JPEM压缩原理
本文介绍JPEG压缩技术的原理,对于DCT变换、Zig-Zag扫描和Huffman编码,给出一个较为清晰的框架。
1. JPEG压缩的编解码互逆过程:
- 编码

- 解码

2. 具体过程:(这里仅以编码为例,解码过程为其逆过程)
A. 将原始图像分为8*8的小块, 每个block里有64pixels:
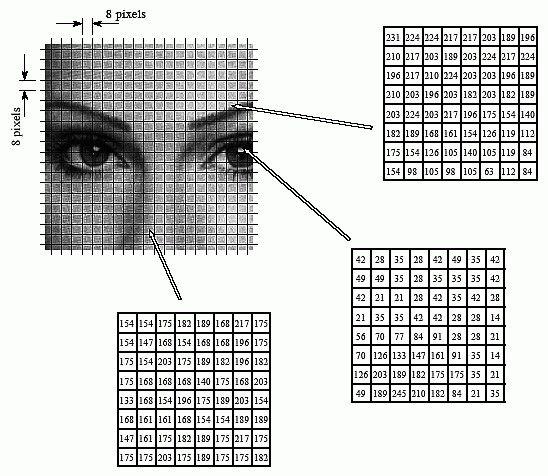
B. 将图像中每个8*8的block进行DCT变换:
数据压缩中有很多变换,比如KLT(Karhunen-Loeve Transform),这里我们用的是DCT离散余弦变换。和FFT一样,DCT也是将信号从时域到频域的变换,不同的是DCT中变换结果没有复数,全是实数。每8*8个original pixels都变成了另外8*8个数字,变换后的每一个数都是由original 64 data通过basis function组合而得的,如下图所示为DCT谱中6个元素的由来。
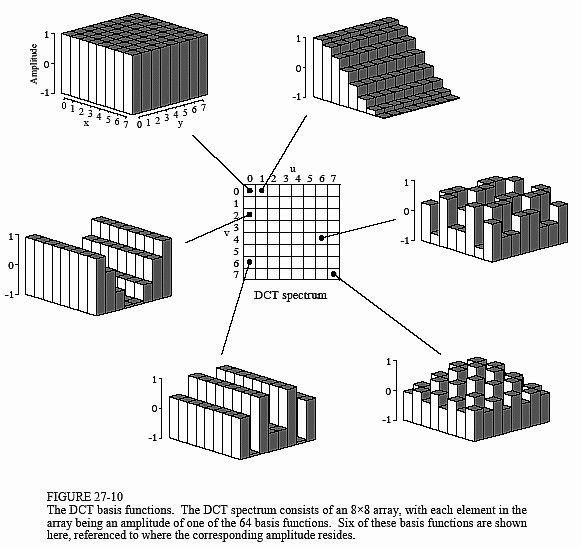
将低频部分集中在每个8*8块的左上角,高频部分在右下角,所谓JPEG的有损压缩,损的是量化过程中的高频部分。为什么呢?因为有这样一个前提:低频部分比高频部分要重要得多,romove 50%的高频信息可能对于编码信息只损失了5%。

C. 量化:
所谓量化就是用像素值÷量化表对应值所得的结果。由于量化表左上角的值较小,右上角的值较大,这样就起到了保持低频分量,抑制高频分量的目的。JPEG使用的颜色是YUV格式。我们提到过,Y分量代表了亮度信息,UV分量代表了色差信息。相比而言,Y分量更重要一些。我们可以对Y采用细量化,对UV采用粗量化,可进一步提高压缩比。所以上面所说的量化表通常有两张,一张是针对Y的;一张是针对UV的。
通过量化可以reducing the number of bits and eliminating some of the components,达到通低频减高频的效果,如下图所示就是两张量化表的例子.

比如左边那个量化表,最右下角的高频÷16,这样原先DCT后[-127,127]的范围就变成了[-7,7],固然减少了码字(从8位减至4位)。
D. 编码分类:
编码信息分两类,一类是每个8*8格子F中的[0,0]位置上元素,这是DC(直流分量),代表8*8个子块的平均值,JPEG中对F[0,0]单独编码,由于两个相邻的8×8子块的DC系数相差很小,所以对它们采用差分编码DPCM,可以提高压缩比,也就是说对相邻的子块DC系数的差值进行编码。
另一类是8×8块的其它63个子块,即交流(AC)系数,采用行程编码(游程编码Run-length encode,RLE)。这里出现一个问题:这63个系数应该按照怎么样的顺序排列?为了保证低频分量先出现,高频分量后出现,以增加行程中连续“0”的个数,这63个元素采用了“之”字型(Zig-Zag)的排列方法,如下图所示。

E. 编码格式:
上面,我们得到了DC码字和 AC行程码字。为了进一步提高压缩比,需要对RLE编码结果再进行熵编码,这里选用Huffman编码。Huffman编码具体不讲啦,详细地看我以前的这篇Huffman编码——原理与实现吧。
Reference:
1. http://jilie0226.blog.163.com/blog/static/36792254200902072746964/
2. http://www.stat.ncsu.edu/people/martin/courses/st783/JPEG%20(Transform%20compression).htm
3. http://fourier.eng.hmc.edu/e161/lectures/klt/node3.html
4. http://tomjark.blog.163.com/blog/static/14600788201010137309298/
5. http://blog.chinaunix.net/uid-24517893-id-3074462.html