION_REGISTRATION结构的handler域。这基本上与我在MYSEH和MYSEH2中对原始的结构化异常处理的使用情况一样。
结论
结构化异常处理是Win32一个非常好的特性。多亏有了像Visual C++之类的编译器的支持层对它的封装,一般的程序员才能付出比较小的学习代价就能利用SEH所提供的便利。但是在操作系统层面上,事情远比Win32文档说的复杂。
不幸的是,由于人人都认为系统层面的SEH是一个非常困难的问题,因此至今这方面的资料都不多。在本文中,我已经向你指出了系统层面的SEH就是围绕着简单的回调在打转。如果你理解了回调的本质,在此基础上分层理解,系统层面的结构化异常处理也不是那么难掌握。
附录:关于 “prolog 和 epilog ”
在 Visual C++ 文档中,微软对 prolog 和 epilog 的解释是:“保护现场和恢复现场” 此附录摘自微软 MSDN 库,详细信息参见:
http://msdn.microsoft.com/en-us/library/tawsa7cb(VS.80).aspx(英文)
http://msdn.microsoft.com/zh-cn/library/tawsa7cb(VS.80).aspx(中文)
每个分配堆栈空间、调用其他函数、保存非易失寄存器或使用异常处理的函数必须具有 Prolog,Prolog 的地址限制在与各自的函数表项关联的展开数据中予以说明(请参见异常处理 (x64))。Prolog 将执行以下操作:必要时将参数寄存器保存在其内部地址中;将非易失寄存器推入堆栈;为局部变量和临时变量分配堆栈的固定部分;(可选)建立帧指针。关联的展开数据必须描述 Prolog 的操作,必须提供撤消 Prolog 代码的影响所需的信息。
如果堆栈中的固定分配超过一页(即大于 4096 字节),则该堆栈分配的范围可能超过一个虚拟内存页,因此在实际分配之前必须检查分配情况。为此,提供了一个特殊的例程,该例程可从 Prolog 调用,并且不会损坏任何参数寄存器。
保存非易失寄存器的首选方法是:在进行固定堆栈分配之前将这些寄存器移入堆栈。如果在保存非易失寄存器之前执行了固定堆栈分配,则很可能需要 32 位位移以便对保存的寄存器区域进行寻址(据说寄存器的压栈操作与移动操作一样快,并且在可预见的未来一段时间内都应该是这样,尽管压栈操作之间存在隐含的相关性)。可按任何顺序保存非易失寄存器。但是,在 Prolog 中第一次使用非易失寄存器时必须对其进行保存。
典型的 Prolog 代码可以为:
- mov [RSP + 8], RCX
- push R15
- push R14
- push R13
- sub RSP, fixed-allocation-size
- lea R13, 128[RSP]
- ...
此 Prolog 执行以下操作:将参数寄存器 RCX 存储在其标识位置;保存非易失寄存器 R13、R14、R15;分配堆栈帧的固定部分;建立帧指针,该指针将 128 字节地址指向固定分配区域。使用偏移量以后,便可以通过单字节偏移量对多个固定分配区域进行寻址。
如果固定分配大小大于或等于一页内存,则在修改 RSP 之前必须调用 helper 函数。此 __chkstk helper 函数负责探测待分配的堆栈范围,以确保对堆栈进行正确的扩展。在这种情况下,前面的 Prolog 示例应变为:
- mov [RSP + 8], RCX
- push R15
- push R14
- push R13
- mov RAX, fixed-allocation-size
- call __chkstk
- sub RSP, RAX
- lea R13, 128[RSP]
- ..
.除了 R10、R11 和条件代码以外,此 __chkstk helper 函数不会修改任何寄存器。特别是,此函数将返回未更改的 RAX,并且不会修改所有非易失寄存器和参数传递寄存器。
Epilog 代码位于函数的每个出口。通常只有一个 Prolog,但可以有多个 Epilog。Epilog 代码执行以下操作:必要时将堆栈修整为其固定分配大小;释放固定堆栈分配;从堆栈中弹出非易失寄存器的保存值以还原这些寄存器;返回。
对于展开代码,Epilog 代码必须遵守一组严格的规则,以便通过异常和中断进行可靠的展开。这样可以减少所需的展开数据量,因为描述每个 Epilog 不需要额外数据。通过向前扫描整个代码流以标识 Epilog,展开代码可以确定 Epilog 正在执行。
如果函数中没有使用任何帧指针,则 Epilog 必须首先释放堆栈的固定部分,弹出非易失寄存器,然后将控制返回调用函数。例如:
- add RSP, fixed-allocation-size
- pop R13
- pop R14
- pop R15
- ret
如果函数中使用了帧指针,则在执行 Epilog 之前必须将堆栈修整为其固定分配。这在技术上不属于 Epilog。例如,下面的 Epilog 可用于撤消前面使用的 Prolog:
- lea RSP, -128[R13]
- ; epilogue proper starts here
- add RSP, fixed-allocation-size
- pop R13
- pop R14
- pop R15
- ret
在实际应用中,使用帧指针时,没有必要分两个步骤调整 RSP,因此应改用以下 Epilog:
- lea RSP, fixed-allocation-size – 128[R13]
- pop R13
- pop R14
- pop R15
- ret
以上是 Epilog 的唯一合法形式。它必须由 add RSP,constant 或 lea RSP,constant[FPReg] 组成,后跟一系列零或多个 8 字节寄存器 pop、一个 return 或一个 jmp。(Epilog 中只允许 jmp 语句的子集。仅限于具有 ModRM 内存引用的 jmp 类,其中 ModRM mod 字段值为 00。在 ModRM mod 字段值为 01 或 10 的 Epilog 中禁止使用 jmp。有关允许使用的 ModRM 引用的更多信息,请参见“AMD x86-64 Architecture Programmer’s Manual Volume 3: General Purpose and System Instructions”(AMD x86-64 结构程序员手册第 3 卷:通用指令和系统指令)中的表 A-15。)不能出现其他代码。特别是,不能在 Epilog 内进行调度,包括加载返回值。
请注意,未使用帧指针时,Epilog 必须使用 add RSP,constant 释放堆栈的固定部分,而不能使用 lea RSP,constant[RSP]。由于此限制,在搜索 Epilog 时展开代码具有较少的识别模式。
通过遵守这些规则,展开代码便可以确定某个 Epilog 当前正在执行,并可以模拟该 Epilog 其余部分的执行,从而允许重新创建调用函数的上下文。
本文由 VCKBASE MTT 翻译