日志系统之HBase日志存储设计优化
本人博客文章如未特别注明皆为原创!如有转载请注明出处:http://blog.csdn.net/yanghua_kobe/article/details/46482319
继续谈论最近接手的日志系统,上篇关于日志收集相关的内容,这篇我们谈谈日志存储相关的话题。
简介
我们首先来总结一下日志这种数据的业务特点:它几乎没有更新的需求,一个组件或一个系统通常有一个固定的日志格式,但就多个组件或系统而言它会存在各种五花八门的自定义的tag,这些tag建立的目的通常是为了后期查询/排查线上问题的需要,因此日志的检索字段也灵活多变。
我们的日志存储选择是HBase,这主要是因为我们认为HBase的如下特点非常适合日志数据:
(1)HBase的qualifier相当灵活,可以动态创建,非常适合日志这种tag不固定的半结构化数据(这里的灵活性主要针对tag的存储)
(2)HBase归属于Hadoop生态体系,方便后面做离线分析、数据挖掘
结合上面我们提到的日志数据的特点,由于tag灵活多变,因此对基于tag的查询HBase显得有些力不从心。这主要是因为HBase本身并不提供二级索引,你无法基于Column进行搜索。如果无法确定rowKey或rowKey的范围并且也没有辅助索引,那么将不得不进行全表扫描。从这一点上来看,你可以将其看作是一个Key-Value形式的数据库(比如redis)。
基于HBase自建索引的缺陷
索引的设计
因为HBase自身不提供二级索引机制,所以很常见的做法是在外部自己构建索引,我在接手日志系统时的实现就是这么做的。基本思路是日志存储在日志表,人为构建基于tag的索引信息存入索引元数据表,元数据表中一条索引信息对应一个索引表,在索引表中利用Column-Family的横向扩展来存储日志的rowKey。总结如下:
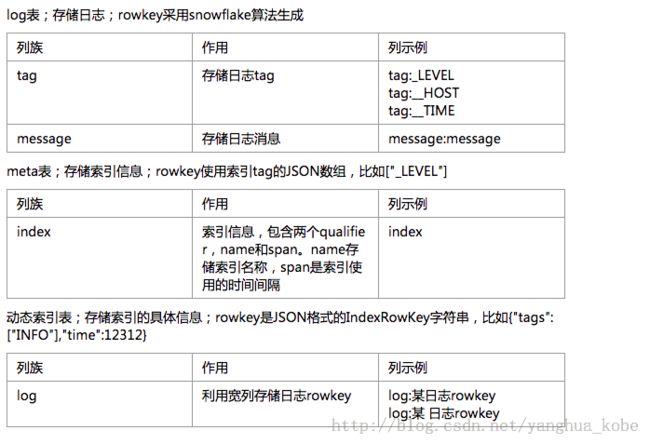
(1)log表:存储日志记录
(2)meta表:存储索引元数据(其中包含动态索引表的表名称)
(3)动态index表:存储索引的具体信息,一个索引对应一张表
下面我们来看一下这几张表的Schema设计:
这里我可以谈谈原先建立动态索引表的大致逻辑,它需要三个参数:
(1)indexName:索引名称
(2)tags:需要为其建立索引的tag数组
(3)span:时间间隔
先将tags数组转换为(fast-json#toJSONBytes)byte[]并将其作为rowKey,在meta表中检查是否已存在为该tag组合构建的索引名。(HBase识别的rowKey格式是byte[]形式的,meta表的rowKey即为tags的json数组序列化为byte[]后的表示形式)。
如果该索引的元数据不存在,则创建动态索引表,该索引表的表名为indexName。
而索引表的rowKey对象的设计包含了两个属性:
(1)time:日志的“准”记录时间,注意此处不是真实的记录时间,而是间接真实事件的一个时间点(timestamp / span *span)
(2)tags:tag的字符串数组
然后对log(日志表)进行全表扫描,对每一条日志记录进行如下操作:
(1)获取日志产生的时间
(2)然后内部存在一个遍历tags的循环,对每一个tag:判断该条日志是否存在该tag,如果不存在则直接跳出该循环,如果tag都能匹配上tags里的每一条,则才为其建立索引
(3)如果需要建立索引,则往索引表内添加一条数据
总得来说,这里建立的索引就是匹配tags集合以及时间分片,将满足条件的日志向最靠近它的时间点聚拢。
索引设计存在的问题
(1)索引表的建立效率很低,需要一个两层的嵌套循环,最外层做的事情是全表扫描,如果数据量庞大后,这种处理方式很难被接受。其实,这种方式类似于数据已在,事后补偿的机制。而通常的做法是:索引表建立时只是个空表,数据入库时动态分析其是否有必要构建索引(这句的后半句原来也有实现,是通过storm实现的)
