【Java】利用Ansj中文分词工具对段落进行切词
对于切词确实是一个复杂的功能,足以写上好几篇论文,但是如果仅仅想对一个句子、一个段落、一篇文章进行切词,可以利用中国自然语言开源组织中各位大牛写好的工具。已经打包成jar包,可以直接调用了,无须自己再考虑复杂的算法。
当然这种切词是对于自然语言的,对于一些有规律的字符串,请自行利用indexOf、substring、split的各类Java自带函数,没有使用额外java包的必要。
首先假如有如下的一个节选自梁启超《最苦与最乐》段落:
人生若能永远像两三岁小孩,本来没有责任,那就本来没有苦。到了长成,责任自然压在你的肩头上,如何能躲?不过有大小的分别罢了。尽得大的责任,就得大快乐;尽得小的责任,就得小快乐。你若是要躲,倒是自投苦海,永远不能解除了。
要对其进行词语的分割成以下形式:

划分成中文,并且标识各个词语的词性,做法如下:
1、先到http://maven.ansj.org/org/ansj/ansj_seg/下载最新版ansj_seg.jar,建议使用2.0x以上的版本,再到http://maven.ansj.org/org/nlpcn/nlp-lang/下载其辅助包nlp-lang.jar,如果是使用1.0x版本的ansj_seg.jar,则到http://maven.ansj.org/org/ansj/tree_split/下载1.0x的辅助包tree_split.jar。下载之后,在Eclipse新建java工程文件夹下,新建一个lib文件夹,并且把ansj_seg-2.0.8.jar与nlp-lang-1.0.jar扔过去,在Eclipse刷新,右击相应工程,选择属性,Java Build Path把两个jar添加到工程当中。

2、之后,到https://github.com/NLPchina/ansj_seg下载其切词字典,
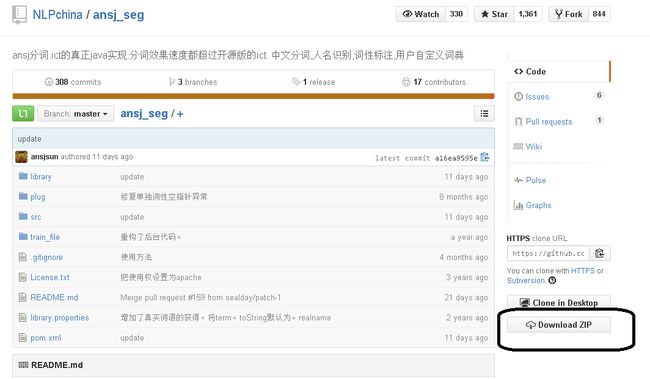
下载之后解压,将其library文件夹扔到你Java工程的根目录,再把library.properties扔到Java工程的bin目录。
3、之后,新建一个WordSegment.java写入如下代码,编译运行,则得到结果:
import java.util.List;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
public class WordSegmentTest {
public static void main(String[] args) {
String str = "人生若能永远像两三岁小孩,本来没有责任,那就本来没有苦。到了长成,责任自然压在你的肩头上,如何能躲?不过有大小的分别罢了。尽得大的责任,就得大快乐;尽得小的责任,就得小快乐。你若是要躲,倒是自投苦海,永远不能解除了。";
List<Term> term = ToAnalysis.parse(str);
for (int i = 0; i < term.size(); i++) {
String words = term.get(i).getName();// 获取单词
String nominal = term.get(i).getNatureStr();// 获取词性
System.out.print(words + "\t" + nominal + "\n");
}
}
}
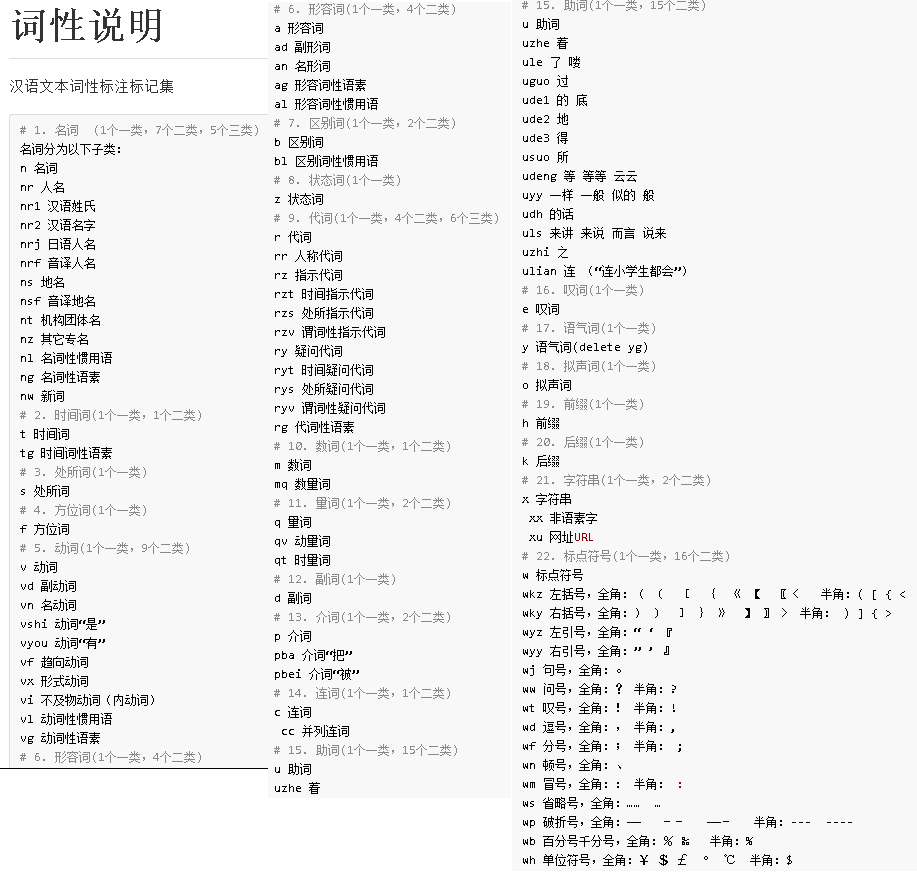
其中str是要被切割的中文自然语言段落,切割后的结果是一个存放Term对象的List,对这个List进行遍历,可以利用getName()获取切割的单词,利用getNatureStr()获取到词性。其中词性表如下:点击打开链接