海量数据挖掘MMDS week2: Nearest-Neighbor Learning最近邻学习
http://blog.csdn.net/pipisorry/article/details/48894963
海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses学习笔记之Nearest-Neighbor Learning,KNN最近邻学习
{The module is about large scale machine learning.}
Supervised Learning监督学习

Note: y有多种不同的形式,对应不同的问题。如为实数时,属于回归问题。
下面我们主要讲解分类问题
大规模机器学习方法

how do we efficiently train?Or build a model based on the based on the data?
So in a sense the main question is how do I find this function f.That takes the input features and predicts the class variable.
皮皮blog
Instance based learning基于实例的学习
最近邻分类器Nearest nerghbor

最近邻分类器要考虑的问题

Note: 最后一个要考虑的问题就是:How to take all these nearest neighbors and combine their values into a single point that I can use as prediction.
1-Nearest Nerghbor

1-Nearest nerghbor的重大缺陷:预测值附近变化大,用一个值来预测不准确。the method is suffering from It is making lots of very spiky, or sharp decisions, because we are only looking at the one nearest neighbor.
K-Nearest Nerghbor

Note: f(x) is much smoother than what is was before.
Kernel Regression核回归
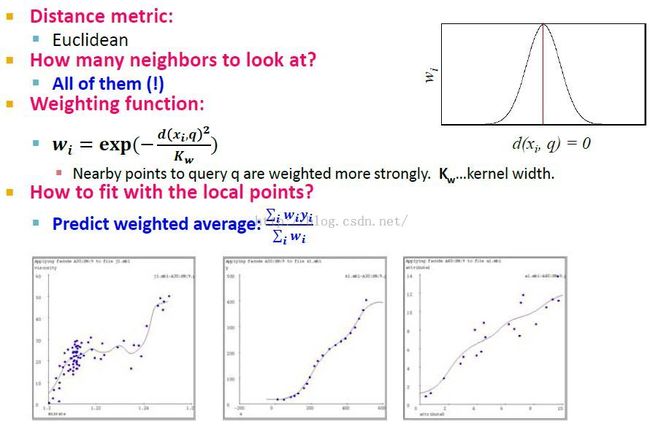
皮皮blog
寻找最近邻的方法

一般扫描数据点方法的时间复杂度:线性时间
solution would require a linear pass over the data, so it would take linear time.
使用LSH的时间复杂度:常数时间(可用于大规模数据)
using locality sensitive hashing, we could find, nearest neighbors in near constant time.So that would be a good way how to really make nearest neighbor classifiers scale to large scale data.
具体是怎么实现的?
from:http://blog.csdn.net/pipisorry/article/details/48894963
ref:论文:GPU上的K近邻并行暴力搜索Brute-Force k-Nearest Neighbors Search on the GPU