(2)通过索引进行查找的时候,还需要两层循环,外层是查找动态索引表里的行集合,内层是获取列簇里所有的日志表里相关记录的rowKey。如果查询的时间范围比较长或者时间分片的间隔比较端,那么时间点会非常多,而时间点一多,外层循环次数将会非常多,因此为了避免这一点,实现时做了时间片段限制,也就是片段不能大于一定的范围;如果该时间片的日志非常密集,那么这些日志就都会落到该时间点上,那么内层循环次数将会非常多。
(3)查询的效率将非常依赖于索引建立的健全程度,这种情况下建立索引的tag集合必须小而全,如果大而广,那么构建索引的条件匹配度就会变低。如果没有针对要查询的tag的索引信息,将不得不进行全表扫描。
(4)日志表ID采用的是分布式自增ID,其他表用的是json对象的字符串形式,没有注意rowKey对HBase查询的重要性。
HBase存储日志的查询优化
HBase查询的基础概念
产生这些问题的原因是自建索引的实现方式,我们必须对日志系统的查询进行优化,在此之前我们首先要对HBase的查询有一些基本的了解。访问HBase的行记录有以下三种方式:
(1)通过rowKey作唯一匹配
(2)通过rowKey的range匹配一个范围,然后通过多种filter在范围内筛选
(3)全表扫描
从编程角度来看,HBase的查询实现只支持两种方式:
(1)get:指定rowkey获取唯一一条记录
(2)scan:按指定的条件获得一批记录(它包含了上面的2,3两种方式)
通常情况下,全表扫描很少是我们期望的做法。因此我们如果我们想提升查询效率,必须精心设计rowKey。
从上面自建索引产生的问题以及我们对HBase查询的基本了解。问题主要有两个方面:
(1)自建索引的实现方式不够高效
(2)没有对rowKey进行良好的设计(日志记录的ID采用分布式自增ID)
下面我们针对这两点来谈谈优化策略。
rowKey的优化
rowKey在这里绝对不能像传统的RDBMS处理主键那样,简单地用UUID或自增ID来处理。HBase的rowKey是基于字典排序的,具体来说是基于key的ASCII码来排序,我们的思路是要往rowKey中加入我们想要查询的条件因子,通过多个因子相互组合,来一步步确定查找范围。比如时间肯定是我们应该加到rowKey里的一个查询因子,一个开始时间跟一个截止时间就形成了一个时间段范围,就能固定一个结果集范围。
你很容易看出来rowkey里加入的查询因子越多,查询范围定位的精确度越高。但查询因子其实是从众多日志中抽象而来(比如host,level,timestamp等),这要求它们是每条日志记录中共性的东西,就我们目前的日志系统而言,大致划分为两种日志类型:
(1)定格式的业务系统/框架日志(比如业务框架/web app等)
(2)不定格式的技术系统/组件/框架日志(比如nginx、redis、RabbitMQ等)
针对定格式的日志,我们的rowKey的规则是:

针对不定格式的日志,我们的rowKey规则是:

因为各种技术组件的日志格式多样,导致我们无法从中解析出时间,所以这里我们选择日志的收集时间作为鉴别时间戳。这里我们只能假设:整个日志系统一直都良好运转,也就是说日志产生时间给收集时间相近。但毫无疑问这样的假设有时是不准确的,但我们不会以真实的时间作为基准,因为这种类型的日志是通过离线批处理进行解析后重新转存的,因此最终还是会得出精确的日志时间戳。
rowkey最好被设计为定长的,而且最好将rowkey的每个分段都转化成纯数字或纯字母这种很容易转化为ASCII码并且容易人为设置最大值与最小值的形式。举例来说:假如前面几位都固定,最后三位是不定的,如果是数字,那么区间的范围会在XXXXX000-XXXXX999之间。
通常我们想加入rowKey的查询因子,其值不为数字或者字母是很正常的,这时我们可以通过码表来映射,比如上面我们针对AppLog的logLevel因子就是通过码表来进行映射的,目前我们用两位数来映射可能存在的level。
筛选器-filter
在通过rowKey的范围确定对结果集的扫描范围之后,下一步就是通过内置的filter来进行更精确的筛选,HBase默认提供多种filter供使用者针对rowKey、column-family、qualifier等进行筛选。当然如果rowKey的筛选条件取值跨度比较大,还会产生接近类似于全表扫描的影响。我们能做的事情就只剩下对查询条件进行限制了,比如:
(1)查询时间区间的跨度只能限制在一定的范围
(2)分页给出查询结果
再谈自建索引
既然索引是优化查询非常关键的一环,所以建索引的思路是没有问题的。但是,无论如何自建索引还是需要精心设计rowKey,不管是数据表的rowKey还是索引表的rowKey。有时为了查询效率,甚至会固定某段rowKey的前几位,并让其代表的数据落在同一个region中。精心设计rowKey的原因,还是因为HBase的查询特征:你获得的rowKey范围越精确,查找的速度越快。
协处理器-coprocessor
通常情况下,索引表建立时不应该进行全表扫描,但我们应该对日志表的每条数据进行处理来生成最终的索引数据。在我们现在的系统中,是通过storm进行分析、插入的。这里我们上storm的目的也不是为了做这件事,最主要的目的是实时过去logLevel为Error的日志,并做到准实时通知。那么问题来了,如果我们不存在这个需求,我们是不是为了要计算索引而要上一个storm集群?答案是:大可不必。
其实这里主要是在往HBase里插入数据时,获得一个hock(钩子)或者说callback来拦截每条数据,分析是否应该将其rowKey加入索引表中去。HBase在0.92版本之后提供了一个称之为协处理器(coprocessor)的技术,允许里编写运行在HBase Server上的代码拦截数据,协处理器大致分为两类:
(1)Observer(类比于RDBMS中的触发器)
(2)EndPoint(类比于RDBMS中的存储过程)
我们可以通过Observer来拦截日志记录,并加入代码处理逻辑来为其构建索引。由于介绍HBase技术细节不是本文的重点,所以这里就提及一下,如果后面有机会,再来继续探讨。
回到自建索引这个话题,上面谈及了自建索引依赖的技术点,下面推荐一个自建索引的设计思路。这里有一篇不错的文章,通过巧妙地设计索引表的rowKey来满足多条件查询的需求。这是一个二级多列索引的设计。通过对多个查询条件键以及条件值映射到rowKey来缩小索引表的rowKey区间到最后确定唯一目标rowKey,并从cell里获得数据表的rowKey。但这样的索引设计,依赖于表结构已知且前提条件固定。很明显,日志表中存在各种无法预知的tag,没有办法参照这样的索引设计。而这样的场景最好通过一些专门针对全文检索的搜索引擎来建立索引。
第三方专业索引机制
从上面的讨论可以看出,近似于全文检索的需求在表中的数据非常多的情况下,HBase很难实现非常高效的索引。这时我们可以借助于全文检索引擎提供的索引的能力来给HBase的rowKey建立索引,而HBase只负责存储基础数据。业界已经有很多基于此思路(索引+存储)的实践总结。这里,全文索引的选择可以是Solr,或者是更适用于日志搜索的ElasticSearch(它自身也具备存储机制)。解决方案可参照这个Slide。
这里有一张整体架构模式图:
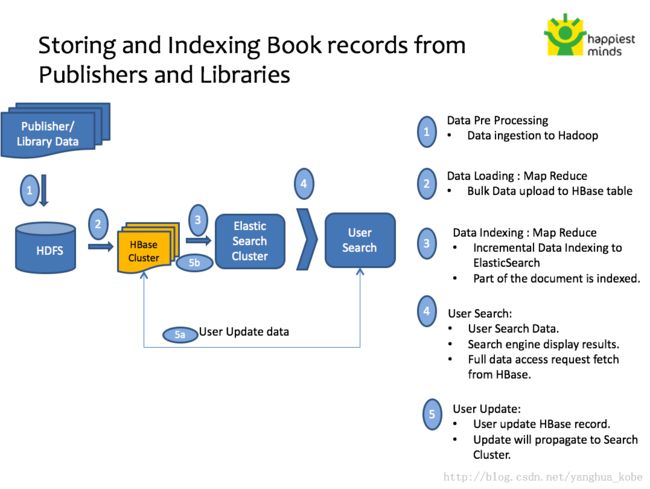
如果有时间和机会,后面我会谈谈ElasticSearch+HBase组合的日志全文检索实践。